Около семи лет назад Dan North в своей статье описал практическое применение BDD подхода, который позволяет сделать процесс разработки более понятным и управляемым путем налаживания внутренних коммуникаций. Индустрия с каждым днем проявляет всё больший интерес к этой методологии, нацеленной на продуктивное взаимодействие стандартных команд типа «аналитика-разработка-тестирование».
Однако, сейчас лишь малая часть компаний решается на использование BDD. Почему?
Итак, давайте разберемся. BDD (Behaviour Driven Development — «Разработка через поведение») — гибкая методология, тесно связанная с TDD (Test Driven Development — «Разработка через тестирование»). По опыту, даже матерые тестировщики зачастую не видят разницы между этими методологиями. Действительно, на первый взгляд ее трудно вычленить: оба подхода предполагают написание документации и тестов до старта этапа разработки. А различие вот в чем: в BDD для описания тестов требуется использование естественного языка, понятного каждому участнику проекта, чтобы, фактически, объединить постановку задачи, тесты и документацию воедино. Другими словами, определяется DSL (специфичный предметно-ориентированный язык), потом составляется стандартный ограниченный набор фраз, описывающих поведение нужных элементов. Затем с их помощью разрабатывается сценарий использования новой функциональности, который будет понятен всем.
Давайте один раз увидим разницу, и она станет очевидной:
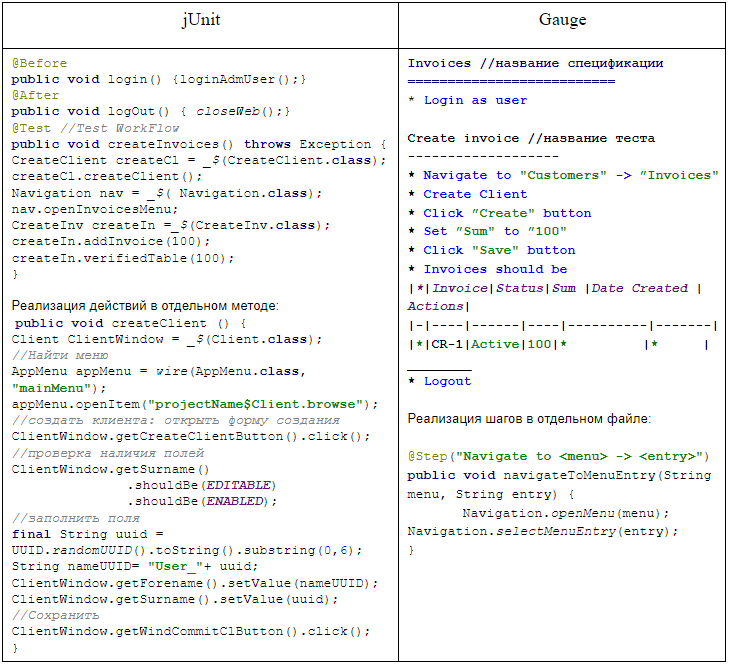
Мы еще коснемся этого примера, а для начала давайте посмотрим на все разнообразие методологий, которые на данный момент имеют ненулевую актуальность.
Сравним несколько методологий
Диаграмма ниже показывает сравнение трех подходов: TDD, TLD (Test Last Development) и BDD:
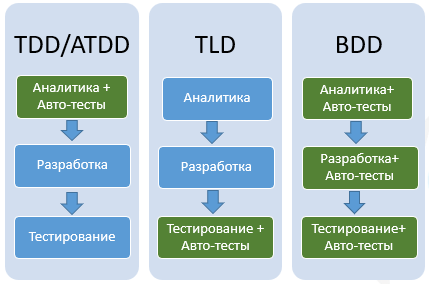
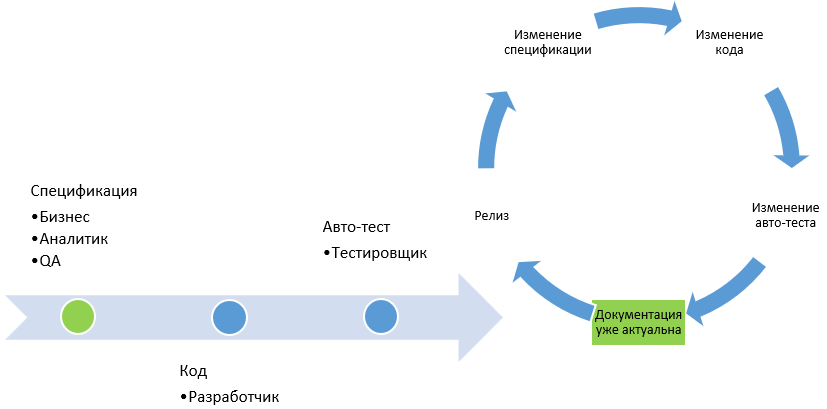
- Когда мы работаем по методологии BDD, автотестирование и составление спецификации сопровождает каждый этап цикла разработки ПО, что обеспечивает постоянную актуальность автотестов и документации.
- Методологии TDD и ATDD (Acceptance Testing) объединены на диаграмме в один блок, т.к. пишутся на этапе аналитики. Как уже было сказано выше, TDD основан на написании тестов до разработки функционала. Разработчик должен написать тесты для того, чтобы написать функционал под тест.
- TLD (Test Last Development) включает тестирование после реализации функционала.
- BDD универсален и может включаться на любом этапе разработки.
На второй диаграмме изображено вовлечение участников процесса разработки в написание сценариев.
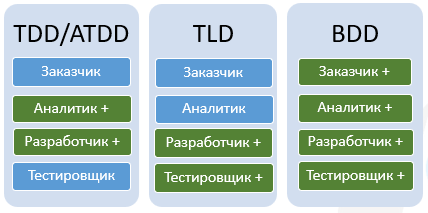
- В BDD к тестам на любом этапе может подключиться любой член команды, например, аналитик, бизнес пользователь, разработчик и тестировщик, так как тесты понятны всем участникам процесса.
- BDD еще полезен тем, что не нужно тратить много времени на написание разного рода документации. При классической схеме разработки нужны, как минимум, спецификации и тестовые сценарии, которые обычно пишут разные люди. В BDD спецификация является тестовым сценарием, одновременно являясь и автотестом. Тестировщикам не нужно писать отдельную тестовую документацию — за них это уже сделал аналитик, написавший спецификацию из конструкций естественного языка (которая читаема и понятна любому члену команды).
Несомненно, BDD — это хороший инструмент, позволяющий достичь качества продукта. Тесты и документация пишутся быстрее. Для бизнеса проект становится более прозрачным, благодаря конструкциям естественного языка, понятным любому человеку, далекому от программирования.
Это о плюсах. Тем не менее, как уже было сказано, несмотря на большое количество плюсов, мало кто эту методологию внедряет.
BDD всем хорош, но почему его не используют?
Ответ прост: это долго и дорого. С этим утверждением согласятся большинство IT компаний. И поначалу мы не были исключением. BDD неудобен хотя бы тем, что требует привлечения специалистов тестирования уже на этапе проработки требований.
BDD переворачивает с ног на голову классическую схему ведения разработки (TLD). Она плохо реализуема, потому что это сложно. Удлиняется цикл разработки.
BDD — это несомненно способ достичь качества. Но не все готовы платить временем и специалистами за это качество.
Однако, что делать, если BDD все же хочется внедрить?
Можно попробовать использовать готовые фреймворки. Например Cucumber, Squish, Yulup.
Основная проблема сложности BDD не в процессе, а в реализации и существующих инструментах. Возьмем в качестве примера WEB разработку корпоративной информационной системы. Имея web реализацию мы сталкиваемся с WebDriver’ом являющимся в данный момент стандартом при автоматизации приложений, работающих в веб браузере. Он обладает довольно большими возможностями. Для учитывания различных кастомизаций элементов страницы необходимо придумывать варианты обращения к ним. И тут для облегчения разработки теста на помощь приходят различные библиотеки (Selenide, и др.), что создает свою экосистему, которую нужно знать. Для работы с WebDriver нужен программист либо тестировщик-автоматизатор, т.к. все реализуется с помощью кода и хитрых конструкций.
Начало работы с BDD фреймворком — сложно и долго
Наше внимание остановилось на инструменте под названием Gauge. Это гибкий и легковесный фреймворк, распространяющийся по свободной лицензии. Признаться честно, мы не особо изучали альтернативы, т.к. использование Gauge было настойчиво продиктовано нашим заказчиком.
В Gauge тесты пишутся в файлах спецификаций (файлы с расширением .spec). Спецификация содержит шаги теста, написанные на естественном языке. Эти шаги имплементируются на каком-либо языке программирования (у нас был использован язык программирования Java). При имплементации шагов важно соблюдение Naming Convention как в именах файлов сценария и реализации, так и в именах методов реализации и шагов сценария, они должны полностью совпадать. Дополнительную гибкость этому инструменту даёт то, что шаги могут иметь параметры.
Gauge позволил нам использовать плюсы BDD. Однако мы все равно столкнулись с проблемами, которые заключаются в сложности реализации: проблемы инструментария и внедрения процесса.
Оказалось, что привлечение тестировщиков на раннем этапе плохо сказывается на конечном результате. Увеличивается время на разработку тестов. При использовании любого фреймворка требуются большие усилия тестировщика, который, несомненно, хорошо должен владеть и программированием. Поначалу процесс работы со сценарием был следующим: аналитик рассказывал тест тестировщику, а записывал его технический писатель. Пока тестировщик разбирался с программной реализацией, изменялся смысл тестируемой функциональности. Тут сказывается разделение точки входа, а она должна быть одна, по итогу процесс разделяется и превращается в “обычный” процесс, от которого как раз и хотелось уйти. Т.е. точка входа разделилась, коммуникации расползлись, тестировщик ушел с головой в имплементацию теста, технический писатель понял как-то по своему, а аналитик уже и свои доки переписал и передумал, разработчик же вообще ушел в “свой мир” ).
Много времени у тестировщика уходило на код. А ведь еще тот же тестировщик должен был продумать поиск элементов на странице. Ситуация напоминала известную детскую игру: “Испорченный телефон”. Возникал коллапс. И мы решили: BDD будет работать только в том случае, если тесты смогут писать аналитики. Нужно снизить трудоемкость написания тестов, упростить их. Но для этого нужно существенно упрощать интерфейсы тестирования. Инструменты тестирования, реализация процесса в совокупности со всеми подходами и библиотеками должны быть проще.
Работа тестировщика вначале выглядела следующим образом:
- Изучение документации, если она есть;
- Составление чеклиста;
- Ad-hoc тестирование;
- Составление тест плана;
- Уточнение картины мира у аналитика;
- Уточнение картины мира у разработчика;
- Если все срослось, написание тестовой документации, параллельно с тестированием;
- Ожидание фикса багов, тестирование багов;
- Описание страниц, контролов, поиск элементов на странице используя Web-Driver. Поиск того что уже реализовано в системе тестов;
- Написание логики теста;
- Релиз;
- Support bug/Regress bug;
- Обновление спецификации;
- Фикс бага;
- Обновление автотеста, обновление большого количества изменившихся контролов;
- Релиз;
- …
Пункты, выделенные курсивом, (1, 5, 6, 7, 9, 13, 15) приводят к временным затратам. Их можно и нужно оптимизировать.
Этот список кратко проиллюстрирован на диаграмме процесса разработки:
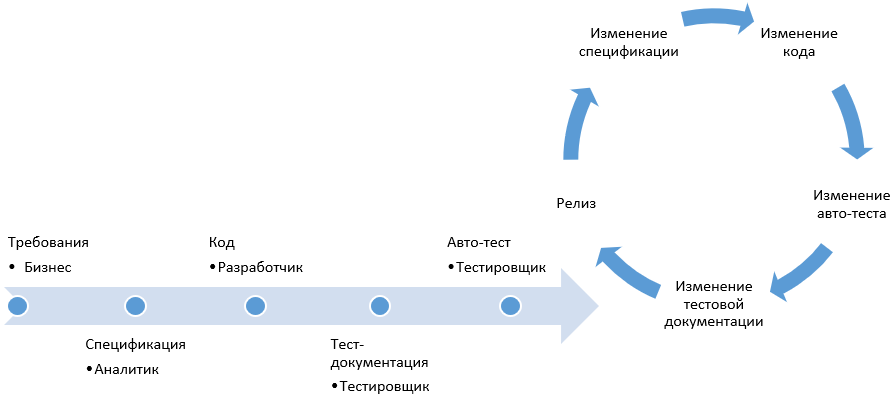
Наша компания специализируется на проектах с веб реализацией интерфейсов. Исходя из этого, мы используем инструмент Web Driver для взаимодействия с веб браузером.
Де-факто, Selenium Web Driver является стандартом, и он используется для описания веб объектов на любых фреймворках, в том числе Gauge, jUnit, библиотек Masquerade и других. Гибкости у него много для разных задач, что создает излишнюю трудоемкость в локально-типовых задачах. Нам нужно найти решение для уменьшения трудоемкости.
Для примера покажем на схеме — как связаны Selenium Web Driver, фреймворк Gauge, библиотека Masquerade, язык программирования Java.
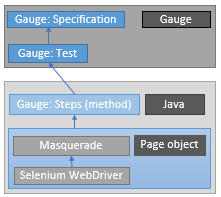
В этой схеме можно вместо BDD фреймворка поставить jUnit, TestNG или любой другой, любая связка будет работать, в зависимости от потребностей. Selenium и Masquerade останется, язык программирования можно изменить.
Ускорение процесса написания кода — подключение Masquerade
В нашей компании разработка ведется на платформе CUBA. И специально для этой платформы был разработан инструмент для автотестов: Masquerade — библиотека, которая предоставляет лаконичный и удобный API для работы с кодом при имплементации тестов с использованием WebDriver. Эта библиотека работает над Selenium Web Driver, дружит с selenide и любыми фреймворками.
В CUBA проектах каждый элемент веб страницы содержит cuba-id, который не меняется. В CUBA используется компонентный подход, а библиотека Masquerade упрощает взаимодействие с элементами веб страницы. Библиотека умеет совершать действия с элементами веб страницы, реализованными с помощью CUBA, более простым образом. Поэтому при поиске элементов на странице не нужно использовать громоздкие конструкции с XPath, как было раньше:
$(new By.ByXPath("//*/div/div[2]/div/div[2]/div/div/div[3]/div/div/div[3).click();Или более лаконичные конструкции на Java, которые, тем не менее, по-прежнему громоздки:
private static void click(String cssClass, String caption) {
$(By.cssSelector(cssClass)
.$(byText(caption))
.closest(".v-button")
.click();
}После подключения библиотеки Masquerade описание вложенного контрола выглядит просто и к нему легко обратиться. Можно даже не искать контрол на странице, т.к. в проекте он уже есть. Приведем пример описания кнопки для формы авторизации в приложении:
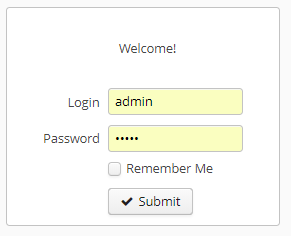
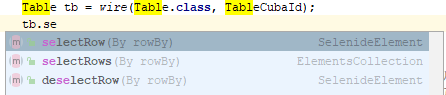
В коде страницы нам виден четко узнаваемый элемент cuba-id=”loginButton”

Опишем кнопку, используя библиотеку Masquerade:
@Wire(path = {"WebHBoxLayout", "loginButton"})
private Button loginButton;Простой вариант реализации теста на фреймворке jUnit — блок авторизации, который выполняется перед каждым тестом:
@Before
public void loginAdm() {
Tests loginTest = _$(Tests.class);
loginTest.login();
}А в теле метода login следующий код:
LoginWindow loginWindow = _$(LoginWindow.class);
assertNotNull(loginWindow.getLoginField());
loginWindow.getLoginField()
.shouldBe(EDITABLE)
.shouldBe(ENABLED);
loginWindow.loginField.setValue("admin");
loginWindow.passwordField.setValue("admin");
loginWindow.rememberMeCheckBox.setChecked(true);
loginWindow.loginButton().click();При этом самое важное — то, как мы описываем страницу, как мы обращаемся к элементам. Описание страницы LoginWindow:
public class LoginWindow extends Composite<LoginWindow> {
@Wire(path = {"loginField"} )
private TextField loginField;
@Wire(path = {"passwordField"} )
private PasswordField passwordField;
@Wire(path = {"rememberMeCheckBox"} )
private CheckBox rememberMeCheckBox;
@Wire(path = {"loginFormLayout", "loginButton"} )
private Button loginButton;
}Поиск элементов — это лишь часть возможностей библиотеки Masquerade. Обращение к элементам веб страницы позволяет совершать различные действия с этими элементами. Например, можно выбрать элемент из выпадающего списка:
getMaxResultsLayout().openOptionsPopup().select("5000")Или отсортировать таблицу:
Table tb1 = client.getPaymentsTable();
tb1.sort("column_year", Table.SortDirection.ASCENDING);Список некоторых действий с таблицей смотрите на скриншотах ниже:
Использование Masquerade значительно упростило написание тестов, теперь, чтобы написать тест для новой функциональности, нужно:
- С помощью Masquerade описать страницу — это делается легко и не требует особых навыков программирования.
- Собрать в одном классе все страницы, которые используются при проверке функционала.
- Из готовых конструкций естественного языка собрать тестовый сценарий (подставив туда названия нужных элементов), то есть написать Gauge-спецификацию.
Интегрируем Masquerade и Gauge
До использования BDD, применялся подход TLD и для работы с ним мы также оптимизировали процесс написания кода тестов. Использовали связки jUnit/TestNG + WebDriver+Selenide+Masquerade.
Теперь, для того, что бы работать с Gauge, добавляем соответствующий плагин в intellij IDEA. После этого появится возможность создавать новый тип тестов — Specification.
Теперь создаем спецификацию (сценарий) и имплементируем шаги, используя возможности WebDriver, Masquerade и Java.
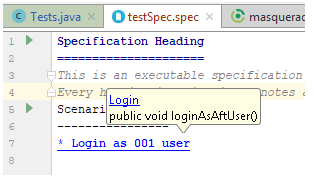
Кликаем на шаг сценария и переходим в имплементацию:
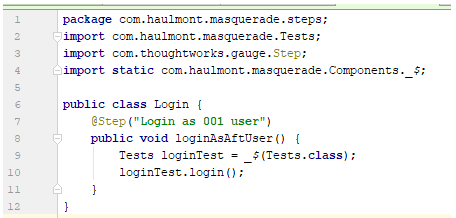
В имплементации можно использовать уже существующий метод login().
Как же выглядит это совершенство?
Вспомним пример, который мы рассматривали в самом начале статьи:
"Navigation.openMenu(menu)” содержит реализацию открытия меню с помощью библиотеки Masquerade.
Библиотека впоследствии была расширена и появились универсальные шаги, которые могут быть использованы для любого CUBA-приложения. Это шаги, позволяющие работать с элементами программы: кнопками, полями, таблицами. Эти универсальные шаги и стали тем набором стандартных фраз, которые мы используем в BDD для написания сценариев.
Благодаря связке Masquerade+Gauge мы существенно снизили трудоемкость создания тестов. Теперь тесты могут писать люди, не имеющие особых навыков программирования. Тест может писать один человек (раньше сценарий придумывал один, а реализовывал — другой, что приводило к путанице). Итак, мы добились своей цели — интерфейсы упрощены, а аналитикам не составит труда писать тестовые сценарии.
Изменения процесса изображены ниже:
Было:
Стало:
В сравнении видно, что требования, спецификация и тест документация объединены в один пункт. Тест документация является и автотестом, за исключением имплементации специфичных тестовых шагов.
Итоги
На данный момент мы успешно ведем разработку по обозначенной выше схеме. И нам удалось избавиться от главной проблемы BDD — серьезного увеличения сроков из-за сложности реализации, добавив и доработав инструментарий. Однако, качество выдачи продуктов улучшилось.
Временные затраты на поддержку документации сокращаются пропорционально количеству измененных спецификаций, т.к. одно изменение спецификации (логики системы) приводит автоматически к изменению автотеста за одну итерацию. Т.е. тестировщику не нужно лезть в систему документации (типа Confluence и т.д) для апдейта, и для других участников команды это тоже справедливо.
Время на реализацию и поддержку тестов при наличии библиотеки, упрощающей работу с объектами страницы, уменьшилось в два раза, по сравнению с работой с обычным чистым web -driver и затратами на переделку ссылок XP.
В разработке любого бизнес решения и в управлении качеством — стоимость устранения ошибок сбора требований и анализа растет экспоненциально. Соответственно вероятность получения проблем, связанных с переделкой продукта, согласно существующим статьям и графикам при итеративной разработке, при раннем обнаружении проблемы, которая заключается в хорошей проработке требований, существенно снижает стоимость разработки, в зависимости от проекта. Это может быть и 0% и ~ 40%. Именно это улучшение достигается за счет внедрения BDD. Это можно внедрить и не называя это словом BDD, но в BDD оно есть. Наличие возможности обойти проблемы является важной частью обеспечения качества.
В завершение, хотелось бы отметить, что данная схема разработки также интегрирована у нас с Continuous Integration и разработанной в нашей компании системой тест менеджмента — QA Lens. В QA Lens можно писать те же сценарии, что и в IDEA, используя предметно-ориентированный язык. Этот язык состоит из ранее составленного глоссария доступных действий, которые ранее имплементированы. При выполнении автотеста на Gauge с машины разработчика или CI — в QA Lens автоматически отмечается: какие шаги сценариев были пройдены, а какие нет. Таким образом, прогнав автотест сценария, написанного аналитиком, отдел тестирования сразу получает полную актуальную информацию о состоянии продукта.
Авторы: Сунагатов Ильдар и Юшкова Юлия (Yushkova)
Как правильно определять требования к продукту или системе, чтобы результаты разработки совпадали с ожиданиями.
Вольный перевод статьи: Behavior-Driven Development — Scaled Agile Framework.
Это именно то, о чем я просил, но не то, что я хочу
Поэма «Ночь перед воплощением», автор неизвестен
Разработка на основе поведения (Behavior-Driven Development, BDD) — это практика Agile-тестирования, когда в первую очередь проводятся проверочные испытания, которые обеспечивают встроенное качество за счет определения (и, потенциально, автоматизации) тестов до или как часть определения поведения системы. BDD — это совместный процесс, который создает общее понимание требований между бизнесом и Agile-командами. Его цель — помочь в управлении разработкой, уменьшить количество переделок и увеличить поток. Не фокусируясь на внутренней реализации, тесты BDD представляют собой бизнес-сценарии, которые пытаются описать поведение пользователя с точки зрения Истории (Story), Фичи (Feature) или Возможности (Capability).
Будучи автоматизированными, эти тесты гарантируют, что система постоянно соответствует заданному поведению даже в процессе своего развития. Это, в свою очередь, позволяет выпускать Релиз по Потребности (Release on Demand). Автоматизированные тесты BDD могут также служить для формулирования поведения системы, в качестве встроенной в другую систему.
Как определить будущее поведение системы
При разработке инновационных систем сложно точно определить, что именно нужно создать. Кроме того, новые идеи трудно донести до широкого круга заинтересованных лиц, ответственных за внедрение системы. На рис. 1 показаны три точки зрения (называемые триадой), необходимые, для четкого определения поведения решения:
- клиентоориентированные заинтересованные лица понимают потребности клиентов и бизнеса, их пожелания и насколько они осуществимы;
- заинтересованные лица, ориентированные на разработку, понимают возможности решения и технологическую осуществимость;
- заинтересованные лица, ориентированные на тестирование, видят исключения, граничные случаи и ограничительные условия для нового поведения системы.
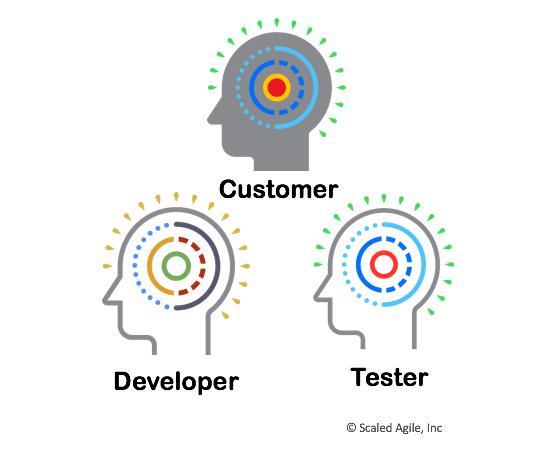
Рис. 1. Разнообразие восприятий, необходимое для определения объективного принятия решения
Вместе эта группа достигает согласованности в том, что именно нужно создавать, чтобы уменьшить количество ошибок и переделок и ускорить поток ценностей.
Процесс поведенческой разработки
Процесс BDD проходит три этапа — исследование (discovery: раскрытие проблемы клиента и ее решения), формулирование и автоматизация — где критерии приемки преобразуются в приемочные испытания, которые затем автоматизируются. Процесс начинается на этапе исследования, когда Владелец Продукта (Product Owner, РО) или Менеджер Продукта (Product Manager, PM) создает критерии приемки как часть написания Истории или Фичи. Процесс исследования является совместным, и члены команды также определяют и вносят дополнительные критерии.
По мере того, как элемент бэклога приближается к реализации, на этапе формулирования, критерии приемки закрепляются через создание приемочных тестов. Первоначальные критерии приемки часто описываются неопределенными общими терминами. Этап формулировки устраняет эти неясности, превращая сценарии в подробные приемочные тесты, которые представляют собой конкретные, четкие и однозначные примеры поведения.
На этапе автоматизации приемочные тесты автоматизируются, поэтому они могут проводиться непрерывно и проверять, что система всегда поддерживает актуальное поведение.
Задача BDD — однозначно выразить требования, а не просто создать тесты. Приемочные тесты служат для записи решений, принятых в ходе обсуждений между командой и Владельцем Продукта, чтобы команда однозначно понимала предполагаемое поведение продукта. Есть три альтернативных варианта для этого процесса детализации:
- поведенческая разработка (BDD);
- разработка на основе приемочных испытаний (Acceptance Test-Driven Development, ATDD);
- спецификация на примере (Specification By Example, SBE).
В подходах существуют небольшие различия, но все они подчеркивают необходимость понимания требований до их реализации.
Пример
Описание поведения начинается с Истории, Фичи или Возможности, указанных в критериях приемки. Все они определяются с использованием клиентских терминов, а не внедрения. Вот пример истории и критерии ее принятия:

Рис. 2. Пример истории и критерии приёмки
Критерии приёмки также могут быть записаны в формате «Given—When—Then» (GWT), как показано ниже:
Given (Дано) ограничение скорости
When (Когда) машина едет
Then (Тогда) скорость близка к предельной, но не выше.
Даже в этом случае разработанных критериев приёмки обычно недостаточно, чтобы оформить Историю. Чтобы устранить неопределенность, сформулируйте сценарий в виде одного или нескольких примеров, которые определяют детали поведения, что приведет к конкретному приемочному тесту:
Дано ограничение скорости — 80 км/ч
Когда машина едет
Тогда её скорость — от 78 до 80 км/ч.
В сотрудничестве с командой (триадой) появятся дополнительные критерии приёмки и сценарии, например: когда ограничение скорости меняется, скорость резко не меняется.
Этот критерий приводит к дополнительным тестам, которые определяют допустимую интенсивность замедления:
Дано ограничение скорости составляет 80 км/ч
Когда ограничение скорости изменяется до 50 км/ч
Тогда скорость должна снижаться менее чем на 5 км/ч за сек.
На рис. 3 показан процесс BDD, который начинается с Истории и детализирует ее спецификацию в двух измерениях. По горизонтали дополнительные критерии приёмки детализируют требования к истории. По вертикали дополнительные приемочные тесты детализируют эти требования к приемочным тестам.
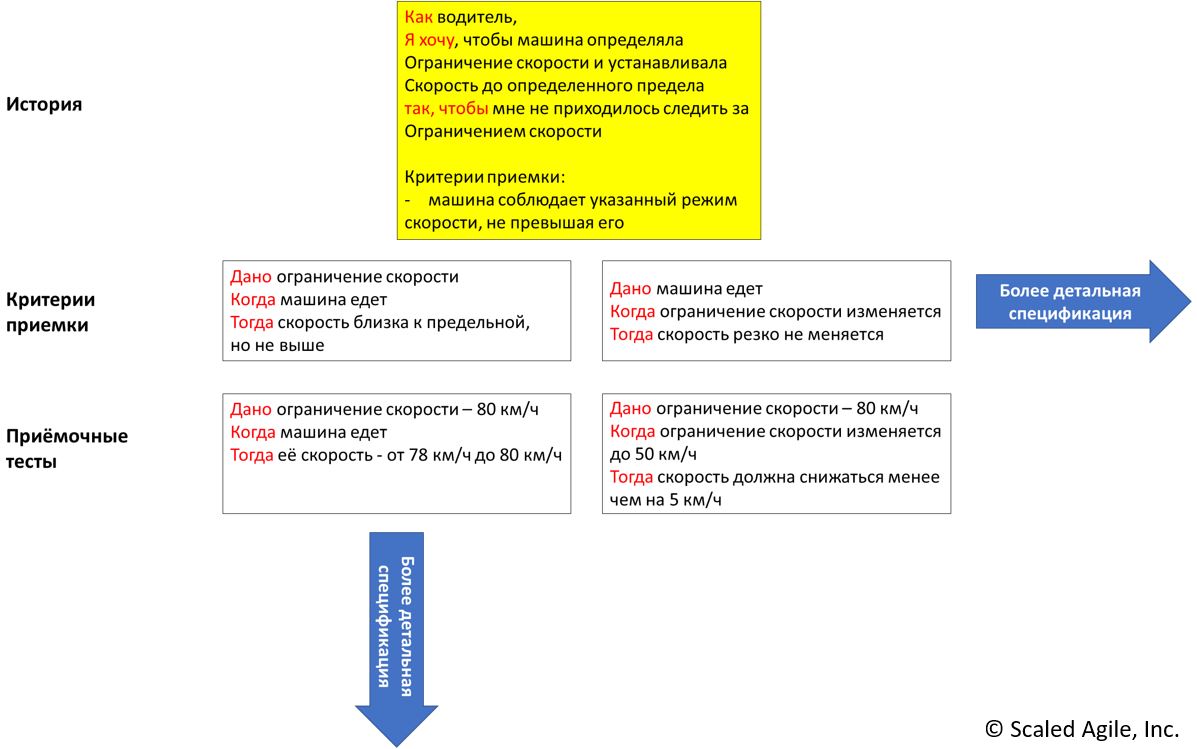
Рис. 3. Процесс BDD детализирует поведенческие характеристики.
Автоматизация приемочных тестов
Автоматизация этих бизнес-тестов является важной причиной по использованию формата «Дано—Когда—Тогда» (GWT — Given—When—Then). Для поддержки этого синтаксиса можно использовать такие инструменты как Cucumber и Framework for Integrated Testing (FIT) . Для поддержки тестирования регрессии непрерывной поставки тесты должны быть по возможности автоматизированы.
Приемочные тесты Истории пишутся и выполняются в той же итерации, что и разработка кода. Если История не проходит тесты, История не засчитывается команде. У Фич и возможностей есть свои собственные приемочные тесты, которые показывают, как несколько Историй работают вместе в более широком контексте. Как правило, эти тесты демонстрируют поведение более крупных сценариев рабочего процесса и должны выполняться во время итерации, в которой Фича или возможность завершены.
SAFe and Scaled Agile Framework are registered trademarks of Scaled Agile, Inc.
На что обратить внимание?
- Концепция BDD — есть расширение методологии TDD.
- Тесты пишутся на предметно-ориентированном языке, их легко изменять.
- Тесты становятся доступны как программистам и тестировщикам, так и менеджерам.
- Тесты не зависят от целевого языка программирования. Миграция на другой язык сильно упрощается.
Таким образом, суть состоит в том, что изначально на основе определенных лингвистических шаблонов составляются верхнеуровневые сценарии, описывающие вероятное поведение системы. После этого разрабатывается функциональность. Ожидается, что после завершения разработки предопределенные тестовые сценарии станут успешно выполняться.
Сценарий – описание поведения определенной функциональности системы, составленное на естественном языке по определенному шаблону. Важно, что для подготовки сценариев используются общеупотребительные языки. Это позволяет автоматизаторам и тестировщикам заказчика легко составлять сценарии вместе.
Общеупотребительный язык – определенные лингвистические конструкции, интерпретируемые программным кодом автотестов. Как следствие, отпадает необходимость трудозатрат на преломление, изменение или же конкретизацию документации под разработку или QA.
BDD фокусируется на следующих вопросах:
- С чего начинается процесс.
- Что нужно тестировать, а что нет.
- Сколько проверок должно быть совершено за один раз.
- Что можно назвать проверкой.
- Как понять, почему тест не прошёл.
Исходя из этих вопросов, BDD требует, чтобы шаги тестов были целыми предложениями, которые начинаются с глагола в сослагательном наклонении и следовали бизнес целям.
Описание приемочных тестов должно вестись на гибком языке пользовательской истории. В настоящее время в практике BDD устоялась следующая структура:
1) Заголовок (англ. Title). В сослагательной форме должно быть дано описание бизнес-цели.
2) Описание (англ. Narrative). В краткой и свободной форме должны быть раскрыты следующие вопросы:
- Кто является заинтересованным лицом данной истории;
- Что входит в состав данной истории;
- Какую ценность данная история предоставляет для бизнеса
3) Сценарии (англ. Scenarios). В одной спецификации может быть один и более сценариев, каждый из которых раскрывает одну из ситуаций поведения пользователя. Каждый сценарий обычно строится по одной и той же схеме:
- Начальные условия (одно или несколько);
- Событие, которое инициирует начало этого сценария;
- Ожидаемый результат или результаты.
На что обратить внимание?
- Технически сопоставление происходит посредством регулярного выражения /^User enters login ‘(.+)’$/ , которое и находится в Step Definition.
- Логин пользователя (он же захваченный параметр ‘user_login’) передается в переменную login_word. Она в свою очередь передается на вход функции enter().
2) Результаты шагов
Исполнение каждого шага завершается в одним из следующих статусов:
- Success
- Undefined
- Pending
- Failed Steps
- Skipped
- Ambiguous
Рассмотрим каждый более детально:
1) Success
В случае, если Cucumber находит нужный Step Definition, он запускает выполнение содержимого шага. Если блок кода в соответствующем Step Definition не выдает ошибок по ходу исполнения, шаг помечается как успешный.
Цвет: зеленый
2) Undefined
Если Cucumber не удается найти соответствующее определение шага, то степ помечается как неопределенный и все последующие шаги в сценарии будут пропущены.
Цвет: желтый
3) Pending
Если определение шага выполнено не полностью, то шаг помечается как в ожидании.
Цвет: желтый
4) Failed Steps
Если блок кода внутри Step Definition завершается с ошибкой, то шаг считается проваленным.
Цвет: красный
5) Skipped
Шаги, следующие за Undefined, Pending и Failed степами, не вызываются.
Цвет: голубой
6) Ambiguous
Чтобы Cucumber точно знал, какой блок кода ему вызывать, определение шага должно быть строго уникальным. Cucumber возвращает Cucumber::Ambiguous error, в случае если присутствуют неоднозначные Step Definitions.
3) Организация хранения шагов
Определения шагов можно хранить как в одном файле, так и в нескольких. Однако, скорее всего, на начальном этапе работы с проектом, они вполне поместятся в один. А уже по мере роста появится необходимость сгруппировать их по смыслу и разнести в разные файлы. Так проект будет проще поддерживать в будущем.
Технически абсолютно неважно, как будут называться эти файлы, и какие шаги будут в них храниться. Однако существует рекомендация называть их *_steps.rb (если используется Ruby).
Например, в приложении для резюме будет уместно выделить следующие файлы:
Многие знакомы с методологией Test-Driven Development и, в частности, Behavior-Driven Development. Этот подход к разработке и обеспечению качества ПО набрал большую популярность, поскольку позволяет выстроить четко установленное соответствие между бизнес-требованиями и технической реализацией продукта.
На Russian Python Week 2020 Владислав Мухаматнуров, Senior QA automation на примере проекта голосового ассистента в Tinkoff, разобрал задачи, которые решает BDD. В своем докладе Влад разобрал, что такое BDD и Gherkin, откуда возникает потребность в поведенческом тестировании на проекте и как выглядит имплементация предметно-ориентированного языка для тестирования, базирующейся на диалогах системы. А под катом мы предлагаем вам прочитать расшифровку доклада.

Проект: Голосовой Ассистент «Олег»
Это тот самый голосовой помощник, который помогает людям в чатах мобильных приложений или когда они звонят в банк. Голосовой ассистент Олег от Tinkoff Mobile берет трубку и общается с клиентами.
Давайте подробнее поговорим об этом проекте:
-
Микросервисная архитектура.
-
В основе системы лежит:
-
Классификация и распознавание намерения пользователя;
-
Генерация действий на входное воздействие;
-
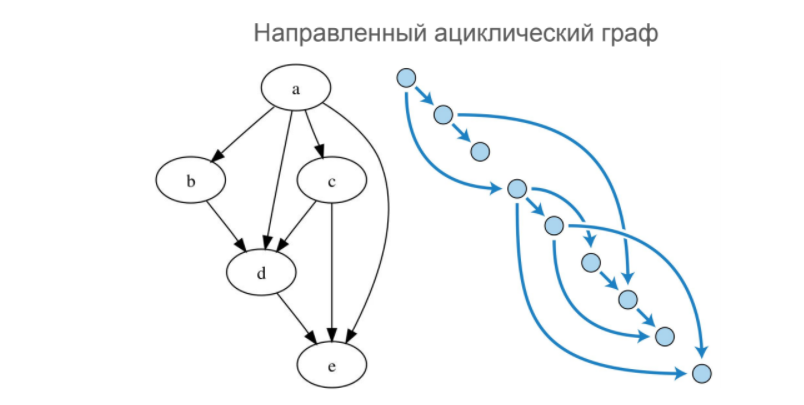
Сообщения в диалогах классифицируются на основе направленного ациклического графа.
Направленный ациклический граф
Это граф, который имеет начальный и конечный узлы, и из первого во второй можно добраться различными путями, в том числе параллельными. Но при этом нельзя выйти из начального узла и вернуться обратно в начальный узел.
Основные сервисы:
-
диалоговая платформа, которая осуществляет маршрутизацию сообщений клиента по нужным каналам обработки;
-
классификаторы, позволяющие выделять полезную нагрузку из сообщений пользователя и правильно понимать, как ее нужно обработать;
-
CRM-система, которая содержит процедуры работы с клиентами;
-
вспомогательные сервисы.
Тестирование на проекте
Однажды мы задались вопросом, как организовать тестирование на таком сложном проекте? Более того, у нас появились другие вопросы:
-
что у нас является тест-кейсом?
-
каким может быть входное воздействие на нашу систему?
-
каким может быть результат обработки сообщений?
-
как все это автоматизировать?
Мы начали думать и формулировать, как могут быть выражены бизнес-кейсы использования нашей системы. Для начала нужно было посмотреть на диалоги системы и пользователя:

Есть четко регламентированные воздействия на систему со стороны пользователя, а в ответ на эти воздействия система что-то генерирует. Попытаемся классифицировать эти ответы.
Посмотрим на взаимодействие в чате.
Действия пользователя:
-
напечатать текст;
-
надиктовать текст голосом;
-
нажать на подсказку;
-
нажать на кнопку виджета;
-
отправить файл.
Действия бота:
-
ответить текстом;
-
ответить текстом и голосом;
-
отправить подсказку;
-
отправить виджет;
-
отправить файл.
То есть бот делает то же самое, что пользователь, но в обратную сторону.
Описание бизнес-кейса
На основе этого сформировалось понимание, как может выглядеть бизнес-кейс на бумаге. Например:

User stories
В примере приведена пользовательская история. Это способ описания требований к разрабатываемой системе, сформулированных при помощи предметно-ориентированного языка.
Особенности user stories:
-
быстрый способ документировать требования бизнеса к реализации продукта;
-
минимизация обширных формализованных технических и бизнес спецификаций;
-
низкая цена поддержки.
На основе этого мы сформулировали требования к нашему процессу обеспечения качества и, в принципе, к улучшению процесса разработки на проекте.
Так, мы хотели связать постановку технических и бизнес-задач на основе историй использования системы, получить фундамент для тест-кейсов на основе бизнес-кейсов, автоматизировать регресс системы на основе пользовательских историй. Кроме того, нам было важно пополнить процесс разработки возможностью описать поведение системы и при помощи этих историй добиваться ее работоспособности согласно сценариям.
Я расскажу о чертах BDD или «разработки на основе поведения».
Behaviour-Driven Development
BDD — это ответвление методологии разработки через тестирование. Суть BDD заключается в том, что у нас есть бизнес-требования к продукту, которые мы описываем на предметно-ориентированном языке и получаем сценарий использования системы. Далее реализуем техническую часть системы и в конечном итоге создаем крутой конкурентноспособный продукт.

Классический цикл Behaviour-Driven Development состоит из 5 шагов:
-
Описываем поведение системы.
-
Определяем технические требования к системе.
-
Запускаем тесты или руками проверяем сценарии поведения. А они, естественно, падают, потому что система еще не готова или не реализована.
-
Дорабатываем нашу систему, то есть создаем, обновляем, дополняем, изменяем.
-
Добиваемся того, чтобы система проходила наши сценарии использования.
В основе BDD лежат спецификации поведения. Это документы, которые имеют следующую структуру:
-
заголовок — описание бизнес-цели;
-
описание — субъект, состав истории, ценность для бизнеса;
-
сценарии — ситуация поведения субъекта.
Gherkin и детали имплементации BDD
Gherkin — это предметно-ориентированный язык (по сути DSL), который позволяет описать поведение системы при помощи специальных ключевых слов, заранее зафиксированных.
Пример сценария, написанного на Gherkin:

В Gherkin употребляются ключевые слова. Их можно объединить по 4 основным группам:
-
Шаблон:
-
Background / Предыстория
-
Scenario / Сценарий
-
Scenario Outline / Структура сценария
-
Таблицы:
-
Examples / Примеры
-
Язык Gherkin: ключевые слова
-
Шаги:
-
Given / Дано
-
When / Когда
-
Then / Тогда
-
Предлоги:
-
And / И
-
But / Но
Пройдемся по этим ключевым словам.Ключевое слово: Функция.
Это название спецификации, отражающее определенную бизнес-функцию. Первая строчка в документе, описывающем ее, должна начинаться с ключевого слова «Функция:».

Ключевое слово: Сценарий.
Рядом с ключевым словом размещается краткое описание сценария.

Ключевое слово: Структура сценария.
Структура сценария позволяет избежать повторения конструкций. Когда вы пишете много похожих друг на друга сценариев, их можно шаблонизировать. Для этого и употребляется структура сценария.

Ключевое слово: Примеры.
Это таблицы с данными для параметризации структуры сценария. Они могут содержать много переменных, быть заданы горизонтально и вертикально, как представлено в примере.

Ключевое слово: Предыстория.
Предыстории добавляют определенный контекст ко всем Сценариям в пределах Функции. Фактически, Предыстория — это сценарий без имени, состоящий из конечного множества шагов, которые, как правило, специфицируют систему и пользователя перед каждым Сценарием.

Ключевое слово: Дано.
Назначение шагов Дано состоит в приведении системы и ее пользователя в определенное состояние. Их можно рассматривать как предусловия сценария.

Ключевое слово: Когда.
Основная задача этого ключевого слова состоит в описании ключевого воздействия, совершаемого пользователем на нашу систему.

Ключевое слово: Тогда.
Оно необходимо для наблюдения за результатом выполнения действий. По сути, для проверки вывода системы (отчеты, интерфейс, сообщения). Наблюдения должны быть связаны с описанием Функции и Сценария.

Ключевые слова: И, Но.
Это предлоги. Они необходимы, когда есть несколько последовательных шагов Дано, Когда или Тогда. В данном случае предлог И — это смысловой аналог конъюнкции, а предлог Но — смысловой аналог инверсии.

Пример диалога системы с пользователем
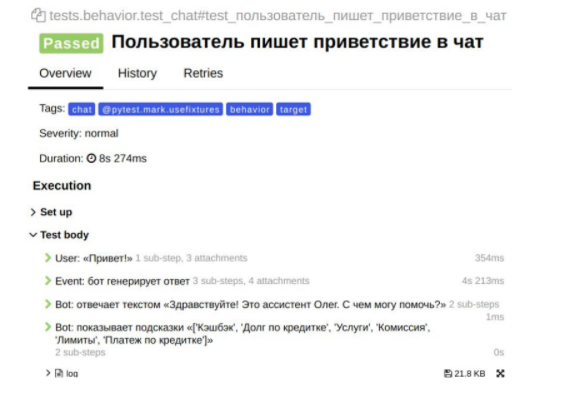
Рассмотрим простейший пример, где пользователь пишет «Привет!», а бот отвечает ему текстом и показывает подсказки:

Рассмотрим, как это можно зафиксировать при помощи наших сценариев и спецификаций поведения.
Пример использования Gherkin

Здесь есть конкретная Функция: Бот умеет приветствовать пользователя. Кроме того, мы видим предысторию, о том, что это за клиент, в какой ОС он сидит и какую версию приложения использует. Ведь в зависимости от разных версий приложения могут быть показаны разные виджеты.И у нас есть сам сценарий, согласно которому в ответ на то, что пользователь пишет: «Привет!», бот отвечает фиксированным текстом и дает фиксированные подсказки.
Пример отчета по сценарию поведения
Это автоматически сгенерированный отчет при помощи нашего внутреннего инструмента автоматизации, который отражает сценарий поведения с результатом Passed:
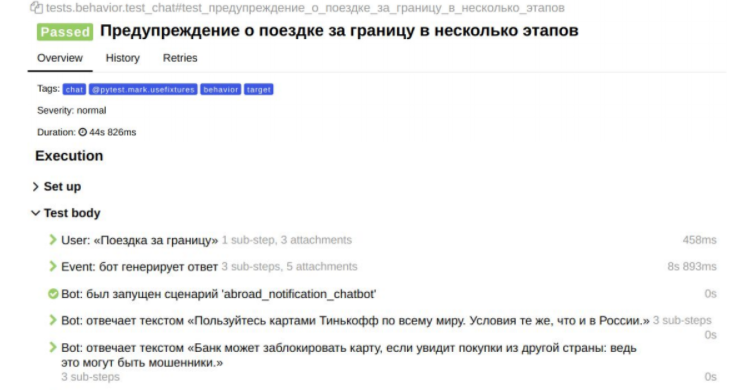
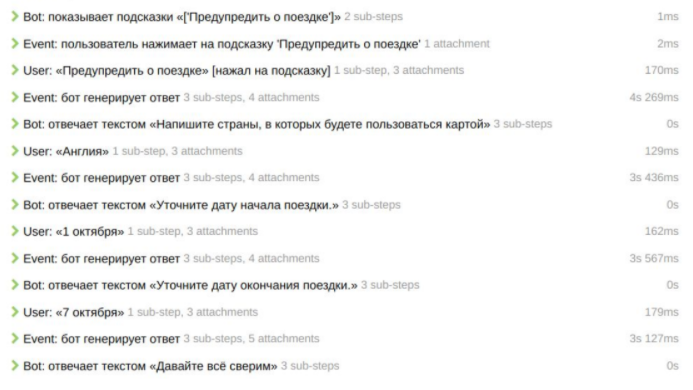
Пример посложнее: «Поездка за границу»

Тут пользователю необходимо написать о своем намерении уехать за границу. Бот это поймет, предложит добавить поездку, и начнется выбор страны, даты отъезда и т.д. А дальше мы ждем, что пользователь подтвердит факт, что поездка планируется.

Так может выглядеть этот бизнес-кейс при помощи нашего предметно-ориентированного языка:



То, что вы видите в приложении и пишите системе, описывается в сценариях поведения. У нас появляется прямое соответствие бизнес-кейсов и тест-кейсов, то есть они, по сути, идентичны.
А при помощи инструмента автоматизации можно собирать входные воздействия и добавлять регресс, автоматизировать, делать аналитику на основе получаемых данных.
Пример отчета по сценарию поведения

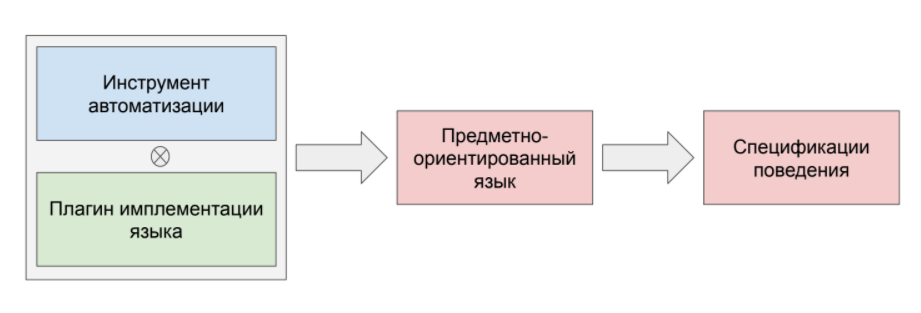
Интересно рассмотреть, как реализуется Gherkin «под капотом».
У нас есть инструмент автоматизации. К нему прикручивается плагин имплементации конкретно для нашего языка программирования. Далее, на основе этой конструкции, реализуется каркас предметно-ориентированного языка, и затем можно писать спецификации поведения.
Задачи, решаемые BDD
Я выделил три важные задачи, которые решает разработка на основе поведения:
-
объединение бизнеса и разработки;
-
установление единого восприятия бизнес-кейсов;
-
удешевление поддержки тест-кейсов.
Рассмотрим классическую ситуацию.
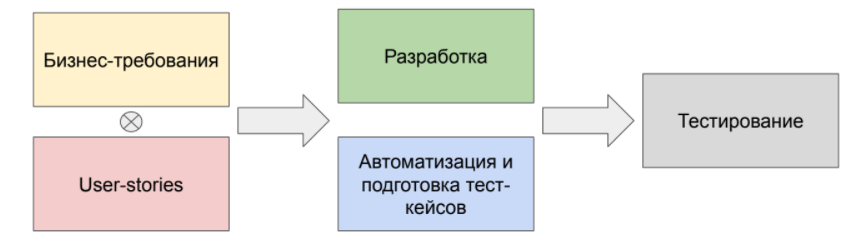
У нас есть продукт, а у него продакт-менеджер. Он хочет очередной бизнес-эпик, описывает его в виде бизнес-требований и передает в команду.
У команды есть технический аналитик, который на основе бизнес-требований формирует технический эпик и техническую спецификацию по данной фиче. На основе технической спецификации команда разработки реализует функциональность. Согласно задачам, эта функциональность поступает в отдел тестирования. И QA при помощи тест-кейсов тестирует фичу, находит баги или подтверждает работоспособность нашей системы.
В конечном итоге у нас сформирована спецификация по тестированию данной фичи.
Итак, у нас есть три основные документа:
-
Бизнес-требования к продукту.
-
Техническая спецификация продукта.
-
Спецификация по тестированию продукта.
И вот он — классический случай, где каждый из документов является новым отображением на основе предыдущего документа. Проблема в том, что у нас нет единого понимания, что такое сценарий использования приложения, и часто размыты понятия поведения системы и пользователя в этих документах. Как следствие, бизнес-кейсы сильно отличаются от тест-кейсов. Разница в формате реализации документов приводит к проблемам в восприятии информации участниками процесса.
Например, продакт-менеджер приходит и задает важный и правильный вопрос про фичу у продукта.
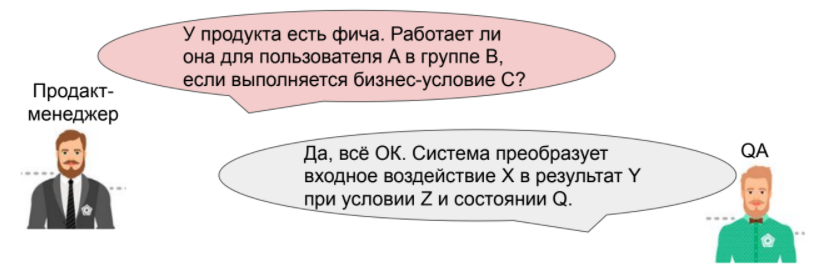
Чтобы ответить на него, QA переводит с бизнес-языка на технический: что за пользователь, как реализуются обработка конкретной группы и выполнение условия C в системе?
А потом смотрит, есть ли у нас кейсы на проверку комбинации из заданных технических особенностей при указанном условии. Если кейсы есть, QA сразу дает ответ. А если нет, проверяет руками.
На картинке QA дает ответ на вопрос менеджера продукта, но как будто бы на своем языке. И он тоже прав. Он дал абсолютно корректный, правильный ответ. Но кажется, что этот ответ не совсем коррелирует с заданным вопросом.
BDD — это про объединение бизнеса и разработки. Постановка задач BDD от бизнеса выполняется в виде спецификаций поведения. Такие спецификации уже используются в качестве основы для технических требований, а также являются фундаментом для тест-кейсов.
Единое восприятие продукта
Мы начинаем воспринимать продукт одинаково. Когда менеджер в следующий раз задаст свой правильный и важный вопрос, QA ответит на его языке:
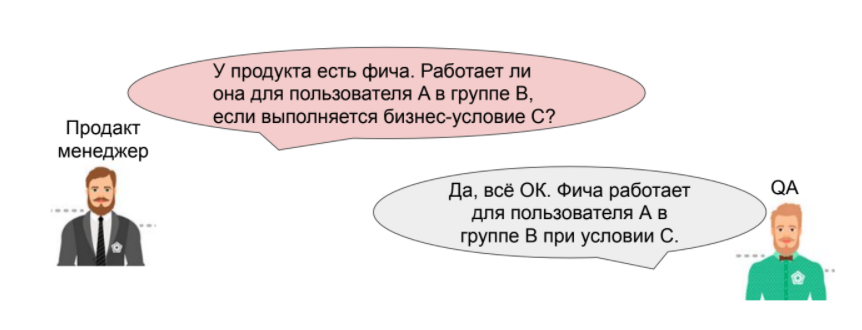
Он ответит так, потому что у него есть тот самый бизнес-кейс, который уже написан на Gherkin. В нем описывается функция и конкретный сценарий поведения.

У нас появляется единое восприятие бизнес-кейсов. Спецификации поведения (на основе утвержденного шаблона) понятны всем: продуктологам, аналитикам, разработчикам и тестировщикам.
Такие сценарии легко реализуемы. А если их автоматизировать, вы получите эффективный инструмент для сбора аналитики и формирования отчетов. Кроме того, эти сценарии позволят вам итеративно улучшать продукт.
Всё это можно делать непрерывно, ежедневно улучшая продукт. Также BDD позволяет удешевить поддержку тест-кейсов.
Спецификации поведения сами по себе реализуются на основе набора простых конструкций имплементированного предметно-ориентированного языка. По сути такие сценарии почти не зависят от программной реализации вашего инструмента автоматизации «под капотом».
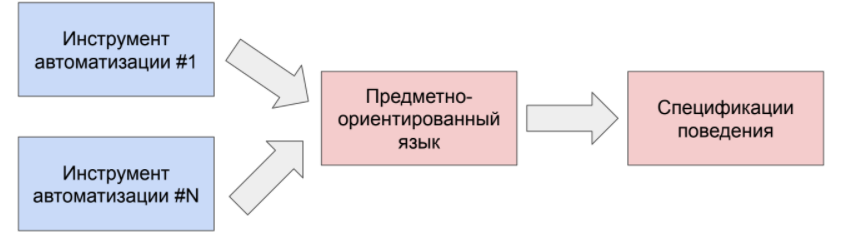
То есть можно взять любой инструмент автоматизации, но при этом использовать один предметно-ориентированный язык, те же самые спецификации поведения, и все должно быть идентично. Не нужно переписывать тест-кейсы, если вы меняете фундамент инструмента автоматизации.
Давайте сравним тест-кейсы автоматизации: слева — уже привычный тест на Gherkin, справа — кейс на фреймворке Tavern.

Справа более технический тест-кейс, а слева, по сути, просто описание бизнес-функции. Но, как правило, всем приятнее видеть именно то, как работает система в тест-кейсах, и какие она генерирует ответы на запросы.
Преимущества интеграции BDD
На собственном опыте мы ощутили преимущества интеграции BDD:
-
Идеально тестировать диалоги чат-бота и говорящего робота.
-
Понятная спецификация системы и пользователя, например:
-
Версии приложения, ОС, часовой пояc.
-
Тип клиента, продукта, номер телефона.
-
На основе ограниченного набора шагов мы сделали маппинг. Используем ключевые слова:
-
Дано — для спецификации пользователя и системы, как это канонически предусмотрено.
-
Когда — для описания действий пользователя.
-
Тогда — для описания реакции системы.
Проблемы, не решаемые BDD
-
Процесс разработки: если он плохо поставлен, интеграция BDD не сделает его быстрее и качественнее.
-
Регрессионное тестирование: при отсутствии (или серьезной нестабильности) QA-контура или стейджинга не будет возможности обеспечить регресс на основе созданных сценариев поведения, в том числе, автоматизированный.
-
Релизный процесс: при отсутствии поставленных в командах проекта процессов по контролю качества и релизам, интеграция BDD не позволит гарантировать работоспособность согласно спецификациям поведения.
Если вы делаете BDD, нужно контролировать работоспособность системы до того, как все это выкатится в продакшен. Только тогда BDD принесет классные результаты.
Видео доклада можно увидеть тут.
Практика BDD в автоматизации QA — гайд по Cucumber/Gherkin — вопросы на собеседовании по BDD/Cucumber
Сейчас узнаем, что такое BDD и как оно работает; плюсы-минусы и подводные камни; как в одной международной компании выбрали BDD и не пожалели; постараемся запомнить лучшие практики BDD; ну и посмотрим на примеры BDD на Gherkin (много).
Содержание
- Что такое BDD в QA
- Фреймворки для BDD
- Как мы выбрали BDD и не пожалели
- Плюсы BDD
- Минусы BDD
- Что такое Gherkin
- Ключевые слова Gherkin
- Как мы переходили на Gherkin
- Практика в Cucumber
- Features в Cucumber
- Контрольные вопросы / Собеседование Cucumber
Что такое BDD-разработка, как она применяется в QA
“Разработка через поведение” (BDD — Behavior Driven Development) в QA — это легко читаемые человеком, не владеющим языками программирования, описания требований к продукту — как основа процесса тестирования. Такие тесты являются реюзабельными — то есть могут применяться многократно без больших изменений, но если все-таки понадобится изменить какие-то детали, это будет легко. BDD-тесты предназначаются, в основном, для проверки функциональных компонентов, и далее применяются повторно на более высоком уровне тестирования, что ускоряет пайплайн.
Самое частое применение BDD-метода — это UAT-тесты (User Acceptance Tests, то есть пользовательское или приемочное тестирование). Такие тесты строятся на user story (что это?) и на бизнес-требованиях, и имеют особенность: они пишутся в форме, хорошо воспринимаемой человеком, как бы на обычном языке. Разумеется, “обычный язык” здесь следует понимать ограниченно, поскольку в нем все-таки заданы рамки, есть строго определенные вещи. Основа, или “скелет” тестов может быть написан product owner-ом (или владельцем продукта — здесь можно почитать, кто это?), или бизнес-аналитиком.
BDD-тесты пишутся так, чтобы их мог прочесть человек, не знающий языков программирования (но знающий английский, хотя бы минимально)
Первый шаг, предпринимаемый командой при внедрении BDD — создать некие общие определения, понимаемые стейкхолдерами (кто это?), экспертами в какой-то области (domain experts), разработчиками, и конечно тестировщиками. Этими определениями будут описываться основные модули продукта, события, и ожидаемые (пользователями) результаты. То есть сначала создается набор терминов, согласованный всеми участниками. Это важно, потому что это фактически определяет успешность внедрения BDD.
Основной позитив от BDD состоит в том, что практически все члены команды, как технические специалисты, так и “другие” — способны быстро понять и оценить результаты тестов, и в целом им легче работать с такими тестами.
Какие фреймворки применяются в BDD?
- Во первых, Cucumber
- Quantum (это для Java на Андроиде и/или iOS)
- SpecFlow (это для .NET)
- Jbehave (это для команды, овладевшей Groovy/Kotlin/Scala)
- Codeception (для PHP)
Как мы выбрали BDD и не пожалели
На начальном этапе, когда проект только стартовал, когда кто-то предлагает переключиться на новую методологию BDD, опытные лиды учитывают, что начальная подготовка BDD-проекта почти наверняка будет дольше и сложнее, чем все привыкли на старых методологиях. Просто потому что раньше все шло “по накатанной” — есть более-менее стандартный проект; с какой-то автоматизацией; его предполагаемая структура более-менее известна; все знают что делать; берется фреймворк автоматизации, известный вдоль и поперек, настраивается веб-драйвер, или API-шлюз, выбирают язык программирования из короткого списка, ну и пишут первые тесты.
С BDD-проектом так вряд ли получится так просто, сначала понадобится больше времени и усилий. Этапы выбора языка и прочее остаются, и добавляется “экстра” — о чем речь шла выше, “общий словарь терминов”, который будет понятен буквально каждому члену команды, что иногда непросто; по опыту, этот шаг занимает много времени.
BDD лучше подходит для долгосрочных проектов, особенно корпоративных, для крупных заказчиков. В таких проектах плюсы BDD проявятся. Если же проект запланирован на год или меньше, то “лучше идти по пути без BDD” — так, видимо, будет проще, быстрее, и дешевле.
Если проект “большой”, корпоративный, то есть подходит для BDD — то скорее всего для фронтэнда вполне сгодятся имеющиеся тестовые инструменты; условно для прокликивания веб-элементов можно применять стандартную связку типа Browserstack+Selenium. Для бэкэнда можно Postman+Smartbear.
BDD подходит для крупных долгосрочных только-начатых проектов потому, что там обычно большое количество реюзабельных тестовых компонентов, шагов и функций, которые должны быть понятны всем членам QA-команды, разбросанной по миру. Но BDD вряд ли идеально подойдет для сложных проектов с большим количеством уже написанных модулей, ибо рефакторить имеющийся код “под BDD” может быть довольно-таки затратно по времени.
Плюсы BDD
- Поддерживается английский, понятный каждому тестировщику — т.н. Simple English с ограниченным словарем, и + еще 70 языков (включая русский, разумеется)
- Тесты по идее понятны любому члену команды
- Позволяет поддерживать в команде высокий уровень вовлеченности и понимания продукта
- Экономятся деньги и усилия, при правильном внедрении
- QA-персонал прокачивает свой уровень компетенций, интуитивно обучаясь
Минусы BDD
- Медленнее деплой
- Могут быть проблемы на этапе деплоя
- Много как бы “лишних” классов, функций, этапов, с точки зрения некоторых педантов
- Нужна очень хорошая коммуникация в команде, и очень опытные лиды
- Проект в целом получается “сложнее”, если нужен рефакторинг существующего кода
- Документация…
Что такое Gherkin
Это так называемый business-readable язык программирования, описывающий бизнес-поведение, на котором пишется “скелет тестов”, без глубокого погружения в детали имплементации функций. Геркин — это как бы “простая речь”, описывающая use-кейсы (что это?), и позволяющая логически описать тесты действий пользователя. Gherkin основан на Словаре Treetop, существующем на 70 языках. Поэтому вся команда может писать тесты на любом из этих 70 языков.
Но — в большинстве случаев все-таки пишет на Basic English.
Ключевые слова Gherkin
- Feature
- Background
- Scenario
- Scenario Outline Examples
- Given
- When
- Then
- And
- But
Пример синтаксиса Gherkin:
Feature: Title of the Scenario Given [Preconditions or Initial Context] When [Action/Event or Trigger] And [Join] But [Join] Then [Expected output/ Result]
Как мы переходили на Gherkin
Наша dev-команда не имела никакого опыта с BDD. Во всех наших проектах мы не задумывались о BDD, просто потому что считали “это что-то несерьезное”. Убедила нас параллельная QA-команда из другой страны, продемонстрировав на практике, как это делается, и чем эффективно.
Коллеги продемонстрировали, как их один тестировщик может писать в среднем за день 10 тестов бэкэнда. Это показалось интересным. Также показалось практичным то, что наш новый большой проект требовал проведения всех возможных автотестов (бекэнд, фронтэнд, производительности, безопасности), а команда интернациональная. На этом этапе мы уже склонились к BDD и Cucumber — как популярному фреймворку в этой сфере, с бесплатными обновлениями и (уже) большим комьюнити. Выбран был также фреймворк Serenity для управления тестами и репортов, и Kotlin как “основной” ЯП. Планировалось автоматизировать тесты функциональные/интеграционные/приемочные/сквозные, то есть как бэкэнд, так и фронтэнд.
Проект был достаточно сложным, в QA работали еще параллельно команды из Южной Азии (Индонезия) и Восточной Европы (Словакия). Это было решение для интернет-банкинга, клиенты — банки, корпорации и частные лица.
В первые месяцы QA-команда наполнялась с трудом, т.к. на рынке ощущался дефицит тестировщиков-автоматизаторов с опытом, особенно в Cucumber/Gherkin. Из-за недостатка тестировщиков мы были вынуждены набирать людей вообще без опыта в автоматизации. И тут-то сказалось удобство BDD и простота синтаксиса Gherkin, особенно что касается индонезийских тестировщиков, плохо владеющих ЯП, но имевших опыт в написании feature-файлов (изначальный “скелет” тестов), и владевших Basic English. Они сильно помогли в начале, и благодаря им остальные члены QA-отдела смогли написать и автоматизировать нужные тесты.
Далее со “скелетом” поработали бизнес-аналитики, расширили его, особенно в части приемочных тестов. Вся переписка в QA-команде была на Basic English, как и сами тесты. Тестировщики-индонезийцы разговаривали “на своем” с ручными тестировщиками, тоже индонезийцами, которые локально работали с manual-тестами. Опытные лиды знают, какой проблемой бывает коммуникация между людьми в remote-командах из далеких, иногда весьма экзотических, стран; уровня native-english ожидать не приходится, обычно это Basic English с резким акцентом. Самые блестящие тестировщики-индонезийцы сначала страдали от непонимания, что им делать, особенно это касалось бизнес-требований; manual-тестировщики сначала вообще не могли понять, чего от них хотят; BDD/Gherkin помог в таких ситуациях, стал как бы посредником, благодаря Basic English, который знают, в общем-то, все люди в ИТ — простым языком описывалось, что должно быть протестировано, и почему, и что получится в результате.
Итак, BDD/Gherkin годен, если:
- Новый крупный проект
- Требуется оперативность внесения правок (новых требований)
- QA-команды удаленные и плохо понимающие друг друга
- Бизнес-аналитики тоже бывают “местными” и их бывает мало
- В команде много людей без технического бэкграунда и много местных manual-тестеров
Практика — проект в Cucumber
Как выглядит проект в Cucumber, как выглядят автотесты в Cucumber, и чем они отличаются от обычных, не-BDD-тестов
В “стандартном”, не-BDD-проекте у нас стандартно был один Test Class (тело теста) и один Step Class (логика). В BDD-проекте обычно надо “делить” эти классы на дополнительные вложенные.
В нашем BDD-проекте Test Class был разделен на feature-файл и сам тест, а Step Class разделили на Step Definition и Steps.
Ниже показаны примеры, как это выглядит.
Feature-файл на Gherkin:
Scenario Outline: Creating requests with absence of mandatory fields When I create POST request for ACCOUNT without mandatory <param> Then expected status code for request is 400 Then I should get status code ERRORExamples: | param | | ID | | NAME | | CODE |
Создание запросов при незаполненных обязательных полях
Здесь “ACCOUNT”, “400”, “ERROR” — это параметры этапов; <param> — для повторения этапов.
Файл Step Definition: Функции с аннотациями (объяснение текста в feature-файле — логика, как мы помним, вынесена в отдельный файл)
Текст связан с кодом через аннотацию (с применением Regex-аннотации):
@When(“^I create POST request for (.*) without mandatory (\<?\w+\>?)$”)
fun i_create_post_without_param(endpoint : Endpoints, param : String) {
baseSteps.createPOSTRequest(URL.API_GATEWAY, path = endpoint,
bodyContent = JsonGenerator().generateJSON(accountGroup),
authorization = baseSteps.token)
}@Then(“^expected status code for request is (d+)$”)
fun status_code_for_request(statusCode : Int) = baseSteps.checkStatusCode(statusCode)@And(“^I should get status code (.*)$”)
fun get_status_code(statusCode : ResponseMessages) = baseSteps.validateStatusCode(statusCode)
Файл Steps: — Тестирование логики в StepDefinition-файле
Файл Test: “склеивание” feature-файла и StepDefinition-файла (это делает glue-параметр)
@RunWith(CucumberWithSerenity::class) @CucumberOptions( features = [“src/test/resources/features/film/create.feature”] plugin = [“pretty”], glue = [“com.name.stepdefinitions.film”, “com.name.stepdefinitions.common”])class Create
В glue-параметре может быть больше одного Steps / Definitions, но в Feature-файле должна быть только одна функция.
Features в Cucumber + примеры
Итак, базовые понятия есть, приступим к практике.
Background (Предыистория)
Часто бывает, что этапы повторяются во всех сценариях, связанных с Feature-файлом.
Если этапы повторяются в каждом сценарии, это значит, что эти этапы не очень важны для описания сценариев; это получаются неважные этапы. Их можно как бы “отодвинуть назад”, сгруппировав в секции Background.
Это позволяет внести некий контекст в сценарий. В секции может быть несколько этапов, которые выполняются перед каждым сценарием. Background вставляется перед первым Scenario/Example, с тем же отступом:
Background: Given I get token for admin from NETFLIX_EU appScenario: Searching fantasy film When …… Then …… And ……Scenario: Searching anime from JAPAN for each region When ……Scenario: Searching anime from JAPAN for ASIA region When ……
Regex’ы в аннотациях
В Cucumber есть альтернатива “классическим” Regex’ам (более интуитивные регексы, как считают создатели Cucumber). Но в целом, бывает достаточно “классических”.
@And(“^I have (d+) cucumbers in my belly$”) fun countCucumbers(value : Int) = baseSteps.getCucumber(value)
Здесь:
Выражение [ d+ ] допускает только целый (integer) параметр в feature-файле; когда пользователь вводит например 2,5 — выдается сообщение об ошибке в feature-файле.
Выражение [ @And(“^ ] — в каждом из элементов ( .* )-массива. “Точка со звездочкой” ( .*) служит как замена “любого символа” (так называемый “джокер”)
(Вообще, в feature-файле допустимы любые символы/цифры/знаки).
Выражение в скобках [ (was|wasn’t) ] после слова response можно писать только в такой форме (was или wasn’t) — другое написание будет некорректным.
@And(“^I should get status code (\<?\w+\>?)$”)
Regex-выражение [ \<?w+\>? ] — когда два разных типа строк, первая это стандартная строка ( “test” ), вторая — если она параметр, типа “<test>” то есть с вложенными символами. < and > — необязательный параметр.
Подробнее см. раздел документации по Regex.
Таблицы данных (Data Tables)
Таблицы данных в Cucumber применяются в Scenario Outline, когда тестовый сценарий повторяется несколько раз. Тогда не нужно инициализировать таблицы данных, Cucumber делает это автоматически:
Scenario Outline: Testing endpoint accessibility for update filmGiven I get token for <user> from <app> app When I create PUT request for FILM with all parameters Then expected status code for request is 400 And I should get status code ERRORExamples: | user | app | | maker | NETFLIX_EU | | admin | NETFLIX_AS | | regular | NETFLIX_NA |
Иногда нужно отправить еще какие-то параметры в тест-кейс, в котором шаги не будут повторяться.
And in response was displayed parameters:
| name | start_date | type | episodes |@And(“^in response (was|wasn’t) displayed parameters?$”)
fun response_display_parameters(visibility : String,
data : DataTable) = baseSteps.getParams(data)@Step
fun getParams(parameterTable : DataTable) : Map<String,Any> {
val tableMaps : MutableList<MutableMap<String,String>> = parameterTable.asMaps() val loadedValues = tableMaps[0]
val transforms = tableMaps[1]
return loadedValues.entries.map { (param,valueKey) ->
val loadedValue = if (valueKey.isNullOrEmpty()) "" else DataLoader.getValue(valueKey) val transform = transforms[param]
val finalValue = processValueTransform(transform.toString(),loadedValue)
Pair<String,Any>(param,finalValue)
}.toMap()
}
Как видим здесь, надо «прописать» этот параметр и указать тип DataType в StepDefinition-файле; это дольше и сложнее, но потом экономит время.
Больше примеров — здесь.
Как выглядят тесты на Gherkin в полностью русскоязычных проектах, можно посмотреть здесь.
***
Контрольные вопросы / Собеседование QA по Cucumber
Что такое Cucumber?
Cucumber — это огурец! А для тестировщика Cucumber — это основной рабочий фреймворк, если он работает по BDD.
А что такое BDD? Зачем нужно BDD?
BDD — это “разработка через тестирование”, специфическая Agile-методология для «разрушения технического и языкового барьера» между бизнес-аналитиками, владельцами продукта, разработчиками и тестировщиками.
Как связаны BDD и TDD?
TDD — это Test Driven Development, разработка через тестирование”. BDD-методология возникла как “продолжение” TDD. BDD основана на принципах TDD. Здесь чуть подробнее о TDD.
А чем отличается BDD и TDD?
Поскольку BDD это развитие идеи TDD, то BDD как бы направлен на устранение проблем, которые не может решить TDD. Подробный материал о BDD и TDD по ссылке.
Что такое Геркин?
Геркин (Gherkin) — это маленький соленый огурец из банки, употребляемый в качестве закуски. А для тестировщика Gherkin — это специфический язык программирования, который выглядит “почти как человеческий язык”, понятный не-технарям, при этом сохраняющий “формальность” классических языков программирования — это нужно для автоматической обработки такого текста, то есть применения в автоматизированных тестах.
Другое определение Gherkin: легко читаемый язык описания желаемого поведения системы.
Как определить, что это сценарий на Gherkin?
В структуре документа используются отступы — пробелы и табуляция, как в Python, но текст выглядит как бы “менее формально” чем в Python. Каждая строка начинается с ключевого слова и далее в ней описывается какое-то одно условие или действие. Примерно так это выглядит в русском варианте:

Что должно быть в Feature-файле?
“Высокоуровневое” описание приложения. Первая строчка feature-файла должна начинаться с ключевого слова “Feature”, далее идет описание функции. В этом файле обычно несколько сценариев. Файл должен иметь расширение *.feature.
Какие ключевые слова Gherkin знаете?
Наиболее часто применяемые:
- Given
- When
- Then
- And
Зачем нужен файл Scenario Outline в Cucumber?
Это файл с параметризацией сценариев. Когда один сценарий “принимает” много наборов тестовых данных, а этапы остаются те же.
А какие (еще) языки программирования поддерживает Cucumber?
Практически все применяемые в QA, типа Java, Python (есть библиотека Behave), есть Cucumber.js.
Обычно Feature-файлы пишутся на Gherkin, а StepDefinition-файлы — на стандартных ЯП.
(Разумеется, Cucumber может интегрироваться с Selenium.)
Зачем нужен файл Step Definition в Cucumber?
Выполняет тест по шагам-этапам и проверяет результаты. Каждый шаг (выполнения) в Feature-файле соответствует какому-то методу в StepDefinition-файле.
Сколько сценариев может быть в Feature-файле?
Максимум 10, обычно их меньше.
Сколько шагов (этапов) может быть в одном сценарии?
Не более 3, или 4.
Может ли Cucumber работать с Selenium Webdriver?
Да, может, здесь туториал (англ).
Когда меня попросили внедрить TDD / BDD в нашу работу, я много искал одностраничный документ / сайт, но не смог его найти. Хотя есть много очень хороших ресурсов по этой теме, я решил создать одну статью, чтобы продемонстрировать оба эти практических подхода.
обзор
В гибкой разработке организации хотят быть готовыми к выходу на рынок новых продуктов, функций и функциональных возможностей в течение очень короткого периода времени. Но традиционные методики тестирования не могут этого гарантировать. Чтобы не отставать от этой быстрой разработки в Agile-среде, появилось несколько новых методов проектирования для тестирования программного обеспечения. Мы можем назвать несколько таких, как ATDD, TDD, BDD или интеграционное тестирование, но мы ограничимся обсуждением TDD и BDD, которые в настоящее время являются наиболее используемой практикой.
BDD (поведенческая разработка)
Хронологически практика BDD наступает после того, как TDD вступил в действие. По сути, BDD — это эволюция над TDD. Цель этого проекта — создать мост между бизнес-аналитиками и командами разработчиков с помощью общего языка, основанного исключительно на бизнес-требованиях и гибкой практике.
BDD следует процессу, аналогичному TDD, но следует подходу Outside-In, а не TDD. Здесь тестовые случаи пишутся в начале фазы разработки. Чтобы выполнить тест, нужно выполнить тестовый пример, разработчику необходимо написать код бизнес-логики, а затем снова запустить тестовые примеры. То же самое относится и к TDD. Но разница здесь в том, что общий язык используется для описания функциональности. Давайте объясним это гибким способом.
Когда требование к техническим командам приходит к реализации, какой-то бизнес-аналитик / владелец продукта создает функцию в инструменте для совместной работы, таком как Jira или RTC. Теперь каждая функция будет иметь несколько сценариев, которые будут реализованы как критерии приемлемости. Подход BDD принимает критерии приемлемости для реализации в качестве контрольных примеров. Таким образом, пока внедряется новая функция, BDD обеспечивает преобразование всех сценариев в надлежащие тестовые случаи. Таким образом, наибольшим преимуществом подхода BDD является заполнение пробелов между нетехническими командами и командами разработчиков.
Обзор BDD Framework
В сообществе открытого исходного кода есть пара доступных платформ для практики BDD, например, JBehave, RSpec, GivWenZen и Cucumber. Но мы возьмем Cucumber, поскольку он является наиболее распространенной средой для архитектур Spring Boot и микросервисов.
Огурец
Cucumber — это библиотека с открытым исходным кодом, доступная для большинства языковых платформ, но мы сконцентрируем наше обсуждение только на Java.
Прежде чем углубляться в примеры с огурцом, нам нужно разобраться с его основами. По сути, Cucumber читает исполняемые спецификации, написанные в виде простого текста, и проверяет, что программное обеспечение выполняет то, что говорят эти спецификации. Чтобы Cucumber понимал сценарии, они должны следовать некоторым основным синтаксическим правилам, которые называются Gherkin.
корнишон
Огурец использует набор специальных ключевых слов, чтобы придать структуру и значение исполняемым спецификациям. Вы можете думать об этом как о представлении критериев приемлемости. Огурец может поддерживаться многими языками, но мы будем использовать английский в качестве справочного языка.
Строки в каждом файле Gherkin содержат ключевое слово. Ниже приведены некоторые из наиболее часто используемых ключевых слов:
-
Характерная черта
-
сценарий
-
Дано, Когда, Тогда, И, Но (известный как Шаги)
-
Примеры
Есть несколько других ключевых слов, которые мы выучим на самой работе. Очень простой пример структуры огурца ниже:
Функция: цель ключевого слова Feature — предоставить общее описание функции программного обеспечения. Это должно быть то же описание, что и эпопея или фича в Jira или RTC.
Сценарий: сценарий дает вам различные ожидаемые результаты для этих конкретных функций. Это может быть несколько случаев успеха / неудачи, как определено в Swagger.
Шаги: каждый шаг начинается с «Дано», «Когда», «Тогда», «И» или «Но». Cucumber выполняет каждый шаг в сценарии по одному в последовательности, в которую вы их записали. Когда Cucumber пытается выполнить шаг, он ищет соответствующее определение шага для выполнения.
-
Дано: вход
-
Когда: метод или функция
-
Затем: ожидаемый результат
-
И: множественный результат
-
Но: если — иначе результат
Конфигурация огурца
Достаточно терминологии и технических деталей. Давайте повеселимся с практическим кодированием. Во-первых, вам нужна любимая IDE (Eclipse, STS или IntelliJ). Мы создадим пример проекта Spring Boot из start.spring.io или воспользуемся плагином и добавим Spring Test Dependency вместе с родительским загрузчиком Starter.
Конфигурация POM
Теперь давайте настроим POM с необходимой зависимостью от Cucumber. Я использовал версию как 2.3.1, но вы также можете использовать последнюю версию.
<properties>
<java.version>1.8</java.version>
<cucumber.version>2.3.1</cucumber.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-integration</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-java</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-junit</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-spring</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
После того, как вы сконфигурируете POM, давайте запустим сборку Maven, чтобы убедиться, что зависимость введена в вашу локальную систему.
Создать файл объекта
Теперь пришло время написать Огурец в удобочитаемом огуречном файле. По сути, фреймворк Cucumber может читать файл Gherkin, но его нужно назвать файлом .feature . Итак, мы создали файл ниже в рабочей области Eclipse. Мы назвали как loginAlias.feature .
Класс записи / генерации определений шагов
Следующим шагом будет написание тестовых случаев, которые выполняют шаги, определенные в файле .feature. В основном, вы можете написать самостоятельно или использовать плагин для генерации Java-файлов StepDefs.
Вы можете скачать плагин с Eclipse MarketPlace
Как только вы установите плагин, вы можете щелкнуть правой кнопкой мыши по файлу объекта и сгенерировать файл StepDefs с помощью плагина (Запуск от имени). В консоли вы можете найти необходимые методы, которые вы можете поместить в StepExecution.class.
Поэтому, если вы видите, что Cucumber Plugin уже разработал необходимые методы для нас в консоли. Итак, нам нужно поместить эти методы в класс Test. Итак, финальный класс Test будет таким, как показано ниже:
Если вы видите пример StepExecution класса, вы заметите, что мы дали точные определения в соответствии с Given, When и Then. Единственное, что мы изменили — это шаблон Regex для вставки параметров string и int в методы. В случае несоответствия определений в файле и StepExecution классе .feature контрольные примеры не будут пройдены .
Написать класс огурцов
Теперь нам нужно написать класс Cucumber Runner, чтобы класс Runner мог напрямую запускать файлы и StepExecution класс .feature .
Итак, класс Runner начинается с того, @RunWith что запускает фреймворк Cucumber. Это так же, как @RunWith в тестировании JUnit.
@CucumberOptions поможет нам указать путь, где присутствуют все функции, а также даст нам возможность создать отчет о тестовых случаях.
Бегущий огуречный бегун
Мы все сделали с нашей первичной настройкой, и теперь мы готовы к работе. Нам нужно запустить класс Runner с тестовым примером JUnit. Но, как вы знаете, если нет реальной бизнес-логики, она всегда будет терпеть неудачу, как показано ниже.
Реализация еще не реализована в проекте, и мы можем реализовать бизнес-логику. Поэтому следующим шагом будет внедрение бизнес-логики разработчиками.
Пройти тест на огурец
В качестве альтернативы, чтобы пройти тестовый сценарий, мы можем создать сервис SoapUI Mock или написать конечную точку Mock Rest в проекте. Пример может выглядеть следующим образом:
Чтобы пройти тестовый пример, нам нужно расширить этот абстрактный класс в нашем классе StepExecution, и теперь мы можем вызвать конечную точку, созданную AbstractSpringConfigurationTest классом. Таким образом, измененный StepExecution файл класса выглядит следующим образом:
Теперь, если мы запустим класс Runner с JUnit, он должен пройти и показать, как показано ниже:
Надеемся, что с этим объяснением мы сможем вкратце понять основы BDD & Cucumber.
The difference between BDD and TDD
BDD stands for behaviour driven development. TDD stands for test driven development.
Both BDD and TDD refer to the methods of software development employed by your engineering team. There are broadly 2 mainstream approaches to development: test driven development is one and behaviour driven development is the other.
Test driven development
Test driven development is primarily concerned with the principle of unit testing. That is, testing specific, individual units of code.
Your product’s codebase is made up of small units of code which are responsible for specific parts of your application. Testing individual units of code is known as ‘unit testing’ and you may have heard your engineering team refer to unit tests.
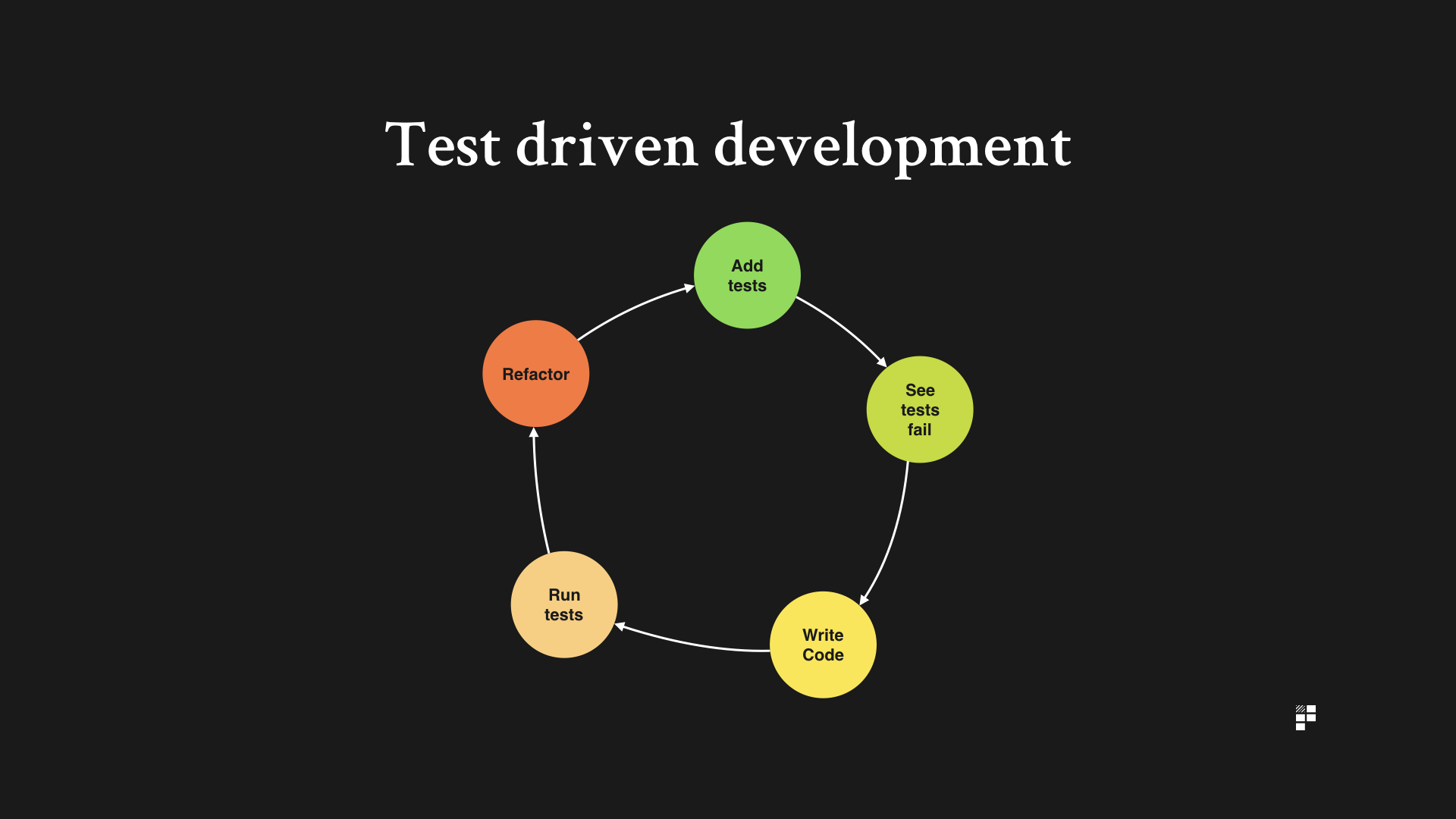
There are several stages and principles to be followed in test driven development. These stages and principles are summarised here:
- All tests are written before the code
- Write a test
- Run all tests to check that the new test fails
- Write the code
- Re-run the tests
- Refactor the code if necessary
- Re-run the tests
The primary focus in test driven development is to ensure that the unit tests pass and that the ‘build’ is green. What’s the build? Well, every time your engineering team add a new feature or story, they are adding it to ‘the build’. This works like adding a new frame to a movie. The build – the entire movie – is comprised of individual, specific frames and when a new frame is added, test are run to ensure the entire movie plays as it should.
If everything passes, this is typically known as the build being ‘green’. If the tests do not pass, the build is ‘red’ – something has broken and it needs to be fixed before your engineering team can proceed.

The term ‘code coverage’ refers to the amount of your codebase which is covered by these types of tests. Your engineers, CTO and other technical leaders in your organisation will refer to code coverage targets as an aspirational target to achieve.
Benefits of TDD
- Short debugging time / effort – When a unit test fails, you’ll know exactly what specifically has failed.
- Safety net – tests become a safety net for the team – this can increase morale between engineers and bolster confidence in your engineering team.
- Less bugs – more unit tests can often reduce the number of defects
However, focusing exclusively on the code itself i.e. the technical aspects of a system, disregards the human, or behavioural aspect of your application.
Behaviour driven development
Behaviour driven development is different to test driven development. The 2 approaches are not necessarily mutually exclusive and are often used together.
The primary goal of behaviour driven development is to solve the problem of communication between the business (including the product manager), the engineering team and the machines.
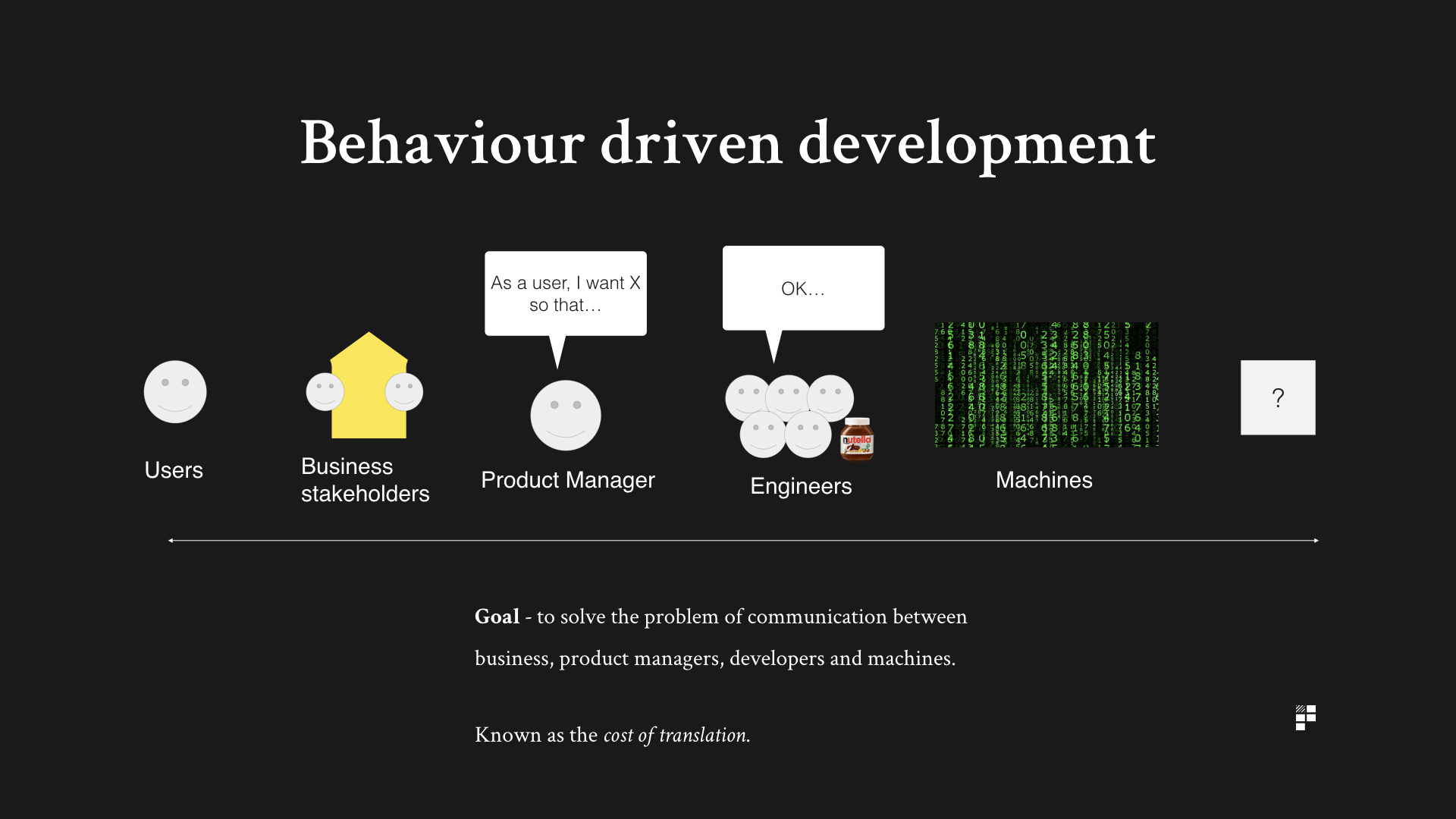
If you think about a recent feature that’s been pushed to production, by the time a feature is deployed to production it will have moved through numerous stages, each with their own filters and interpretations. This set of chinese whispers is known as the cost of translation. The aim of behaviour driven development is to reduce the cost of translation.
Broadly speaking, BDD is meant to eliminate many of the issues that TDD introduces. BDD tests use a more verbose language so that they can be read almost like you would read a sentence. The ability to read tests like a sentence is a cognitive shift in how you think about your tests.
The argument is that if your engineers can read their tests fluidly, they will write better and more comprehensive tests. It’s often said that BDD is to help design the software, not test it and that TDD is meant to test it. Either way, BDD principles can help you and your team shift your mindset towards the behaviour of your product so that testing isn’t from a purely technical perspective.
Principles of BDD
- BDD encourages simple languages to be used across teams, known as ubiquitous languages.
- The simple and easy to use language should be used in the way the tests themselves are written, so that in theory, a business person can read a test and understand what it is testing.
- Tests are often written from the customer’s point of view; the focus is on the customers and the users who are interacting with the product
Benefits of BDD
- Simple language – the straightforward language is usable/understandable, not only by domain experts, but also by every member of the team.
- Focus – BDD helps teams focus on a product’s behavioral elements rather than focusing on testing the technical implementation in isolation through individual units. This subtle, but important shift, means that everyone is focused on what the behaviour of the product should be.
- Using Scenarios – BDD is designed to speed up the development process. Everyone involved in development relies upon the same scenarios. Scenarios are requirements, acceptance criteria, test cases, and test scripts all in one; there is no need to write any other artifact.
- Efficiency – BDD frameworks make it easy to turn scenarios into automated tests. The steps are already given by the scenarios – the automation engineer simply needs to write a method/function to perform each step’s operations.
How to write BDD scenarios
Your first question is probably ‘what are BDD scenarios?’. That’s a fair question!
A BDD scenario is a written description of your product’s behavior from one or more users’ perspectives. Scenarios are designed to reduce the cost of translation and make it easier for your engineers to understand the requirements and for your QA (if you have one) to test it properly.
Using BDD scenarios means requirements and tests can be combined into 1 specification. In some cases, the scenarios that are written can then be easily converted into automated tests. BDD scenarios tend to follow a specific format. The format is fairly straight forward, and with a little practice you’ll be able to write your own.
In order to explain how BDD and scenarios work in practice, let’s take a look at the example of a user signing up to LinkedIn.
Example – signing up for a LinkedIn account
Here’s a basic BDD scenario which describes the LinkedIn signup process:
Scenario 1: User successfully creates a LinkedIn Account
- GIVEN John is on the LinkedIn Registration page
- WHEN he enters all required registration fields
- THEN a LinkedIn account is created
Let’s take a look at what’s going on here.
The first thing you’ll notice is the header ‘Scenario 1: user successfully creates a LinkedIn Account’. All written BDD scenarios should be given a header which accurately describes the scenario you’re interested in. You may have a few scenarios to assist your engineers / QA team and without headers things can get messy.
The second thing you’ll notice is the use of 3 words: GIVEN, WHEN, THEN. They don’t necessarily need to be in capital letters but, in a similar way to SQL, sometimes keywords are made more clear if they’re in caps.
GIVEN, WHEN, THEN
In its simplest format, there are 3 key elements in any BDD scenario:
GIVEN (describing the context)
WHEN (describing the action)
THEN (describing the outcome)
These 3 elements help to describe the behaviour of the system using context, actions and outcomes. If you have more than one or you require more information than this, you can add them with AND.
Using ANDs
When you require more information in a scenario, an ‘AND’ can be used after any of the descriptors:
GIVEN (context),
AND (further context),
WHEN (action/event),
AND (further action/event),
THEN (outcome)
AND (further outcome)
Make sense?
OK, let’s revisit our LinkedIn registration scenario and flesh it out in more detail with a few ANDs.
GIVEN John is on LinkedIn Registration page
WHEN he enters all the required registration information
AND he hits ‘join now’
THEN his LinkedIn account is created
AND he is directed to the profile creation page
AND his confirmation email is sent
How do BDD scenarios work with user stories?
Your BDD scenarios should form part of 1 specification. This includes both the user story and the scenarios. So, for example, if you’re writing a user story in Jira or some other beloved backlog management tool you could structure your specification in Jira in the following order:
- User story – start with the user story describing the requirements from a user’s perspective
- BDD scenarios – then include your scenarios describing the behaviour of the system to assist with testing
A user story has a slightly different structure to your BDD. Your user story should comprise the following:
As an X
I can / want Y
So that Z
Using our LinkedIn example:
As a new user (John), I can register a new account on the homepage so that I can access LinkedIn.
Your BDD scenarios would then follow:
Scenario 1: User successfully creates a LinkedIn Account
GIVEN John is on LinkedIn Registration page
WHEN he enters all the required registration information
AND he hits ‘join now’
THEN his LinkedIn account is created
AND he is directed to the profile creation page
AND his confirmation email is sent
If you have multiple scenarios, you’d add these after Scenario 1 in a sequence.
When should BDD scenarios be used?
BDD scenarios are not necessarily mandatory across all of your product specifications. If they were you’d spend most of your life writing BDD scenarios which would clearly be very unpleasant.
BDD scenarios are best suited to specifications where you think there is a likelihood that the requirements may be misunderstood without them or that a more thorough testing approach needs to be adopted. If you’re working on a small color change, text change or a technical chore / bug, there will clearly be no case for using BDD scenarios as this would be a waste of everyone’s time.
It may be that you as a team decide to write them for all major new feature stories or that you only focus on a specific type of specification. BDD scenarios can assist you in your development process but as with all things product, you and your team should decide on what works best for you.
Reading time: 11 minutes
This is a guest article by Ron Stefanski from OneHourProfessor
When launching new digital projects, the frequent disconnect between business professionals and engineers often results in tons of squandered time and resources. But, with the right strategy, this black hole can be avoided by improving communication, an effective way to prevent most bottlenecks to project progress.
When business professionals understand the capabilities of the technical team, and the engineers understand what the business truly requires from the software, it results in the creation of software with real business value.
But how do you achieve all this? That’s where behavior-driven development (BDD) comes in.
This article will discuss the nature of behavior-driven development and how it can be used successfully by an organization to assist its technical team in delivering software that fulfills its goals.
What is Behavior-Driven Development (BDD)?
Behavior-driven development can be defined as a way to synthesize and define practices that stem from test-driven development (TDD).
BDD is several things:
- It’s a language used to define the behavior of an application.
- It’s a collaboration tool for product managers, engineers, and testers.
- It’s a system for automatically testing those behaviors.
BDD was created over a decade ago by Dan North, a technology and organizational consultant from London, as a way to clear confusion between developers, testers, and business people. Although it started as a simple modification of test-driven development, BDD is now a full-blown software development methodology.
The BDD approach is often divided into two main parts:
- The first part involves using examples that are written in ubiquitous language as a way to illustrate behaviors or the different ways users interact with the product.
- The second part is the practice of utilizing those examples as a basis for automated tests. In addition to allowing developers to check functionality for the user, it also ensures that the overall system works precisely as defined by the business for the project’s entire lifetime.
Behavior-driven development closes the gap and provides an easier way to collaborate and communicate between different departments so they can manage and deliver software development projects more effectively. BDD ensures that the development projects remain focused on the actual needs of the business while, at the same time, meeting the requirements of the user.
How does it do that?
- By encouraging collaboration across different roles to build a shared understanding of the problem that must be solved.
- By working in small, rapid iterations to increase feedback and enhance the flow of value.
- By producing system documentation that can be automatically checked against the behavior of the system.
This is done by focusing collaborative work on concrete, real-world examples illustrating the way the system is required to behave. Those examples are then used as a guide from concept all the way through to implementation as part of a continuous collaboration process.
What Are the Benefits of BDD?
In BDD, acceptance tests are the starting point for software design. They serve as the basis for communication between stakeholders and the development team.
The biggest challenge software projects face is making certain everyone involved can share a common language. That’s why while building, it may make sense to use a webinar platform to connect all stakeholders to clarify requirements. And therein lies the true benefit of BDD as a powerful communication tool to drive better cooperation between everyone involved – both technical and nontechnical.
With behavior-driven development, everyone on the team can read and write acceptance tests. It’s the developer’s code that automates the tests, but business stakeholders can understand it.
Here are a few other benefits offered by BDD:
- Strong Collaboration. Thanks to the shared language, product owners, developers, and testers all have in-depth visibility of the project’s progression.
- Shorter Learning Curve. Since BDD is explained using very simple language, there’s a much shorter learning curve for everyone involved.
- High Visibility. Being a nontechnical process by nature, behavior-driven development can reach a much wider audience.
- Rapid Iterations. BDD allows you to respond quickly to any and all feedback from your users so you can make improvements to meet their needs.
- BDD Test Suite. Similar to adopting TDD, adopting BDD gives your team confidence in the form of a test suite.
- Eliminate Waste. BDD allows you to clearly communicate requirements so there’s less rework due to misinterpreted requirements and acceptance criteria.
- Focus on User Needs. Satisfied users are good for business and the BDD methodology allows user needs to be met through software development
- Meet Business Objectives. With BDD, each development can be traced back to the actual business objectives.
BDD creates code through the various interactions between users and developers — a process known as “outside-in” development. This means that examples are created that describe software behavior that is evaluated by the user. This is critical to the software development project. Managers clarify responsibilities, mockups help to simulate different system modules before actually writing them, and the use of these tests serves as an opportunity for fast, actionable feedback prior to the development.
Most importantly, behavior-driven development improves the quality of code which helps to reduce costs of variable expenses like maintenance and minimizes project risk.
Also, BDD is a tool that helps all departments clarify the scope of the desired software features so they can get better estimates from development teams.
All in all, BDD practices are a powerful tool to help teams develop better software by demanding prudent specificity of product behaviors using examples in plain language.
What Are the Disadvantages of BDD?
BDD makes it very clear that software development must be done from the interface that is in contact with the end-user (hence the name, outside-in development).
This methodology focuses on the benefits the app will bring to the business. Whether you are yet to implement BDD or if your team is already using TDD and wants to consider BDD, it’s clear to see that the benefits of development are many. But even the best development approaches have their drawbacks, and BDD is no exception.
Although according to its creator, the methodology was designed to address recurring problems in the teaching of test-driven development, it’s clear that behavior-driven development requires familiarity with a wider range of concepts compared to TDD.
Here are a few other common pitfalls of BDD:
- To work in BDD, prior exposure to TDD concepts is required.
- Behavior-driven development is not compatible with the waterfall approach.
- Testers using BDD must have sufficient technical expertise.
- BDD may not be effective if the requirements aren’t meticulously specified.
Keep in mind that using BDD doesn’t require particular program languages or tools. It’s primarily a conceptual approach, and so making it a purely technical practice or even one that is dependent on specific tools means that you’ve missed the point altogether.
Implementing the BDD Approach – Three Practices
Day-to-day BDD activity involves a three-step, iterative process that includes discovery, formulation, and automation (practices that we will take a closer look at below). Over time, these documented examples become assets that help your team to confidently make rapid changes to the system. In this constantly evolving and shared understanding, the code reflects the documentation, which, in turn, reflects everyone’s shared understanding of the problem space.
Step 1: Discovery – What It Could Do
The real objective here is to get valuable, working software for the business. The fastest way to achieve that is by having conversations between all the people involved in the imagining and delivery of the software.
To this end, the first step is to take an upcoming change to the system, known as the user story, and discuss concrete examples of new functionalities to explore. It may make sense to use email marketing tools to survey your users and collect the ideas that they have before you take any action.
This is where everyone involved learns about and agrees to the various details of the expected goals to be achieved.
Test scenarios are written in plain language that everyone can understand, with a detailed description of:
- The actual test
- How to test the application
- The application behavior
As outlined in the benefits above, BDD test cases have the advantage of being written in plain language, ensuring that the details of the app’s behavior are easily understood by all.
For instance, test cases can be written in a simple way using real-time examples of actual requirements as a way to explain the behavior of the system.
Structured conversations, also known as discovery workshops, are used to focus on the system and real-world examples from the perspective of the user. These conversations help to grow the team’s shared understanding of the user’s needs, as well as the scope of what has to be done, and the rules governing the way the system must function.
Step 2: Formulation – What It Should Do
The next step involves documenting those examples in a way that can be automated. You can then check for agreement.
As soon as one valuable example is identified from the discovery sessions, each example can then be formulated as structured documentation. This gives everyone involved a quick way to confirm that they really do have a shared understanding of what needs to be built.
Unlike traditional documentation, BDD uses a median that can be easily read by both computers and humans in order to achieve the following:
- Get feedback from the whole team pertaining to the shared vision of what’s being built
- Automate examples to guide the team’s development of the implementation
This executable specification is written collaboratively to establish a shared language for discussing the system, helping teams to use problem-domain terminology everywhere, including the code.
Step 3: Automation – What It Actually Does
The final step is to implement the behavior described in each documented example, beginning with the automated test that will guide the development of the code. Once the team has its executable specification, it can then be used to guide the development of the implementation. Each example can now be connected to the system individually as a test. This test fails since the behavior it describes hasn’t been implemented yet.
The next step involves developing the implementation code. Lower level examples outlining the behavior of various internal system components are used as a guide wherever necessary. These automated examples serve as guardrails to help teams keep development work on course.
This rapid and repeatable feedback helps to reduce the burden of having to perform manual regression testing which, in turn, helps to free people up to focus on more interesting work, such as exploratory testing.
The diagram below outlines the three practices of discovery, formulation, and automation:
Three practices of behavior-driven development
Source: Cucumber docs
The idea behind this three-step process is to make each of the changes small and iterate rapidly. You can move up a level each time more information is required. Every time a new example is automated and implemented, it means you’ve added something valuable to the system and are therefore ready to respond to feedback.
Best Practices for BDD
Online, you’ll find tons of articles on BDD best practices and anti-patterns. But, with thousands of tips (and sometimes conflicting pieces of advice), how do you which rules are sacred and which are meant to be broken?
To help you in that regard, here are some best practices for BDD that you should keep in mind. We’ve divided the tips into different categories to cover:
- Feature files
- Background
- Scenarios and steps
- Tags
1. Avoid Lengthy Descriptions
All features should have only a sensible and short title and description. Feature descriptions that are long are often boring to read and tend to put off stakeholders. As a general rule, features should be a concise sentence that describes the scope and context.
2. Choose a Single Format for Your Features
Another best feature for behavior-driven development is to decide the types of formats that you use for writing features.
The format you choose should be consistent across all feature files. This makes it easy for anyone who is new to the project to easily understand the features and context.
For instance, you might have the following template:
Feature: [A short line describing the story]
[Optional – Feature description]
Scenario: [A single line describing the scenario]
Given [Context]
When [Event]
Then [Outcome]
3. Keep the Background Short
Whenever possible, continue to use a background for shared steps that are required for each scenario in your feature file. The background gets rid of many of the repetitive steps and its proper use can help you avoid duplication in feature files. Keep your background short, ideally no longer than four lines. It should act as a prerequisite for every scenario in the future file.
Users tend not to think about the background when reading scenarios within the feature files so make sure you use something that’s very generic, such as Given the user has logged in.
4. Avoid Using Technical Language in the Background
Make sure you avoid using technical stuff (language or actions) during the background step. For instance, you shouldn’t have a background step for things such as starting/stopping Apache, clearing the cache, truncating database, etc. since users don’t really care about these things.
You can implement any of the technical actions you need to do in the before hook or step definitions instead.
5. Don’t Tag the Background
Never tag the background, only the scenarios, and features. Also, never use the background for feature files that contain just one scenario. This doesn’t make sense since you can include the details directly in the GIVEN step.
Another thing to avoid is the use of both before hook and background at the same time. There are times when there can be duplication of context when there’s a background within the feature file, as well as a before hook within the code. So make sure you use either one or the other, but never both.
6. Consider Scenario or Scenario Outline
A tool like Gherkin provides a way to deal with single examples using a “scenario,” as well as the means to deal with multiple examples using a “scenario outline.”
Decide how many examples you’re going to think of for each particular scenario. If the scenario can only have one example, then you can use “scenario.”
In any other instance, you can use “scenario outline” to cover multiple examples. You can use the table for this. And proper use of scenario outlines will also help to make your scenarios a lot more readable and maintainable, as well as prevent you from duplicating steps.
7. Keep Scenarios Short
Another best practice for BDD is to hide implementation details and avoid using technical details in order to keep scenarios short. Long and descriptive scenarios that include lots of “AND” or “BUT” steps become brittle and less readable.
So while your steps should not include the implementation details, they should have enough description for the context of the scenario to be clear.
8. Use the Given-When-Then Formula in the Right Order
When writing scenarios, use the right sequence for the GIVEN-WHEN-THEN steps (with the proper use of “AND,” and “BUT”).
This style of writing makes it easy for anyone to understand since it doesn’t contain any implementation details. It also highlights the reasons why a specific feature is important for any given persona.
Always start the scenario using the GIVEN step (do this even if you used it in the background section).
For instance:
Given [some context]
When [some action or event occurs]
Then [some outcome occurs]
The proper sequence of this formula is important because scenarios become a lot less readable when the order of GIVEN-WHEN-THEN is missed.
9. Cover Happy and Non-Happy Paths
Your scenarios need to cover not only the happy path where the user has a straightforward journey but also the non-happy paths that cover different edge cases surrounding the happy path.
This includes invalid inputs, among other things. It’s important to cover both paths and ensure that scenarios that are implemented have business values (ROI).
10. Points To Consider for “Tags”
Tagging lets you organize features and scenarios properly in your BDD project. If your feature files span across different directories, then you can use tags to help filter specific scenarios of features.
For instance, say you have a set of scenarios for Gmail, you can then use the “@mail” tag to mark those scenarios. That way, you can easily search for the @mail tag.
Here are a few more tips concerning tags:
- Use Relevant Tag Names: For instance, you can use @daily, @hourly, or @nightly for frequency of execution. Likewise, progress can be labeled using @wip, @todo, @implemented, or @blocked, and so on.
- Tagging Features Smartly: You can tag individual scenarios, but tagging an entire feature may be useful in some instances. For instance, you might tag a feature using a story number (e.g. @Jira-story #PROJ-43) in JIRA or any other bug tracking system.
- Avoid Unnecessary Tag Use: Don’t tag a scenario using the same tag that you used for a feature. If you’ve tagged an entire feature, then the scenarios inside the feature automatically inherit the tag. So you should never use a lot of unnecessary tags in your project or the result will be overcomplication of your feature files.
Remember: Practice Makes Perfect
When dealing with behavior-driven development, there are a ton of rules that you can use as guiding principles, but only practice will allow you to become an expert in this smart approach in agile methodology.
Use this guide as your resource to learn everything you need to know about BDD to drive collaboration among customer representatives, quality assurance testers, and developers in your next software project.
Did this guide effectively answer all your questions about behavior-driven development? Are there any areas of BDD you’d like to learn more about? Share your thoughts in the comments below!

Ron Stefanski is a college professor turned online business owner. He’s helped hundreds of thousands of people create and market their own online business. You can learn more about him by visiting OneHourProfessor.com. You can also connect with him on YouTube or Linkedin.
Want to write an article for our blog? Read our requirements and guidelines to become a contributor.