Афоризм
Ничто не вечно по луною,
завел мой врач издалека.
Поддержка проекта
Если Вам сайт понравился и помог, то будем признательны за Ваш «посильный» вклад в его поддержку и развитие
• Yandex.Деньги
410013796724260
• Webmoney
R335386147728
Z369087728698
ant (анг. муравей) — это мощный платформо-независимый скриптовый инструмент, используемый для сборки
приложений. Сценарий сборки приложения java оформляется в виде XML-файла подобно скриптам «make» при обработке
файлов С/С++. По-умолчанию сценарий сборки извлекается из файла build.xml.
Пример описания сценария сборки :
- копирование *.jar файлов в каталог релиза, но перед этим необходимо
- сформировать *.jar файлы, но перед этим необходимо
- скомпилировать java-файлы в файлы *.class
Сценарий сборки ant‘у показывает что надо делать, чтобы превратить из того, что есть (как правило,
исходный java-код) в то, что необходимо. Сценарий представляет собой детальный план сборки из частей единого
целого, включающий ряд операндов, позволяющих выполнять команды копирования, удаления и перемещения файлов,
компиляции java-файлов, формирование документации к коду и исполняемого jar-файла.
Структура сценария сборки — ant project, basedir, target
Корневой элемент сценария project может содержать три необязательных атрибута :
- name — имя проекта;
- default — цель проекта по умолчанию;
- basedir — базовая директория, относительной которой будут вычисляться все пути.
Элемент описывающий цель проекта target может содержать следующие атрибуты :
- name — имя цели, обязательный атрибут;
- depends — промежуточные цели, от которых зависит данная цель; имена перечисляются через запятую;
- if — определяет какие свойства должны быть равны true для запуска цели;
- unless — определяет какие свойства должны быть равны false для запуска цели;
- description — краткое описание цели, что она делает.
Параметр property определяет пару имя/значение, которая может многократно использоваться в сценарии
подобно переменным. Свойства (настройки) можно определять как внутри build.xml файла, так и в отдельных
файлах. При определении внутри xml файла свойства могут включать следующие атрибуты :
- name — имя свойства;
- value — значение свойства;
- location — устанавливает значение свойства в абсолютный путь. Если значение уже абсолютный путь, то ничего
не меняется, если относительный то подставляется базовая директория. Символы / и меняются автоматически
в зависимости от платформы; - refid — ссылка на другой объект, определенный где-либо;
- resource — имя ресурса содержащего настройки в формате настроечного файла;
- file — путь к файлу настройки (в нем свойства определяются как имя=значение на отдельной строке);
- url — адрес настройки;
- environment — префикс используемый для доступа к переменным окружения. Например, если определено myenv,
то к переменным обращаются как «myenv.PATH»; - classpath — путь к ресурсам;
- prefix — префикс добавляемый к свойствам загруженных из файла, ресурса, или url. По умолчанию префикс «.».
Шаблон простейшего сценария :
<project name="FirstProject" default="clean.jar" basedir=".">
<target name="path">
<property name="srcDir" value="D:ProjectsmyProjectsrc" />
<property name="dstDir" value="D:ReleasemyProject" />
</target>
<target name="clean.jar" depends="path">
<echo>Delete all *.jar files</echo>
<delete file="$ {dstDir}*.jar" />
</target>
</project>
Согласно представленному сценарию ant‘у необходимо удалить все *.jar файлы из
директории d:projectsbin.
В примере сценарий сборки содержит тег проект project, включающий несколько заданий target.
Первая строка примера содержит общую инфомацию о проекте. Самые важные атрибуты проекта project
это элемент наименования задания (значение default) и базовая директория basedir.
Атрибут basedir указывает на базовую директорию, от которой будут вычисляться относительные пути,
используемые в сценарии сборки. Каждый проект может иметь только один атрибут basedir, поэтому можно
указывать либо полные пути, либо разбивать сценарий на несколько файлов сборки, в каждом из которых указывать
свою базовую директорию. Атрибут default указывает на задание target, определенное для выполнения
по-умолчанию.
ant работает из командной строки поэтому необходимо определить переменную окружения ANT_HOME,
указывающую корневую директорию приложения.Для запуска ant’a на выполнение сценария необходимо правильно описать
команду. Примеры вызова Ant’а для выполнения сценария:
- ant -buildfile simple.xml clean.jar
- ant -buildfile simple.xml
- ant compile
- ant
В первом и втором примерах сценарии сборки определены параметром -buildfile и представлены в файле
simple.xml. В третьем и четвертом примерах сценарии сборки представлены в файле build.xml,
наименование которого используется по-умолчанию. В первом примере выполняется сценарий с заданием clean.jar,
в третьем сценарии — compile. Во втором и четвертом примерах Ant выполняет сценарии, определенные по
умолчанию.
Определение свойств задания, ant property
Свойства в сценарии ant – это аналог переменных в программировании. Каждое свойство имеет два
параметра :
- name – имя свойства;
- value – значение.
Примеры определения свойств для секций, property :
<target name="path">
<property name="srcDir" value="D:ProjectsmyProjectsrc" />
<property name="dstDir" value="D:ReleasemyProject" />
<property name="classpath"
value="C:oracleora92jdbclibojdbc14.jar" />
</target>
Использовать свойства очень просто, для этого нужно имя свойства написать между символами
$ { ‘property.name’ }. Например, выражение: $ {dstDir}/src будет преобразовано
в «D:ReleasemyProjectsrc».
Создание директории, ant mkdir
<target name="make.dir" description="Make a dir" depends="path">
<echo>Make a directory</echo>
<mkdir dir="$ {dstDir}" />
</target>
В представленном задании «make.dir» ant должен создать директорию
«D:ReleasemyProject», определенную атрибутом «dstDir».
Копирование файлов, ant copy todir
Представленный сценарий решает задачу копирования файла myProject.ini из директории
проекта prjDir в директорию сборки проекта basedir.
<target name="copy" description="Copy ini file" depends="path">
<echo>Copy *.ini files</echo>
<copy todir="$ {basedir}">
<fileset dir="$ {prjDir}">
<include name="**/myProject.ini">
</fileset>
</copy>
</target>
Команда «copy» включает вложенный элемент <fileset>, который определяет группу файлов. Файлы, которые
включаются в эти группы, располагаются в поддиректориях относительно базовой, определенной атрибутом basedir
корневого элемента project.
Для файлов может быть указан набор масок patternset, по которым будут отбираться файлы. Шаблон patternset может
быть включен как вложенный элемент <patternset> в элемент fileset и иметь атрибут id, по которому можно
ссылаться на данный набор из других мест сборки. Например:
<patternset id="sources">
<include name="**/*.java>
<exclude name="**/*test*>
</patternset>
Элементы include и exclude указывают на маски (фильтры), результат применения которых следует включать
и не включать в набор.
Компиляция java-файлов, ant javac
Следующие задания сценария сборки решают задачу компиляции java-файлов. Элемент srcDir определяет
директорию с файлами исходных кодов. Если java-файлы располагаются в поддиректории, то после фигурных скобок
и «слеша» необходимо указать поддиректорию.
<target name="common" depends="path">
<echo>Compile common java files</echo>
<javac srcdir="$ {srcDir}common">
<destdir="$ {dstDir}">
<deprecation="off">
<include name="*.java" />
</javac>
</target>
<target name="compile" depends="path,common">
<echo>Compile sql files</echo>
<javac srcdir="$ {srcDir}sql">
<destdir="$ {dstDir}">
<deprecation="off">
<classpath="$ {classpath}">
</javac>
</target>
Элемент destDir определяет директорию назначения. Если в исходных java-файлах указан пакет package,
то откомпилированные class-файлы будут располагаться в соответствующих поддиректориях.
Второе задание compile зависит от первого задания common согласно значения атрибута depends,
в связи с чем при вызове ant‘а с флагом compile первоначально будет выполнено первое задание.
Для выполнения второго задания, т.е. для компиляции файлов, необходимо использовать дополнительные библиотеки,
упакованные в .jar файлы, в связи с чем путь к этим библиотекам указывается в элементе classpath.
Существует 2 особенности задачи компиляции java-файлов javac. Во-первых, можно не указывать непосредственно
имена java файлов — достаточно просто указать каталог. Во-вторых, если ant определит, что class файл
существует и новее, чем java файл, то компиляция будет проигнорирована. Эти две особенности являются примерами
приемов сборки приложения.
Формирование .jar файла, ant jar
Java приложения, как правило, поставляются упакованными в jar файлы. ant использует команду «jar» для
создания архивов :
<target name="jar" depends="compile">
<echo>Make jar file</echo>
<jar destfile="myProject.jar">
<fileset dir="$ {dstDir}">
<include name="**/*.class">
<exclude name="**/CVS">
</fileset>
</jar>
</target>
В представленном задании сценарий формирования файла jar зависит от задания компиляции compile.
Упакованный архив в виде файла myProject.jar будет включать все поддиректории с файлами, расположенными
в директории dstDir.
Определение манифеста приложения
ant позволяет вставить в сборку готовый файл манифеста manifest.mf.
<target name="dist" depends="compile" description="Create jar-file">
<jar jarfile="$ {dist}/myProject.jar" basedir="$ {buildSrc}"
manifest="$ {src}/manifest.mf"/>
</target>
Но можно также определить содержимое манифеста:
<target name="jar" depends="compile"
description="Generates executable jar file">
<jar jarfile="myTest.jar">
<manifest>
<attribute name="Main-Class" value="soft.test.MainForm"/>
<attribute name="Class-Path" value="."/>
<attribute name="Rsrc-Class-Path"
value="./ commons-beanutils.jar
derby.jar json-lib.jar ..."/>
</manifest>
<fileset dir="build" includes="**/*.class"/>
<fileset dir="src" includes="**/*.properties"/>
</jar>
</target>
Запуск приложения, ant fork
Ант позволяет запускать приложение. Для этого необходимо определить параметры приложения и свойству
fork присвоить значение «true». Определим задание для запуска создаваемого jar-файла.
<target name="run" depends="dist" description="Run program">
<java jar="$ {dist}/myProject.jar" fork="true"/>
</target>
Следует обратить внимание, что параметр depends имеет значение dist. Поэтому, пока архив
не создан, запускать нечего. Запуск программы осуществляет тег «java». Его параметр jar указывает, что мы
хотим запустить программу из jar-архива. Параметр fork имеет значение true, это означает, что для
запуска программы мы используем отдельную виртуальную машину (обязательное требование при запуске из
jar-файла).
Задание с тестами, JUnit
Следующая задача запускает тесты (если они были созданы прежде).
<target name="test" depends="compile">
<junit fork="yes" haltonfailure="yes">
<classpath>
<pathelement location="$ {buildTest}"/>
<pathelement location="$ {buildSrc}"/>
</classpath>
<formatter type="plain" usefile="false" />
<test name="tools.utils.Class1Test"/>
<test name="tools.utils.Class2Test"/>
</junit>
</target>
Внимание. Для того, чтобы работала эта задача нам нужно рассказать ant где находится библиотека
junit.jar. В документации к ant описывается три различных способа, которые позволяют это сделать.
Самый простой способ — это копирование файла junit.jar в папку ANT_HOME/lib.
Тестирование выполняется в теге junit, который имеет два параметра:
- fork – запускает тесты в отдельной виртуальной машине;
- haltonfailure – останавливает выполнение, в случае если тест не проходит.
Содержимое тега classpath определяет размещение скомпилированных тестов и классов, которые они
трестируют.
Тег formatter задает параметры отображения результатов тестирования. Параметр type=»plain» указывает,
что результаты тестирования должны отображаться в виде обычного текста, а параметр usefile=»false»
обеспечивает вывод результатов на экран, а не в файл.
С помощью тега test запускается тест. В параметре name указывается наименование теста.
Архивирование файлов, ant zip
Для архивирования файлов необходимо использовать в задании тег zip.
<target name="packSrc">
<zip destfile="myProject_Src.zip">
<fileset dir="." includes="**/*.java, **/*.mf, **/*.xml"/>
</zip>
</target>
С помощью параметра destfile задаем имя архива. А вложенный тег fileset позволяет
указать перечень файлов, которые войдут в архив.
Согласно заданию в архив включаем только исходные коды java и файлы с расширениями mf, xml.
Атрибут dir задает стартовую папку, includes – указывает шаблоны выбора файлов в архив
(«**» — означают любую папку, «*» — любое количество любых символов в имени файла).
Очистка временных директорий, ant delete
Для очистки временных директории и удаления файлов необходимо использовать тег delete.
С её помощью можно удалить результаты работы всех предыдущих задач и оставить только исходники.
<target name="clean">
<!-- удалить директорию -->
<delete dir="build"/>
<delete dir="$ {dist}"/>
<!-- удалить файл -->
<delete file="test.zip"/>
<!-- удалить файлы и поддиректории, но не саму директорию build -->
<delete includeemptydirs="true">
<fileset dir="build" includes="**/*"/>
</delete>
<!-- удалить *.bak файлы в текущей директории и поддиректориях -->
<delete>
<fileset dir="." includes="**/*.bak"/>
</delete>
</target>
Тег delete удаляет папку и её содержимое. Параметр dir задает имя папки. В последнем
теге параметр file определяет имя файла.
Обратите внимание, что в первом теге delete имя папки указывается явно (не используя параметры),
что позволяет за один раз удалить папки build/classes и build/tests.
Перемещение и переименование файлов/директорий, ant move
Для переименования и перемещения файлов или директорий необходимо использовать move.
<!-- переименование файла -->
<move file="file.orig" tofile="file.moved"/>
<!-- переместить файл в другую директорию -->
<move file="file.orig" todir="dir/to/move/to"/>
<!-- перемещение директории -->
<move file="src/dir" tofile="new/dir/to/move/to"/>
<!-- перемещение группы файлов -->
<move todir="some/new/dir">
<fileset dir="my/src/dir">
<include name="**/*.jar"/>
<exclude name="**/ant.jar"/>
</fileset>
</move>
<!-- добавление .bak к именам файлов в директории -->
<move todir="my/src/dir" includeemptydirs="false">
<fileset dir="my/src/dir">
<exclude name="**/*.bak"/>
</fileset>
<mapper type="glob" from="*" to="*.bak"/>
</move>
Создание документации, ant javadoc
ant можно использовать для создания документации java-приложения. Пример задания приведен на странице
javadoc.
Подробная информация формирования документации представлена на странице
Javadoc/Javadoc2
В этой статье я хотел бы рассказать как можно создавать сценарии сборки имиджей для Docker контейнеров с помощью системы многоцелевых сценариев Sparrow*.
(*) Примечание — для понимания некоторых технических нюансов данной статьи желательно иметь хотя бы поверхностное знакомство с системой многоцелевых сценариев Sparrow, краткое введение в которую ( помимо страниц документации ) можно найти в моей предыдущей статье на habrahabr.ru.
Разработка Docker контейнеров
Вначале немного проблематики. Имеем задачу описать сборку Docker имиджа с помощью Dockerfile. Если сценарий сборки нетривиален и содержит множество инструкций, нужно как-то выкручиваться. Помимо того, что Dockerfile не может содержать более 120 слоев ( насколько я правильно понял из документации по Docker ), иметь дело с развесистым Dockerfile не очень приятно. Что можно с этим поделать? Очевидные варианты — вынести код сборки в отдельные Bash скрипты в рабочую директорию и делать установку и настройку системы прямо из них. Другой способ — «прикручивать» сбоку какой-нибудь configuration management tool типа chef или ansible. Оставляю на откуп читателю оценку данных альтернатив ( IMHO у них есть свои плюсы и минусы ) и предлагаю третий способ — использование Sparrow.
Прежде чем приводить детали реализации хочется сказать:
-
Вариант со Sparrow чем-то то очень похож на использование Bash скриптов, с той лишь разницей, что вся логика установки выносится в Sparrow плагин, со своим исходным кодом, хранящимся в отдельном месте ( git репозитарий или центральное хранилище ).
-
Таким образом, базовая настройка системы в контексте Docker описана в Dockerfile, а более тонкая и сложная внутри Sparrow плагина.
- Разработка плагина может быть отделена от контекста Dockerfile — что удобно, например вы можете на существующем Docker контейнере отлаживать процесс установки, на прибегая каждый раз к постройке имиджа командой
docker build, и, как только плагин будет отлажен и готов к работе, можно еще раз прогнать полный цикл сборки системы посредством все той же командойdocker build( сбросив при этом docker кэш разумеется ).
Пример реализации
Итак, покажем все на конкретной системе. Требуется собрать имидж с дистрибутивом CentOS и установить приложение, написанное на Ruby версии равной 2.3. После этого запустить основной скрипт приложения из под выделенного пользователя. Исходный код приложения скачивается с некого архивного сервера. Пример взят из реальной жизни, хотя некоторые детали намеренно опущены, дабы не перегружать статью материалом.
Базовая конфигурация системы
Прежде чем писать код плагина, создадим Dockerfile. За базовый имидж я взял tutum/centos по причине его легковесности. По этой же причине приходится доставлять часть пакетов, но в целом это не является какой-то проблемой.
$ cat Dockerfile
FROM tutum/centos
MAINTAINER "melezhik" <melezhik@gmail.com>
RUN yum clean all
RUN yum -y install nano git-core
RUN yum -y install make
RUN yum -y install gcc
RUN yum -y install perl perl-devel
perl-Test-Simple perl-Digest-SHA perl-Digest-MD5 perl-CPAN-Meta
perl-CPAN-Meta-Requirements perl-Getopt-Long
perl-JSON perl-Module-CoreList perl-Module-Metadata perl-parent perl-Path-Tiny perl-Try-Tiny
perl-App-cpanminus perl-JSON-PP perl-Algorithm-Diff perl-Text-Diff
perl-Spiffy perl-Test-Base perl-YAML perl-File-ShareDir-Install perl-Class-Inspector
perl-File-ShareDir perl-File-ShareDir-Install perl-Config-General
RUN cd /bin/ && curl -L https://cpanmin.us/ -o cpanm && chmod +x cpanm
RUN cpanm Sparrow -qНемного комментариев по Dockerfile .
-
nanoиgit-coreнеобходимы для разработки Sparrow плагина ( смотрите далее ) — мы будем редактировать код сценариев и коммитить изменения в удаленный git репозитарий. -
gcc,makeпотребуются для сборки RubyGems и CPAN пакетов. Первые потребуются при установки Ruby через rvm, последние для установки Sparrow. -
Установка многочисленных
perl-*пакетов черезyumнеобходима для оптимизации процесса сборки по скорости, можно было бы не делать этого, т.к. следующая инструкцияcpanm -q Sparrowустановила бы требуемые зависимости сама, но установка зависимостей через cpanm в общем случае требует гораздо больше времени, чем установка «нативных» для CentOS rpm-ок. - Инструкция
cpanm Sparrow -qставит среду разработки многоцелевых сценариев, не забываем, что мы собираемся разрабатывать Sparrow прямо на запущенном Docker контейнере.
Итак, попробуем создать имидж:
$ docker build -t ruby_app .
...
...
Successfully built 25e7cd784c99Начинаем разрабатывать плагин
Отлично, имидж с базовой инфраструктурой у нас есть, можно запустить Docker контейнер и начать разработку плагина прямо на нем.
$ docker run -t -i ruby_app /bin/bash
$ mkdir ruby-app
$ cd ruby-app
$ git init .
$ git remote add origin https://github.com/melezhik/ruby-app.git
$ touch README.md
$ git add README.md
$ git config --global user.email "melezhik@gmail.com"
$ git config --global user.name "Alexey Melezhik"
$ git commit -a -m 'first commit'
$ git push -u origin masterВышеуказанными командами мы создали шаблон проекта для нашего плагина и закоммитили все в удаленный git репозитарий. URL репозитария мы запомним, он понадобится нам далее, когда мы будем проводить полноценную сборку имиджа командой docker build
Теперь сделаем небольшой отступление. Вспомним нашу задачу. Попробуем для удобства разбить ее на независимые части:
- Создание аккаунта пользователя приложения
- Установка Ruby посредством rvm
- Скачивание архива приложения, распаковка и установка зависимостей
Для логически отдельных задач в Sparrow предусмотрен механизм модулей, воспользуемся им. Но прежде всего создадим основную историю, в которой будем делегировать выполнение задач разным модулям. Итак, все на том же запущенном Docker контейнере:
$ nano hook.bash
action=$(config action)
for s in $action
do
run_story $s
done
set_stdout install-ok
$ nano story.check
install-okНемного комментариев по коду. Мы имеем три второстепенных истории ( модули ) и одну основную, заданную хук файлом (hook.bash), для того, что показать как все это работает создадим заглушки для сценариев в модулях. Да, и дефолтное значение для входного параметра action должно быть задано в suite.ini файле.
$ nano suite.ini
action create-user install-ruby install-appСоздаем заглушки сценариев:
$ mkdir -p modules/create-user
$ mkdir -p modules/install-ruby
$ mkdir -p modules/install-app
$ nano modules/create-user/story.bash
echo create-user-ok
$ nano modules/install-ruby/story.bash
echo install-ruby-ok
$ nano modules/install-app/story.bash
echo install-app-okА также проверочные файлы:
$ nano modules/create-user/story.check
create-user-ok
$ nano modules/install-ruby/story.check
install-ruby-ok
$ nano modules/install-app/story.check
install-app-okТеперь запустим все через strun — консольный скрипт для выполнения Sparrow сценариев:
$ strun
/tmp/.outthentic/93/ruby-app/story.t ..
# [/ruby-app/modules/create-user]
# create-user-ok
ok 1 - output match 'create-user-ok'
# [/ruby-app/modules/install-ruby]
# install-ruby-ok
ok 2 - output match 'install-ruby-ok'
# [/ruby-app/modules/install-app]
# install-app-ok
ok 3 - output match 'install-app-ok'
# [/ruby-app]
# install-ok
ok 4 - output match 'install-ok'
1..4
ok
All tests successful.
Files=1, Tests=4, 0 wallclock secs ( 0.00 usr 0.02 sys + 0.09 cusr 0.01 csys = 0.12 CPU)
Result: PASSОтлично. Мы видим, что все сценарии отработали успешно, это и будет скелетом нашего будущего плагина. Осталось только заимплиментить заглушки наших модулей.
Сценарий создания пользователя
Будем исходить из того что имя пользователя является настраиваемым, дефолтное значение определяем в файле suite.ini :
$ cat suite.ini
action create-user install-ruby install-app
user_name app-userТеперь реализация сценария:
$ nano modules/create-user/story.bash
user_id=$(config user_name)
echo create user id: $user_id
useradd -r -m -d /home/$user_id $user_id || exit 1
ls -d /home/$user_id || exit 1
id $user_id || exit 1
echo create-user-okИ запуск ( обратите внимание, что здесь мы воспользовались возможностью запуска отдельного сценария с помощью параметра action ):
$ strun --param action=create-user
/tmp/.outthentic/135/ruby-app/story.t ..
# [/ruby-app/modules/create-user]
# create user id: app-user
# /home/app-user
# uid=997(app-user) gid=995(app-user) groups=995(app-user)
# create-user-ok
ok 1 - output match 'create-user-ok'
# [/ruby-app]
# install-ok
ok 2 - output match 'install-ok'
1..2
ok
All tests successful.
Files=1, Tests=2, 0 wallclock secs ( 0.03 usr 0.00 sys + 0.11 cusr 0.04 csys = 0.18 CPU)
Result: PASSМы видим, что сценарий отработал и пользователь создался. Обратите внимание, что большинство Bash команд внутри сценария завершаются идиоматической конструкцией cmd || exit 1, strun проверяет код выполнения сценария и если он неуспешен, то соответствующий тест проваливается, например так — попробуем создать пользователя с невалидным для системы именем:
$ strun --param action=create-user --param user_name='/'
/tmp/.outthentic/160/ruby-app/story.t ..
# [/ruby-app/modules/create-user]
# create user id: /
# useradd: invalid user name '/'
not ok 1 - scenario succeeded
not ok 2 - output match 'create-user-ok'
# [/ruby-app]
# install-ok
ok 3 - output match 'install-ok'
1..3
# Failed test 'scenario succeeded'
# at /usr/local/share/perl5/Outthentic.pm line 167.
# Failed test 'output match 'create-user-ok''
# at /usr/local/share/perl5/Outthentic.pm line 213.
# Looks like you failed 2 tests of 3.
Dubious, test returned 2 (wstat 512, 0x200)
Failed 2/3 subtests
Test Summary Report
-------------------
/tmp/.outthentic/160/ruby-app/story.t (Wstat: 512 Tests: 3 Failed: 2)
Failed tests: 1-2
Non-zero exit status: 2
Files=1, Tests=3, 0 wallclock secs ( 0.02 usr 0.00 sys + 0.10 cusr 0.00 csys = 0.12 CPU)
Result: FAILСделаю здесь еще небольшое отступление. Зададимся вопросом зачем нам нужно проверочные файлы, если по-сути проверки кода завершения сценария должно быть достаточно. Резонный вопрос. Мы можем думать о проверочных правилах фреймворка Sparrow как о некой альтернативном способе контроля или верификации выполнения наших скриптов. В идеологии Sparrow любой выполняемый сценарий является историей в том смысле, что это некий скрипт, который запускается и чаще всего «сообщает» что-то о своей работе — образно говоря «оставляя след в истории». Это след — стандартный выходной поток stdout, содержимое которого можно провалидировать. Почему это может быть полезно:
-
Не всегда успешный код завершения означает, что все идет хорошо
- Иногда хочется не выходить из скрипта аварийно ( посредством
cmd || exit 1), позволив скрипту сделать свою работу до конца и отложить верификацию посредством проверки через проверочный файл.
В качестве конкретного примера можно привести сценарий установки Ruby через rvm, который идет следующим по списку в нашем плане.
Сценарий установки Ruby из rvm
Вот как будет выглядеть сценарий установки:
$ nano modules/install-ruby/story.bash
yum -y install which
curl -sSL https://rvm.io/mpapis.asc | gpg2 --import - || exit 1
curl -sSL https://get.rvm.io | bash -s stable --ruby || exit 1
source /usr/local/rvm/scripts/rvm
gem install bundler --no-ri --no-rdoc
echo ruby version: $(ruby --version)
bundler --version
echo install-ruby-okА это — проверочный файл:
$ nano modules/install-ruby/story.check
regexp: ruby version: ruby 2.3
install-ruby-okТеперь запустим данный сценарий:
$ strun --param action=install-ruby
# большая часть вывода
# здесь опущена
# ...
# ...
# ...
# ruby version: ruby 2.3.0p0 (2015-12-25 revision 53290) [x86_64-linux]
# Bundler version 1.12.5
# install-ruby-ok
ok 1 - output match /ruby version: ruby 2.3/
ok 2 - output match 'install-ruby-ok'
# [/ruby-app]
# install-ok
ok 3 - output match 'install-ok'
1..3
ok
All tests successful.
Files=1, Tests=3, 91 wallclock secs ( 0.03 usr 0.00 sys + 3.24 cusr 1.03 csys = 4.30 CPU)
Result: PASSХочется обратить внимание, что для верификации версии установленного Ruby мы воспользовались проверочным правилом ввиде регулярного выражения:
regexp: ruby version: ruby 2.3Конечно rvm позволяет устанавливать требуемую версию явно, просто хотелось здесь привести пример когда проверки, определенные в проверочных файлах позволяют добавить дополнительную верификацию работы сценария с минимальными усилиями.
Теперь можно перейти к сценарию установки приложения.
Сценарий установки приложения
Напомню. Нам будет необходимо:
- скачать тарбол по заданному урлу
- распаковать архив
- перейти в распакованную папку и выполнить команду
bundle install --target ./localдля установки зависимостей
На этом все. Конечно в реальном приложении, нам бы пришлось бы еще запустить какой-нибудь сервис или совершить еще какие-нибудь дополнительные операции, но для демонстрации работы плагина этого должно быть достаточно.
Опять таки же для простоты примера пусть у нас есть Ruby приложение состоящее из:
Gemfile— в котором будут прописаны зависимостиhello.rb— запускаемого скрипа, который просто выводит в консоль строчкуHello World
Пакуем все архив и выкладываем все на архивный сервер га локальный nginx, теперь дистрибутив будет доступен по URL:
127.0.0.1/app.tar.gzОбновим код сценария.
$ cat suite.ini
action create-user install-ruby install-app
user_name app-user
source_url 127.0.0.1/app.tar.gz
$ cat modules/install-app/story.bash
user_id=$(config user_name)
source_url=$(config source_url)
yum -y -q install sudo
echo downloading $source_url ...
sudo -u $user_id -E bash --login -c "curl -f -o ~/app.tar.gz $source_url -s" || exit 1
echo unpacking tarball ...
sudo -u $user_id -E bash --login -c "cd ~/ && tar -xzf app.tar.gz" || exit 1
echo installing dependencies via bundler
sudo -u $user_id -E bash --login -c "cd ~/app && bundle install --quiet --path vendor/bundle " || exit 1
sudo -u $user_id -E bash --login -c "cd ~/app && bundle exec ruby hello.rb " || exit 1
echo install-app-ok
$ nano modules/install-app/story.check
install-app-ok
Hello WorldНебольшие комментарии по сценарию:
-
Установку делаем из-под пользователя заданного в конфигурации плагина suite.ini. Для этого нам нужен пакет
sudo -
Последняя команда запускает скрипт приложения
hello.rb - В проверочном файле требуем что бы в
stdoutбыл виден «след» от сценария — строчка ‘Hello World’
Итак, запустим сценарий:
$ strun --param action=install-app
/tmp/.outthentic/16462/ruby-app/story.t ..
# [/ruby-app/modules/install-app]
# Package sudo-1.8.6p7-17.el7_2.x86_64 already installed and latest version
# downloading 127.0.0.1/app.tar.gz ...
# unpacking app ...
# installing dependencies via bundler
# Hello World
# install-app-ok
ok 1 - output match 'install-app-ok'
ok 2 - output match 'Hello World'
# [/ruby-app]
# install-ok
ok 3 - output match 'install-ok'
1..3
ok
All tests successful.
Files=1, Tests=3, 2 wallclock secs ( 0.01 usr 0.00 sys + 1.61 cusr 0.50 csys = 2.12 CPU)
Result: PASSКак мы видим приложение действительно установилось и скрипт hello.rb запускается. Добавим еще один «параноидальный» ассерт в проверочный файл для демонстрации возможностей системы проверок Sparrow:
$ nano modules/install-app/story.check
install-app-ok
Hello World
generator: <<CODE
!bash
if test -d /home/$(config user_name)/app; then
echo assert: 1 directory /home/$(config user_name)/app exists
else
echo assert: 0 directory /home/$(config user_name)/app exists
fi
CODEИ запустим сценарий заново.
$ strun --param action=install-appВ выводе получим:
$ ok 3 - directory /home/app-user/app existsПубликация Sparrow плагина
На этом создание плагина завершено. Закоммитим изменения и сделаем «push» в git репозитарий:
$ git add .
$ git commit -a -m 'all done'
$ git push
$ exitМы вышли из докер контейнера он нам больше не нужен, можно его удалить:
$ docker rm 5e1037fa4aefПолный цикл сборки имиджа для Docker контейнера
Осталось чуть-чуть изменить Dockerfile, вспоминаем о том, что нам понадобится ссылка на удаленный git репозитарий, где мы разместили код нашего Sparrow плагина, окончательный вариант будет таким:
FROM tutum/centos
MAINTAINER "melezhik" <melezhik@gmail.com>
RUN yum clean all
RUN yum -y install nano git-core
RUN yum -y install make
RUN yum -y install gcc
RUN yum -y install perl perl-devel
perl-Test-Simple perl-Digest-SHA perl-Digest-MD5 perl-CPAN-Meta
perl-CPAN-Meta-Requirements perl-Getopt-Long
perl-JSON perl-Module-CoreList perl-Module-Metadata perl-parent perl-Path-Tiny perl-Try-Tiny
perl-App-cpanminus perl-JSON-PP perl-Algorithm-Diff perl-Text-Diff
perl-Spiffy perl-Test-Base perl-YAML perl-File-ShareDir-Install perl-Class-Inspector
perl-File-ShareDir perl-File-ShareDir-Install perl-Config-General
RUN cd /bin/ && curl -L https://cpanmin.us/ -o cpanm && chmod +x cpanm
RUN cpanm Sparrow -q
RUN echo ruby-app https://github.com/melezhik/ruby-app.git > /root/sparrow.list
RUN sparrow plg install ruby-app
RUN sparrow plg run ruby-appТеперь мы можем осуществить полный цикл сборки имиджа, «проиграв» все заново:
$ docker build -t ruby_app --no-cache=true .В итоге мы получим Docker имидж с требуемой системой.
Заключение
Применение системы многоцелевых сценариев Sparrow может быть эффективным средством построения Docker имиджей, т.к. позволяет строить сложные конфигурации, оставляя основной Dockerfile простым и лаконичным, а так же упрощая процесс разработки самих сценариев конфигурирования требуемой системы.
Спасибо за внимание.
Как обычно жду вопросов и конструктивной критики! 
Алексей
На чтение 6 мин Просмотров 2.3к. Опубликовано 16.11.2021
Инструменты автоматизации сборки или инструменты сборки — это приложения, используемые для автоматизации сборки. Автоматизация сборки — важный аспект разработки программного обеспечения. Это относится к процессу автоматизации задач, необходимых для преобразования исходного кода в исполняемые программы. Ваш выбор инструмента сборки будет зависеть от используемых вами языков и фреймворков.
Сегодня мы сосредоточимся на инструментах сборки Java. Java — один из наиболее часто используемых языков при разработке программного обеспечения. Доступно множество инструментов для сборки Java. Мы сравним два самых популярных инструмента сборки для разработки на Java: Maven и Gradle.
Содержание
- Что такое автоматизация сборки?
- Что делают инструменты сборки?
- Что такое Maven?
- Что такое Gradle?
- Maven или Gradle: сходства
- Maven или Gradle: различия
- Maven или Gradle: какой инструмент сборки Java вам подходит?
Что такое автоматизация сборки?
Автоматизация сборки — это процесс автоматизации задач, необходимых для создания, выполнения и тестирования программ. После того, как вы создадите исходный код для программы, автоматизация сборки вступит в процесс и подготовит исходный код для развертывания в производственной среде.
Автоматизация сборки — это лучшая практика и необходимое условие для любого процесса непрерывной интеграции в DevOps. У большинства современных команд разработчиков есть устоявшийся процесс автоматизации сборки. Эта автоматизация задач помогает сэкономить драгоценное время и ресурсы для разработчиков и групп разработчиков, которые когда-то выполняли эти задачи вручную.
Исторически задачи автоматизации сборки решались с помощью make-файлов. Сегодня они выполняются с помощью средств автоматизации сборки или серверов автоматизации сборки. Термин «автоматизация сборки» может использоваться как синоним «системы сборки».
Что делают инструменты сборки?
Инструменты сборки позволяют решать самые разные задачи автоматизации сборки, в том числе:
- Компиляция: компиляция исходного кода в машинный код
- Управление зависимостями: выявление и исправление необходимых сторонних интеграций
- Автоматические тесты: выполнение тестов и сообщение об ошибке
- Пакетирование приложения для развертывания: подготавливает исходный код для развертывания на серверах.
Что такое Maven?
Maven, или Apache Maven, был выпущен в 2004 году как усовершенствование Apache Ant. Это инструмент сборки и менеджер проектов на основе XML. Maven — это проект Apache с открытым исходным кодом. Его репозиторий по умолчанию — это центральный репозиторий Maven. Центральный репозиторий состоит из компонентов с открытым исходным кодом от участников, от отдельных разработчиков до крупных организаций. Существует огромное количество плагинов Maven для настройки и расширения функциональности инструмента сборки.
Проекты Maven в первую очередь определяются файлами объектной модели проекта (POM), написанными в XML. Эти файлы POM.xml содержат зависимости проекта, плагины, свойства и данные конфигурации. Maven использует декларативный подход и имеет предопределенный жизненный цикл.
Что такое Gradle?
Gradle был впервые выпущен в 2008 году. Основываясь на концепциях Maven, он был представлен как преемник Maven. Вместо того, чтобы использовать конфигурацию проекта Maven на основе XML, он представил предметно-ориентированный язык (DSL) на основе языков программирования Groovy и Kotlin. Gradle поддерживает репозитории Maven и Ivy для объявления конфигураций проекта. Он был разработан с учетом многопроектных сборок.
Maven или Gradle: сходства
И Maven, и Gradle — бесплатное программное обеспечение с открытым исходным кодом, распространяемое по лицензии Apache License 2.0. Оба они легко настраиваются и поддерживаются различными Java IDE, включая Eclipse.
Больше общего между Maven и Gradle:
- Формат GAV, используемый для идентификации артефактов
- Плагины добавляют функциональность, включая добавление задач и конфигураций зависимостей в проекты.
- Та же структура каталогов (Gradle принял Maven)
- Оба разрешают зависимости из настраиваемых репозиториев.
Maven или Gradle: различия
Некоторые из ключевых различий между Maven и Gradle:
- Язык сценария сборки: сценарий сборки Gradle по своей сути более универсален и эффективен, чем Maven. Это связано с тем, что Gradle основан на языке программирования (Groovy), а Maven — на языке разметки (XML). Предостережение здесь в том, что скрипт сборки Gradle уязвим для ошибок, поскольку он основан на языке программирования.
- Производительность: Gradle реализует такие стратегии, как кэш сборки и инкрементные компиляции, чтобы обеспечить высокую производительность. Gradle утверждает, что он работает до семи раз быстрее, чем Maven для инкрементных изменений, и в три раза быстрее, когда выходные данные задачи кэшируются. Однако отнеситесь к этому с недоверием. Есть разработчики, которые считают Maven более быстрым из двух.
- Гибкость и простота настройки: скрипт сборки Gradle на основе Groovy предлагает большую гибкость, чем Maven XML. Например, вы можете написать настройки плагина прямо в скрипт сборки Gradle. Gradle также более эффективен, если вы хотите настроить артефакты сборки и структуру проекта. Хотя Maven также обладает широкими возможностями настройки, его конфигурация на основе XML требует нескольких дополнительных шагов для настройки вашей сборки.
- Плагины: Maven существует дольше, чем Gradle. По этой причине доступно больше плагинов Maven, и больше крупных поставщиков поддерживают плагины Maven, чем плагины Gradle.
- Управление зависимостями: два инструмента сборки используют разные подходы для разрешения конфликтов зависимостей. Maven следует порядку объявления, а Gradle ссылается на дерево зависимостей.
Maven или Gradle: какой инструмент сборки Java вам подходит?
Выбор инструмента сборки Java во многом зависит от ваших индивидуальных предпочтений и требований проекта.
Вот несколько вещей, которые следует учитывать, если вы выбираете между Gradle и Maven:
- Типичный размер проекта: если вы работаете над большими проектами, Gradle может работать лучше и быстрее, чем Maven. Если вы в основном занимаетесь небольшими проектами, разница в производительности Maven может быть незначительной или несущественной для вашего решения.
- Необходимость настройки: сценарий сборки Gradle на основе Groovy легко допускает настройку, если вашему проекту требуется много наворотов. Maven может в достаточной мере удовлетворить ваши потребности, если вы не возражаете против дополнительных шагов, связанных с добавлением функций в его сценарий на основе XML.
- Кривая обучения: известно, что у Gradle крутая кривая обучения даже для опытных инженеров-строителей. Эта кривая обучения — достойное вложение времени и энергии, если вы знаете, что Gradle подойдет вам в долгосрочной перспективе. Однако изучение Gradle может оказаться ненужным трудным делом, если Maven сможет адекватно удовлетворить ваши потребности.
- Поддержка сообщества: сообщество Maven было создано еще до того, как Gradle вышел на сцену. Maven может лучше удовлетворить ваши потребности, если для вас важны поддержка сообщества и документация.
На самом деле, я не понимаю Грейлу в Андроидстудио, многое было видно, но я не знаю, сухой, поэтому я выучил основу, а потом посмотрю на Android Richle очень просто. Затем они могут узнать фундамент.
Учиться с вопросами.
- Что такое файл настроек?
- Что такое файл сборки?
- Что такое проект?
- Что такое задача?
Мы часто видим настройки. Градл в корневом каталоге в Гресе.

image
Во-первых, настройка. Градл
Роль настроек. Градл состоит в том, чтобы установить подпроект, потому что в многоэнергетике Группе выражены инженерным деревом, на самом деле, концепция проекта и модуля в AndroidStudio аналогична, корневой проект проекта, Подпроект — это модуль.
Подпроект сконфигурирован только в файле Settins, который будет распознан Групкой, то есть он будет включен в строительство.
rootProject.name = 'mopub-android'
include ':mopub-sdk', ':mopub-sample', ':mopub-sdk:mopub-sdk-base', ':mopub-sdk:mopub-sdk-banner',
':mopub-sdk:mopub-sdk-interstitial', ':mopub-sdk:mopub-sdk-rewardedvideo',
':mopub-sdk:mopub-sdk-native-static', ':mopub-sdk:mopub-sdk-native-video'
Вот чтобы указать каталог по умолчанию для дочернего проекта, мы также можем указать каталог вручную.
include ':mopub-sdk'
project (':mopub-sdk').projectDir = new File(rootDir,'mopub/mopub-sdk')
Во-вторых, build.gradle.
У каждого проекта будет Build.gradle, который является входным, построенным этим проектом, настраивая проект, такой как в какой библиотеке, в зависимости от которого плагин.
Хотя каждый проект имеет Build.gradle, но корневой проект — это босс, вы можете получить весь дочерний проект, чтобы вы могли настроить дочерний проект в Build.gradle of root Project. Например, весь склад детского проекта JCenter, чтобы мы полагаемся на банку, можем скачать непосредственно от jcenter.
buildscript {
repositories {
jcenter()
google()
}
...
}
Child Project
apply plugin: 'java-library'
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation 'com.google.auto.service:auto-service:1.0-rc4'
implementation 'com.squareup:javapoet:1.11.1'
implementation project(path: ':router_annotation')
}
3, Проекты и задачи
Multi Project на самом деле предназначен для лучшего разделения, низкой связи, высокой полимеризации, один проект может состоять из множества проекта, а проект может быть состоит из нескольких задач.
Например, компиляция Java-кода, загрузка в jcenter, упаковка AAR и т. Д. Это задача.

image
4、Task。
// Файл называется custom.gradle
ask customTask{
doFirst{
println ':customTask:doFrist'
}
doLast{
println ':customTask:doLast'
}
}

image
5, задача зависимости
task Buying {
doLast{
PrintLN 'Покупка: Купить Место проведения'
}
}
task Washing(dependsOn: Buying){
doLast{
PrintLN 'Стирка: стиральная тарелка
}
}
task Cook(dependsOn: Washing){
doLast{
PrintLN 'Cook: приготовление пищи
}
}

image
6, задача контролируется API, взаимодействуя
Название немного , на самом деле, это, например, мы написали задачу. На самом деле эта задача будет использовать другие переменные, которые мы определяем, вы можете использовать задачу и его метод.
task exHello {
println '<<'
}
exHello.doFirst{
println project.hasProperty('exHello')
println 'doFirst'
}
exHello.doLast{
println 'doLast'
}

image
7, пользовательские свойства
Это более полезно, в основном используйте его. Если вам нужно добавить дополнительные пользовательские свойства, вы можете использовать оба способа, один — это ext.age, чтобы добавить, что one ext {} добавлено несколько.
ext.age = 12
ext{
phone = 123456
address = 'beijing'
}
task exCustomProperty{
println phone
println address
println age
}
Я считаю, что все используются в том, что это таможенное имущество все еще очень широкое. Перекрестный проект, пересечение задачи и т. Д.
Также есть место очень часто, то есть, источники и используют проектные элементы, будут иметь дело с ним.
apply plugin:"java"
task exCustomProperty{
sourceSets.each{
println " ${it.name}--${it.java.srcDirs}"
}
}
sourceSets.all{
ext.srcDirs = null
}
sourceSets {
main {
srcDirs = ['main/src']
}
test{
srcDirs = ['test/src']
}
}

image
Поэтому, когда мы развиваемся, нам нужно управлять некоторой информацией о конфигурации, чтобы избежать конфигурации каждого модуля и избегать ошибок, поэтому вам нужно управлять некоторой информацией о конфигурации, поэтому вы можете Ext {}, красивые, ленивые инструменты.
8, скрипт является кодом, код — это скрипт
Это везде, где Rockle находится в этом месте, в этом файле сценария вы можете использовать любой синтаксис и API Groovy, Java и Gradle в этом файле сценария, чтобы сделать то, что мы хотим сделать. В скриптах вы можете определить классы, внутренние классы, импортировать пакеты, методы определения, константы, интерфейсы, гибкое воображение, такие как мы генерируем имена пакетов APK на основе времени.
def buildTime(){
def data = new Date()
def formattedData = date.format('yyyyMMdd')
return formattedData
}
Фокус: эта статья записана в полную ссылку на Android Gradle авторитет в качестве обучения.
Определения сборки и ссылки на сборку — это ресурсы, которые вы можете создать для организации своих скриптовфрагмент кода, позволяющий создавать ваши собственные Компоненты, запускайте игровые события, изменяйте свойства Компонентов с течением времени и реагируйте на ввод данных пользователем любым удобным для вас способом. Подробнее
См. Словарь в сборки.
Сборка — это библиотека кода C#, содержащая скомпилированные классы и структуры, определенные вашими скриптами, а также определяющие ссылки на другие сборки. Общие сведения о сборках в C# см. в разделе Сборки в .NET.
По умолчанию Unity компилирует почти все ваши игровые сценарии в предопределенную сборку Assembly-CSharp.dll. (Unity также создает несколько небольших специализированных предопределенных сборок.)
Этот порядок приемлем для небольших проектов, но имеет некоторые недостатки, когда вы добавляете в проект больше кода:
- Каждый раз, когда вы меняете один скрипт, Unity приходится перекомпилировать все остальные скрипты, что увеличивает общее время компиляции для повторяющихся изменений кода.
- Любой скрипт может напрямую обращаться к типам, определенным в любом другом скрипте, что может затруднить рефакторинг и улучшение вашего кода.
- Все скрипты скомпилированы для всех платформ.
Определив сборки, вы можете упорядочить свой код, чтобы обеспечить модульность и возможность повторного использования. Скрипты в сборках, которые вы определяете для своего проекта, больше не добавляются к сборкам по умолчанию и могут обращаться только к сценариям в тех других сборках, которые вы указали.
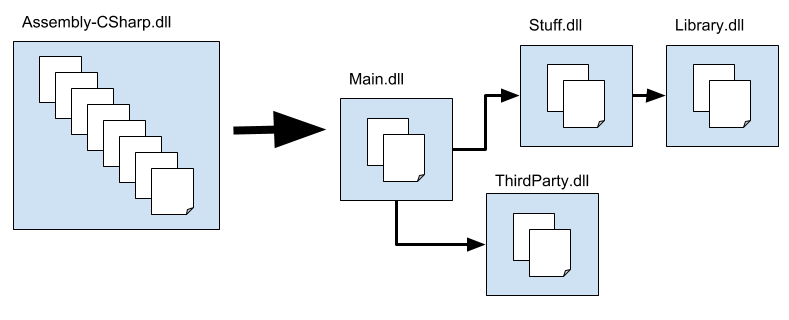
На приведенной выше диаграмме показано, как можно разделить код проекта на несколько сборок. Поскольку Main ссылается на Stuff, а не наоборот, вы знаете, что любые изменения кода в Main не могут повлиять на код в Материал. Точно так же, поскольку Library не зависит ни от каких других сборок, вам будет проще повторно использовать код из Library в другом проекте.
В этом разделе обсуждается, как создавать и настраивать ресурсы определения сборки и ссылки на сборку для определения сборок для вашего проекта:
- Определение сборок
- Ссылки и зависимости
- Создание ресурса определения сборки
- Создание исходного ресурса определения сборки
- Создание сборки для конкретной платформы
- Создание сборки для кода редактора
- Создание тестовой сборки
- Ссылка на другую сборку
- Ссылка на предварительно скомпилированную сборку подключаемого модуля
- Условное построение сборки
- Определение символов на основе пакетов проекта
- Поиск сборки, которой принадлежит скрипт
- Специальные папки
- Получение информации о сборке в скриптах сборки
См. также:
- Свойства определения сборки
- Свойства ссылки на определение сборки
- Формат файла определения сборки
Определение сборок
Чтобы организовать код проекта в сборки, создайте папку для каждой нужной сборки и переместите сценарии, которые должны принадлежать каждой сборке, в соответствующую папку. Затем создайте ресурсы определения сборки, чтобы указать свойства сборки.
Unity берет все сценарии из папки, содержащей ресурс определения сборки, и компилирует их в сборку, используя имя и другие параметры, определенные ресурсом. Unity также включает сценарии в любые дочерние папки в той же сборке, если дочерняя папка не имеет собственного определения сборки или ресурса ссылки на сборку.
Чтобы включить сценарии из не дочерней папки в существующую сборку, создайте ресурс «Ссылка на сборку» в не дочерней папке и задайте для него ссылку на ресурс «Определение сборки», определяющий целевую сборку. Например, вы можете объединить скрипты из всех папок редактора в вашем проекте в их собственную сборку, независимо от того, где эти папки расположены.
Unity компилирует сборки в порядке, определяемом их зависимостями
См. в Словарь; вы не можете указать порядок, в котором происходит компиляция.
Ссылки и зависимости
Когда один тип (например, класс или структура) использует другой тип, первый тип зависит от второго. Когда Unity компилирует сценарий, он также должен иметь доступ к любым типам или другому коду, от которого зависит сценарий. Точно так же, когда скомпилированный код запускается, он должен иметь доступ к скомпилированным версиям своих зависимостей. Если два типа находятся в разных сборках, сборка, содержащая зависимый тип, должна объявить ссылку на сборку, содержащую тип, от которого она зависит.
Вы можете управлять ссылками между сборками, используемыми в вашем проекте, с помощью параметров определения сборки. Настройки определения сборки включают:
- Автоматическая ссылка — ссылаются ли предопределенные сборки на сборку
- Ссылки на определение сборки — ссылки на другие сборки проекта, созданные с помощью определений сборки
- Переопределить ссылки + Ссылки на сборки – ссылки на предварительно скомпилированные сборки (плагины)
- Нет ссылок на Engine — ссылки на сборки UnityEngine
Примечание. Классы в сборках, созданные с помощью определения сборки, не могут использовать типы, определенные в предопределенных сборках.
Ссылки по умолчанию
По умолчанию предопределенные сборки ссылаются на все остальные сборки, в том числе созданные с помощью определений сборки (1) и предварительно скомпилированные сборки, добавленные в проект в качестве подключаемых модулей (2). Кроме того, сборки, которые вы создаете с помощью ресурса определения сборки, автоматически ссылаются на все предварительно скомпилированные сборки (3):
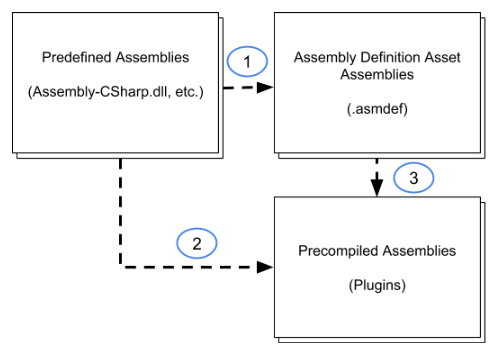
В настройках по умолчанию классы в предопределенных сборках могут использовать все типы, определенные любыми другими сборками в проекте. Точно так же сборки, которые вы создаете с помощью ресурса определения сборки, могут использовать все типы, определенные в любых предварительно скомпилированных сборках (подключаемых модулях).
Вы можете предотвратить ссылки на сборку из предопределенных сборок, отключив параметр Автоматическая ссылка в Инспекторе для ресурса определения сборки. Отключение автоматических ссылок означает, что предопределенные сборки не перекомпилируются при изменении кода в сборке, но также означает, что предопределенные сборки не могут напрямую использовать код в этой сборке. См. раздел Свойства определения сборки.
Точно так же вы можете запретить автоматическую ссылку на сборку подключаемого модуля, отключив свойство Автоссылка в Инспекторе подключаемых модулей. для актива плагина. Это влияет как на предопределенные сборки, так и на те, которые вы создаете с помощью определения сборки. Дополнительную информацию см. в разделе Инспектор подключаемых модулей.
При отключении Автоматически ссылаться для плагинаНабор кода, созданный вне Unity, который создает функциональность в Unity. В Unity можно использовать два типа подключаемых модулей: управляемые подключаемые модули (управляемые сборки .NET, созданные с помощью таких инструментов, как Visual Studio) и собственные подключаемые модули (библиотеки собственного кода для конкретной платформы). Подробнее
См. в Словарь, вы можете явно сослаться на него в Инспекторе для Ресурс определения сборки. Включите параметр ресурса Переопределить ссылки и добавьте ссылку на плагин. См. раздел Свойства определения сборки.
Примечание. Нельзя объявлять явные ссылки на предварительно скомпилированные сборки. Предопределенные сборки могут использовать код только в сборках с автоматическими ссылками.
Циклические ссылки
Ссылка на циклическую сборку существует, когда одна сборка ссылается на вторую сборку, которая, в свою очередь, ссылается на первую сборку. Такие циклические ссылки между сборками не допускаются и отображаются как ошибка с сообщением «Обнаружена сборка с циклическими ссылками».
Обычно такие циклические ссылки между сборками возникают из-за циклических ссылок внутри классов, определенных в сборках. Хотя в циклических ссылках между классами в одной сборке нет ничего технически недопустимого, циклические ссылки между классами в разных сборках не допускаются. Если вы столкнулись с ошибкой циклической ссылки, вы должны реорганизовать свой код, чтобы удалить циклическую ссылку или поместить взаимно ссылающиеся классы в одну сборку.
Создание ресурса определения сборки
Чтобы создать ресурс определения сборки:
- В Проектев Unity вы используете проект для проектирования и разработки игры. В проекте хранятся все файлы, связанные с игрой, такие как ресурсы и файлы сцен. Подробнее
В окне Словарь найдите папку, содержащую сценарии, которые вы хотите включить в сборка. - Создайте ресурс определения сборки в папке (меню: АктивыЛюбой носитель или данные, которые можно использовать в вашей игре или Ресурс может исходить из файла, созданного вне Unity, например, 3D-модели, аудиофайла или изображения. Вы также можете создавать некоторые типы ресурсов в Unity, такие как Animator Controller, Audio Mixer или Render Texture. . Подробнее
См. в Словарь > Создать > Определение сборки). - Назначьте название объекту. По умолчанию файл сборки использует имя, которое вы присвоили ресурсу, но вы можете изменить это имя в Инспектореокне Unity который отображает информацию о текущем выбранном игровом объекте, активе или настройках проекта, позволяя вам проверять и редактировать значения. Дополнительная информация
См. в окне Словарь.
Unity перекомпилирует скрипты в проекте для создания новой сборки. После завершения вы можете изменить настройки для нового определения сборки.
Скрипты в папке, содержащей определение сборки, включая сценарии в любых дочерних папках (если только эти папки не содержат собственных определений сборки или эталонных ресурсов), компилируются в новую сборку и удаляются из предыдущей сборки.
Создание исходного ресурса определения сборки
Чтобы создать исходный ресурс определения сборки:
-
В окне Проект найдите папку, содержащую сценарии, которые вы хотите включить в указанную сборку.
-
Создайте ресурс ссылки на сборку в папке (меню: Ресурсы > Создать > Ссылка на определение сборки).
-
Назначьте название объекту.
Unity перекомпилирует скрипты в проекте для создания новой сборки. По завершении вы можете изменить настройки для нового справочника по определению сборки.
-
Выберите новый ресурс Справочник определения сборки, чтобы просмотреть его свойства в Инспекторе.

-
Задайте для свойства определения сборки ссылку на целевой ресурс определения сборки.
-
Нажмите Применить.

Скрипты в папке, содержащей исходный ресурс определения сборки, включая сценарии в любых дочерних папках (если только эти папки не содержат собственные ресурсы определения сборки или эталона), компилируются в сборку, на которую ссылаются, и удаляются из предыдущей сборки.
Создание сборки для конкретной платформы
Чтобы создать сборку для определенной платформы:
-
Создайте ресурс определения сборки.
-
Выберите новый ресурс Справочник определения сборки, чтобы просмотреть его свойства в Инспекторе.
-
Отметьте параметр Любая платформа и выберите определенные платформы для исключения. Кроме того, вы можете снять флажок «Любая платформа» и выбрать определенные платформы для включения.
-
Нажмите Применить.

Сборка будет включена (или исключена) в соответствии с выбранными платформами при сборке проекта для платформы.
Создание сборки для кода редактора
Сборки редактора позволяют размещать сценарии редактора в любом месте проекта, а не только в папках верхнего уровня с именем Editor.
Чтобы создать сборку, содержащую код редактора в вашем проекте:
- Создайте сборку для конкретной платформы в папке, содержащей сценарии редактора.
- Включить ТОЛЬКО платформу редактора.
- Если у вас есть дополнительные папки, содержащие сценарии редактора, создайте ресурсы-ссылки на определение сборки в этих папках и установите для них ссылки на это определение сборки.
Создание тестовой сборки
Тестовые сборки позволяют писать тесты и запускать их с помощью Unity TestRunner, сохраняя при этом код тестирования отдельно от кода, поставляемого вместе с приложением. Unity предоставляет TestRunner как часть пакета Test Framework. См. тестовую среду. документации для получения инструкций по установке пакета Test Framework и созданию тестовых сборок.
Ссылка на другую сборку
Чтобы использовать типы и функции C#, являющиеся частью другой сборки, необходимо создать ссылку на эту сборку в ресурсе определения сборки.
Чтобы создать ссылку на сборку:
-
Выберите определение сборки для сборки, для которой требуется ссылка для просмотра ее свойств в Инспекторе.
-
В разделе Ссылки на определение сборки нажмите кнопку +, чтобы добавить новую ссылку.
-
Назначьте ресурс определения сборки вновь созданному слоту в списке ссылок.

Включение параметра Использовать идентификаторы GUID позволяет изменить имя файла связанного ресурса определения сборки без обновления ссылок в других определениях сборки для отражения нового имени. (Обратите внимание, что идентификаторы GUID необходимо сбросить, если файлы метаданных для файлов активов удалены или вы перемещаете файлы за пределы редактора Unity, не перемещая вместе с ними файлы метаданных.)
Ссылка на предварительно скомпилированную сборку плагина
По умолчанию все сборки в вашем проекте, созданные с помощью определений сборок, автоматически ссылаются на все предварительно скомпилированные сборки. Эти автоматические ссылки означают, что Unity должна перекомпилировать все ваши сборки при обновлении любой из предварительно скомпилированных сборок, даже если код в сборке не используется. Чтобы избежать этих дополнительных накладных расходов, вы можете переопределить автоматические ссылки и указать ссылки только на те предварительно скомпилированные библиотеки, которые действительно использует сборка:
-
Выберите определение сборки для сборки, для которой требуется ссылка для просмотра ее свойств в Инспекторе.
-
В разделе Общие включите параметр Переопределить ссылки.
Раздел Ссылки на сборку в Инспекторе становится доступным, когда установлен флажок Переопределить ссылки.
-
В разделе Ссылки на сборку нажмите кнопку +, чтобы добавить новую ссылку.
-
Используйте раскрывающийся список в пустом слоте, чтобы назначить ссылку на предварительно скомпилированную сборку. В списке показаны все предварительно скомпилированные сборки в проекте для платформы, установленной в данный момент в проекте Настройки сборки. (Установите совместимость платформы для предварительно скомпилированной сборки в Инспекторе подключаемых модулей.)
-
Нажмите Apply.
-
Повторите для каждой платформы, для которой вы создаете свой проект.


Условное включение сборки
Вы можете использовать символы препроцессора, чтобы контролировать, компилируется ли сборка и включается ли она в сборки вашей игры или приложения (включая режим воспроизведения в редакторе). Вы можете указать, какие символы должны быть определены для использования сборки, с помощью списка Определить ограничения в параметрах определения сборки:
-
Выберите определение сборки для просмотра ее свойств в Инспекторе.
-
В разделе Определить ограничения нажмите кнопку +, чтобы добавить новый символ в список ограничений.
-
Введите имя символа.
Вы можете «отменить» символ, поставив восклицательный знак перед названием. Например, ограничение
!UNITY_WEBGLбудет включать сборку, когда UNITY_WEBGL НЕ определен. -
Нажмите Применить.

Вы можете использовать следующие символы в качестве ограничений:
- Символы, определенные в параметре Сценарии определения символов, который можно найти в разделе Player вашего Настройки проектаБольшой набор настроек, которые позволяют настраивать физику, звук, сеть, графику, ввод и многие другие области ваш проект ведет себя. Подробнее
См. в Словарь. Обратите внимание, что Скрипты определения символов применяются к платформе, установленной в настоящее время в вашем проекте Настройки сборки. Чтобы определить символ для нескольких платформ, необходимо переключиться на каждую платформу и изменить поле Скрипты определения символов по отдельности. - Символы, определенные Unity. См. раздел Компиляция, зависящая от платформы.
- Символы, определенные с помощью раздела Определения версии ресурса определения сборки.
Символы, определенные в сценариях, не учитываются при определении того, было ли выполнено ограничение.
Дополнительную информацию см. в разделе Определение ограничений.
Определение символов на основе пакетов проектов
Если вам нужно скомпилировать другой код в сборке в зависимости от того, используются ли в проекте определенные пакеты или версии пакета, вы можете добавить записи в список Определения версий. В этом списке указаны правила определения символа. Для номеров версий можно указать логическое выражение, оценивающее конкретную версию или диапазон версий.
Чтобы условно определить символ:
-
Выберите определение сборки для просмотра ее свойств в Инспекторе.
-
В разделе Определения версии нажмите кнопку +, чтобы добавить запись в список.
-
Установите свойства:
- Ресурс: выберите пакет или модуль, который необходимо установить для определения этого символа
- Определить: имя символа
- Выражение: выражение, результатом которого является конкретная версия или диапазон версий. Правила см. в разделе Выражения определения версии.
Результат выражения показывает, какие версии оценивает выражение.
В следующем примере определяется символ USE_TIMELINE, если в проекте используется временная шкала 1.3.0 или более поздней версии:
-
Click Apply.

Символы, определенные в определении сборки, относятся только к скриптам в сборке, созданной для этого определения.
Обратите внимание, что вы можете использовать символы, определенные с помощью списка Определения версии, как Определить ограничения. Таким образом, вы можете указать, что сборка должна использоваться только в том случае, если в проекте установлены определенные версии данного пакета.
Выражения определения версии
Вы можете использовать выражения, чтобы указать точную версию или диапазон версий. В выражении Определение версии используется математическое обозначение диапазона. Квадратная скобка «[]» означает, что диапазон включает конечную точку:
[1.3,3.4.1]оценивается как1.3.0 <= x <= 3.4.1
Скоба «()» означает, что диапазон не включает конечную точку:
(1.3.0,3.4)оценивается как1.3.0 < x < 3.4.0
Вы можете смешивать оба типа диапазонов в одном выражении:
[1.1,3.4)оценивается как1.1.0 <= x < 3.4.0
(0.2.4,5.6.2-preview.2]оценивается как0.2.4 < x <= 5.6.2.- предварительный просмотр.2
Вы можете использовать одно обозначение версии в квадратных скобках, чтобы указать точную версию:
[2.4.5]оценивается какx = 2.4.5
Для упрощения вы можете ввести одну версию без скобок диапазона, чтобы указать, что выражение включает эту версию или более позднюю:
2.1.0-preview.7оценивается какx >= 2.1.0-preview.7
Обозначения версий состоят из четырех частей в соответствии с форматом Semantic Versioning: MAJOR.MINOR.PATCH-LABEL. Первые три части всегда являются числами, а метка — строкой. Пакеты Unity в предварительной версии используют строку preview или preview.n, где n > 0 . В выражении необходимо использовать по крайней мере основной и дополнительный компоненты версии.
Примечание. В выражении не допускаются пробелы.
Поиск сборки, которой принадлежит скрипт
Чтобы определить, в какую сборку скомпилирован один из ваших сценариев C#:
-
Выберите файл сценария C# в окне Проект Unity, чтобы просмотреть его свойства в окне Инспектора.
-
Имя файла сборки и определение сборки, если оно существует, отображаются в разделе Информация о сборке в Инспекторе.

В этом примере выбранный сценарий компилируется в файл библиотеки Unity.Timeline.Editor.dll, который определяется ресурсом определения сборки Unity.Timeline.Editor.
Специальные папки
Unity обрабатывает сценарии в папках с определенными специальными именами иначе, чем сценарии в других папках. Однако одна из этих папок теряет свою особую обработку, когда вы создаете ресурс определения сборки внутри нее или в папке над ней. Вы можете заметить это изменение при использовании папок редактора, которые могут быть разбросаны по всему проекту (в зависимости от того, как вы организуете свой код и от используемых вами пакетов Asset Store).
Unity обычно компилирует любые скрипты в папках с именем Editor в предопределенную сборку Assembly-CSharp-Editor независимо от того, где находятся эти скрипты. Однако если вы создаете ресурс определения сборки в папке, под которой находится папка редактора, Unity больше не помещает эти сценарии редактора в предопределенную сборку редактора. Вместо этого они попадают в новую сборку, созданную вашим определением сборки, где им может не быть места. Для управления папками редактора вы можете создать определение сборки или эталонные активы в каждой папке редактора, чтобы поместить эти сценарии в одну или несколько сборок редактора. См. раздел Создание сборки для кода редактора.
Настройка атрибутов сборки
Вы можете использовать атрибуты сборки, чтобы задать свойства метаданных для ваших сборок. По соглашению операторы атрибутов сборки обычно помещаются в файл с именем AssemblyInfo.cs.
Например, следующие атрибуты сборки указывают несколько .NET значения метаданных сборки, InternalsVisibleTo, который может быть полезен для тестирования, и определяемый Unity атрибут Preserve, который влияет на то, как неиспользуемый код удаляется из сборки при сборке. ваш проект:
[assembly: System.Reflection.AssemblyCompany("Bee Corp.")]
[assembly: System.Reflection.AssemblyTitle("Bee's Assembly")]
[assembly: System.Reflection.AssemblyCopyright("Copyright 2020.")]
[assembly: System.Runtime.CompilerServices.InternalsVisibleTo("UnitTestAssembly")]
[assembly: UnityEngine.Scripting.Preserve]
Получение информации о сборке в скриптах сборки
Используйте класс CompilationPipeline в пространстве имен UnityEditor.Compilation для получения информации обо всех сборках, созданных Unity для проекта, включая сборки, созданные на основе ресурсов определения сборки.
Например, в следующем сценарии класс CompilationPipeline используется для вывода списка всех текущих сборок Player в проекте:
using UnityEditor;
using UnityEditor.Compilation;
public static class AssemblyLister
{
[MenuItem("Tools/List Player Assemblies in Console")]
public static void PrintAssemblyNames()
{
UnityEngine.Debug.Log("== Player Assemblies ==");
Assembly[] playerAssemblies =
CompilationPipeline.GetAssemblies(AssembliesType.Player);
foreach (var assembly in playerAssemblies)
{
UnityEngine.Debug.Log(assembly.name);
}
}
}
Содержание
- 1 Понятие исполняемого файла
- 1.1 Формат в UNIX
- 1.2 Формат в Mac OS
- 1.3 Формат в Windows
- 2 Сборка простейшей программы
- 3 Стадии
- 3.1 Препроцессинг
- 3.2 Компиляция
- 3.3 Ассемблирование
- 3.4 Компоновка (linking)
- 3.5 Диаграмма
- 4 Сборка программ из нескольких C-файлов
- 5 Функции и переменные в C
- 5.1 Объявление и определение
- 5.2 Классификация
- 6 Что делает компилятор C
- 6.1 Анализ объектного файла
- 7 Сегменты и секции
- 7.1 .text
- 7.2 .data
- 7.3 .rodata
- 7.4 .bss
- 8 Представление программы в памяти
- 9 Что делает компоновщик
- 9.1 Повторяющиеся символы
- 9.2 Библиотеки
- 9.3 Статические библиотеки
- 9.4 Динамические библиотеки
- 10 Язык C++
- 10.1 Перегрузка функций и декорирование имён
- 10.2 Инициализация статических объектов
- 10.3 Шаблоны
- 11 Практика: сборка статической библиотеки на Linux
- 12 Полезные ссылки
Понятие исполняемого файла
В общем случае исполняемый файл (англ. executable file) — файл, содержащий программу в виде инструкций, которые могут быть исполнены компьютером. Исполняемым файлам противопоставляются файлы с данными (data file) — файлы, которые читаются и парсятся определённой программой, а сами по себе не могут быть исполнены.
Инструкции (код) — это:
- либо машинные инструкции для выполнения на физическом процессоре;
- либо исходный код (сценарий, скрипт, псевдокод), записанный на одном из интерпретируемых языков программирования (пример: bash-скрипты, Python-программы, bat-файлы);
- либо байт-код виртуальной машины (пример: class-файлы JVM, pyc-файлы для Python).
В рамках нашего курса системного программирования нас будет интересовать только первый тип — исполняемые файлы, содержащие машинный код. Поэтому далее под исполняемым будем понимать именно такой вид.
Формат и отличительные особенности исполняемых файлов зависят от операционной системы. Однако концепция является общей.
Формат в UNIX
В UNIX-подобных системах (Linux, FreeBSD, …) исполняемые файлы отличаются по специальному атрибуту execute в файловой системе, расширение файла значение не имеет (обычно не имеют расширения).
В современных UNIX-подобных системах используется формат ELF (Executable and Linkable Format).
Пример ELF-заголовка:
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............| 00000010 02 00 3e 00 01 00 00 00 c5 48 40 00 00 00 00 00 |..>......H@.....|
Слово ELF в английском также имеет значение «эльф». В продолжение темы средневекового фэнтези, широко используемый формат представления отладочной информации был назван DWARF (англ. «гоблин», «гном»). Изначально проектировался вместе с ELF, название дано в том же стиле, и позже придумана расшифровка Debugging With Attributed Record Formats.
До ELF, в семидесятые годы использовался формат a.out (assembler output). Отсюда пошла традиция, что при компиляции в GCC по умолчанию выходной файл называется a.out, хотя имеет формат ELF.
Формат в Mac OS
В операционных системах от Apple (iOS и Mac OS X) свой формат — Mach-O (сокращение от Mach object).
Формат в Windows
В Windows исполняемые файлы имеют расширение exe.
Формат исполняемых файлов называется PE (Portable Executable). Первые два байта PE файла содержат сигнатуру 0x4D 0x5A — «MZ». PE представляет собой модифицированную версию COFF (Common Object File Format) формата файла для UNIX. PE/COFF — альтернативный термин при разработке Windows.
Сборка простейшей программы
Есть код на C:
#include <stdio.h> int main(void) { puts("Hello, world!"); return 0; }
Кажется, очень просто получить из него исполняемую программу за один вызов компилятора.
На UNIX:
$ gcc main.c $ ./a.out Hello, world!
На выходе a.out — исполняемый файл.
На Windows:
> cl main.c > main.exe Hello, world!
На выходе main.exe — исполняемый файл.
Однако в действительности процесс сложный получения исполняемого файла из C-исходника сложный. Правильнее говорить не о компиляции, а о сборке, а компиляция — один из этапов.
Стадии
Классический сценарий сборки кода на C включает четыре этапа.
Препроцессинг
О препроцессоре мы говорили в прошлый раз. Он подставляет include-файлы, генерирует код с помощью макросов, заменяет define-константы на их значения.
Посмотреть результат препроцессинга можно через
$ gcc -E main.c
Результат выводится на стандартный вывод.
Вывод может быть большим. Например, на этот 7-строчный файл gcc 5.4.0 генерирует 854 строки. Если инклудов много, там будут тысячи строк.
Компиляция
Обработка исходного кода (уже без директив препроцессора) и преобразование его в команды ассемблера для целевой платформы (например x86).
$ gcc -S main.c
Результат записывается в файл main.s.
Ассемблирование
Преобразование кода на языке ассемблера в бинарный формат — в объектный файл.
$ gcc -c main.c
Результат записывается в файл main.o.
Компоновка (linking)
Объектный код, сгенерированный ассемблером, компонуется с другими объектным кодом, в том числе с библиотеками, для получения исполняемого файла.
Диаграмма

Сборка программ из нескольких C-файлов
На практике сегодня прероцессор, компилятор и ассемблер обычно не разделяют, это одна программа, и представление об отдельных трёх стадиях полезно лишь теоретически. Для простоты будем называть компиляцией получение из C-файла объектного файла.
Каждый C-файл можно компилировать независимо в свой объектный файл, а затем компоновать.
Это даёт следующие преимущества.
- Разные C-файлы компилируются параллельно на разных ядрах процессора.
- Если изменяется один C-файл, достаточно перекомпилировать только его.

$ gcc -с main.c $ gcc -с foo.c $ gcc -с bar.c $ gcc main.o foo.o bar.o -o program $ ./program
Функции и переменные в C
Объявление и определение
Необходимо понимать разницу между объявлением и определением.
Определение (definition) связывает имя с реализацией:
- Определение переменной побуждает компилятор зарезервировать некоторую область памяти (возможно, задав ей некоторое определённое значение).
- Определение функции заставляет компилятор сгенерировать код для этой функции.
void Foo(void) { } int x;
Объявление (declaration) говорит компилятору, что определение функции или переменной (с конкретным именем) существует в другом месте программы (вероятно, в другом C-файле).
void Foo(void); extern int x;
Заметьте, что определение также является объявлением — фактически это объявление, в котором «другое место» программы совпадает с текущим.
Классификация
Интуитивно понятным является понятие области видимости переменной (scope):
- глобальные переменнные,
- локальные переменные.
Глобальные объявляются вне функции и могут быть доступны из разных функций. Локальные переменные видимы только внутри функции (более того, в рамках блока, ограниченного фигурными скобками).
Мы уже рассматривали три класса хранения (storage class):
- статический,
- автоматический,
- динамический.
Связь этих классов с областями видимости достаточно очевидна. Глобальные переменные — статическое хранение, переменные существуют на протяжении всего жизненного цикла программы. Локальные переменные — автоматический тип.
Динамическое хранение имеют неименованные области памяти, выделяемые через malloc и освобождаемые через free. Поэтому используют указатели — именованные переменные, содержащие адрес неименованной области памяти. Сам указатель может быть локальной или глобальной переменной.
Существует пара частных случаев, связанных с ключевым словом static, которые с первого раза не кажутся очевидными.
- Статические локальные переменные на самом деле имеют статический класс хранения, потому что существуют на протяжении всей жизни программы, даже если они видимы только в пределах одной функции.
- Статические глобальные переменные также являются глобальными с той лишь разницей, что они доступны только в пределах одного файла, где они определены.
Для глобальных и локальных переменных, мы можем различать инициализирована переменная или нет, т.е. будет ли пространство, отведённое для переменной в памяти, заполнено определённым значением.
Рассмотрим пример:
/* Определение неинициализированной глобальной переменной */ int x_global_uninit; /* Определение инициализированной глобальной переменной */ int x_global_init = 1; /* Определение неинициализированной глобальной переменной, к которой * можно обратиться по имени только в пределах этого C файла */ static int y_global_uninit; /* Определение инициализированной глобальной переменной, к которой * можно обратиться по имени только в пределах этого C файла */ static int y_global_init = 2; /* Объявление глобальной переменной, которая определена где-нибудь * в другом месте программы */ extern int z_global; /* Объявлени функции, которая определена где-нибудь другом месте * программы (Вы можете добавить впереди "extern", однако это * необязательно) */ int fn_a(int x, int y); /* Определение функции. Однако, будучи помеченной как static, её можно * вызвать по имени только в пределах этого C-файла. */ static int fn_b(int x) { return x+1; } /* Определение функции. */ /* Параметр функции считается локальной переменной. */ int fn_c(int x_local) { /* Определение неинициализированной локальной переменной */ int y_local_uninit; /* Определение инициализированной локальной переменной */ int y_local_init = 3; /* Код, который обращается к локальным и глобальным переменным, * а также функциям по имени */ x_global_uninit = fn_a(x_local, x_global_init); y_local_uninit = fn_a(x_local, y_local_init); y_local_uninit += fn_b(z_global); return (x_global_uninit + y_local_uninit); }
Что делает компилятор C
Работа компилятора C заключается в конвертировании текста программы на C, понятного человеку, в нечто, что понимает компьютер. На выходе компилятор выдаёт объектный файл.
Содержание объектного файла — в сущности, две вещи:
- код, соответствующий определению функции в C-файле,
- данные, соответствующие определению глобальных переменных в C-файле (для инициализированных глобальных переменных начальное значение переменной тоже должно быть сохранено в объектном файле).
Код и данные будут иметь ассоциированные с ними имена — имена функций или переменных, с которыми они связаны определением.
Объектный код — это последовательность машинных инструкций для процессора, которая соответствует C-коду: if’ы и while’ы и пр. Эти инструкции должны манипулировать информацией определённого рода, а информация должна где-нибудь находится — для этого нам и нужны переменные. Код может также ссылаться на другой код (в частности, на другие C-функции в программе).
Где бы код ни ссылался на переменную или функцию, компилятор допускает это, только если он видел раньше объявление этой переменной или функции. Объявление — это обещание, что определение существует где-то в другом месте программы.
Работа компоновщика проверить эти обещания. Однако, что компилятор делает со всеми этими обещаниями, когда он генерирует объектный файл?
По существу компилятор оставляет пустые места. Пустое место (ссылка) имеет имя, но значение, соответствующее этому имени, пока неизвестно.
Учитывая это, мы можем изобразить объектный файл, соответствующей программе, приведённой выше, следующим образом:

Анализ объектного файла
Полезно посмотреть, как это работает на практике.
$ gcc -c example1.c $ ls example1.c example1.o
Объектный файл, хоть и не может быть запущен напрямую, имеет формат, схожий с форматом исполняемого файла.
На UNIX объектные файлы имеют расширение o. Формат — ELF.
На Windows используется расширение obj. Формат — COFF.
На платформе UNIX основным инструментом для нас будет команда nm, которая выдаёт информацию о символах объектного файла. Для Windows команда dumpbin с опцией /symbols является приблизительным эквивалентом. Также есть портированные под Windows инструменты GNU binutils, которые включают nm.exe.
Давайте посмотрим, что выдаёт nm для объектного файла, полученного из нашего примера выше.
$ nm -S example1.o
U fn_a
0000000000000000 000000000000000f t fn_b
000000000000000f 0000000000000059 T fn_c
0000000000000000 0000000000000004 D x_global_init
0000000000000004 0000000000000004 C x_global_uninit
0000000000000004 0000000000000004 d y_global_init
0000000000000000 0000000000000004 b y_global_uninit
U z_global
Результат может выглядеть немного по разному на разных платформах.
$ nm -f sysv example1.o Symbols from example1.o: Name Value Class Type Size Line Section fn_a | | U | NOTYPE| | |*UND* fn_b |0000000000000000| t | FUNC|000000000000000f| |.text fn_c |000000000000000f| T | FUNC|0000000000000059| |.text x_global_init |0000000000000000| D | OBJECT|0000000000000004| |.data x_global_uninit |0000000000000004| C | OBJECT|0000000000000004| |*COM* y_global_init |0000000000000004| d | OBJECT|0000000000000004| |.data y_global_uninit |0000000000000000| b | OBJECT|0000000000000004| |.bss z_global | | U | NOTYPE| | |*UND*
Ключевыми сведениями являются класс каждого символа и его размер (если присутствует).
- Класс U (от undefined) обозначает неопределённые ссылки, те самые «пустые места», упомянутые выше. Для этого класса существует два объекта: fn_a и z_global.
- Классы t и T (от слова text) указывают на код, который определён; различие между t и T заключается в том, является ли функция статической (t) (локальной в файле) или нет (T), т.е. была ли функция объявлена как static.
- Классы d и D (от слова data) содержат инициализированные глобальные переменные. При этом статические переменные принадлежат классу d.
- Для неинициализированных глобальных переменных мы получаем b, если они статичные, и B или C иначе.
Сегменты и секции
В формате ELF есть понятие сегмента и секции.
Понятие сегмента из ELF-файла не имеет ничего общего с сегментацией памяти в архитектуре x86, с сегментными регистрами и дескрипторами процессора. Здесь сегмент — это просто диапазон адресов в памяти.
Секция включает информацию, используемую в процессе компоновки. В частности, имена символов, сами данные переменных и машинные инструкции.
Сегмент — группа секций. Сегмент описывается заголовком (program header). В одном сегменте 0 или более секций. Сегмент также содержит информацию, необходимую для исполнения файла (runtime). Куда необходимо загрузить данные в виртуальном адресном пространстве процесса, какие права установить на эти страницы памяти (чтение, запись, исполнение). Мы это более детально будем изучать применительно к архитектуре x86 на последующих занятиях.
$ readelf -l program
.text
Секция кода или секция текста содержит исполняемые инструкции для процессора. Как правило, доступна только для чтения.
.data
Секция данных содержит глобальные переменные и локальные статические переменные, для которых задано начальное значение.
.rodata
Константы (read-only).
.bss
Секция для неинициализированных данных глобальных и локальных статических переменных. Эти переменные автоматически инициализируются нулями. Секция по сути не занимает места в объектном файле и позволяет экономить место на диске (нули явно не хранятся, только размер).
Название BSS объясняется историческими причинами. Изначально это сокращение от названия операции «Block Started by Symbol» на древней ЭВМ IBM 704 (1957 г.). Некоторые расшифровывают эту аббревиатуру как «Better Save Space».
Представление программы в памяти

Что делает компоновщик
Компоновщик осуществляет заполнение пустых мест в объектных файлах. Проиллюстрируем это на примере, рассматривая ещё один C файл в дополнение к тому, что был приведён выше.
/* Инициализированная глобальная переменная */ int z_global = 11; /* Вторая глобальная переменная с именем y_global_init, но они обе static */ static int y_global_init = 2; /* Объявление другой глобальной переменной */ extern int x_global_init; int fn_a(int x, int y) { return(x+y); } int main(int argc, char *argv) { const char *message = "Hello, world"; return fn_a(11,12); }

Исходя из обоих диаграмм, мы можем видеть, что все точки могут быть соединены (если нет, то компоновщик выдал бы сообщение об ошибке).
Также компоновщик может заполнить все пустые места как показано здесь (на системах UNIX процесс компоновки обычно вызывается командой ld).

Так же, как и для объектных файлов, мы можем использовать nm для исследования конечного исполняемого файла.
Повторяющиеся символы
В предыдущей главе было упомянуто, что компоновщик выдаёт сообщение об ошибке, если не может найти определение для символа, на который найдена ссылка. А что случится, если найдено два определения для символа во время компоновки?
В C++ решение прямолинейное. Язык имеет ограничение, известное как правило одного определения (ODR — one definition rule), которое гласит, что должно быть только одно определение для каждого символа, встречающегося во время компоновки, ни больше, ни меньше. (Соответствующая глава стандарта C++ также упоминает некоторые исключения, которые мы рассмотрим несколько позже.)
Для C положение вещей менее очевидно. Должно быть точно одно определение для любой функции и инициализированной глобальной переменной, но определение неинициализированной переменной может быть трактовано как предварительное определение. Язык C таким образом разрешает (или по крайней мере не запрещает) различным исходным файлам содержать предварительное определение одного и того же объекта.
Однако, компоновщики должны уметь обходится также и с другими языками кроме C и C++, для которых правило одного определения не обязательно соблюдается.
Библиотеки
Теперь, после того как мы рассмотрели основы основ того, что делает компоновщик, мы можем погрузиться в описание более сложных деталей — примерно в том хронологическом порядке, как они были добавлены к компоновщику.
Главное наблюдение, которое затрагивает функции компоновщика, следующее: если ряд различных программ делают примерно одни и те же вещи (вывод на экран, чтение файлов с жёсткого диска и т.д.), тогда, очевидно, имеет смысл обособить этот код в определённом месте и дать другим программам его использовать.
Одним из возможных решений было бы использование одних и тех же объектных файлов, однако было бы гораздо удобнее держать всю коллекцию объектных файлов в одном легко доступном месте: библиотеке.
Статические библиотеки
Самое простое воплощение библиотеки — это статическая библиотека. В предыдущей главе было упомянуто, что можно разделять (share), код просто повторно используя объектные файлы; это и есть суть статичных библиотек.
В системах UNIX командой для сборки статичной библиотеки обычно является ar, и библиотечный файл, который при этом получается, имеет расширение *.a. Также эти файлы обычно имеют префикс «lib» в своём названии и они передаются компоновщику с опцией «-l» с последующим именем библиотеки без префикса и расширения (т.е. «-lfred» подхватит файл «libfred.a»).
В системе Windows статические библиотеки имеют расширение .LIB и собираются инструментами LIB, однако этот факт может ввести в заблуждение, так как такое же расширение используется и для «import library», которая содержит в себе только список того, что имеется в DLL — рассмотрим позже.
По мере того как компоновщик перебирает коллекцию объектных файлов, чтобы объединить их вместе, он ведёт список символов, которые не могут быть пока реализованы. Как только все явно указанные объектные файлы обработаны, у компоновщика теперь есть новое место для поиска символов, которые остались в списке — в библиотеке. Если нереализованный символ определён в одном из объектов библиотеки, тогда объект добавляется, точно также как если бы он был бы добавлен в список объектных файлов пользователем, и компоновка продолжается.
Обратите внимание на гранулярность того, что добавляется из библиотеки: если необходимо определение некоторого символа, тогда весь объект, содержащий определение символа, будет включён. Это означает, что этот процесс может быть как шагом вперёд, так и шагом назад — свежедобавленный объект может как и разрешить неопределённую ссылку, так и привнести целую коллекцию новых неразрешённых ссылок.
Другая важная деталь — это порядок событий; библиотеки привлекаются только, когда нормальная компоновка завершена, и они обрабатываются в порядке слева направо. Это значит, что если объект, извлекаемый из библиотеки в последнюю очередь, требует наличие символа из библиотеки, стоящей раньше в строке команды компоновки, то компоновщик не найдёт его автоматически.
Приведём пример, чтоб прояснить ситуацию; предположим у нас есть следующие объектные файлы и строка команды компоновки, которая содержит
a.o b.o -lx -ly
| Файл | a.o | b.o | libx.a | liby.a | ||||
| Объект | a.o | b.o | x1.o | x2.o | x3.o | y1.o | y2.o | y3.o |
| Определения | a1, a2, a3 | b1, b2 | x11, x12, x13 | x21, x22, x23 | x31, x32 | y11, y12 | y21, y22 | y31, y32 |
| Неразрешённые ссылки | b2, x12 | a3, y22 | x23, y12 | y11 | y21 | x31 |
Как только компоновщик обработал a.o и b.o, ссылки на b2 и a3 будут разрешены, в то время как x12 и y22 будут всё ещё неразрешёнными. В этот момент компоновщик проверяет первую библиотеку libx.a на наличие недостающих символов и находит, что он может включить x1.o, чтобы компенсировать ссылку на x12; однако, делая это, x23 и y12 добавляются в список неопределённых ссылок (теперь список выглядит как y22, x23, y12).
Компоновщик всё ещё имеет дело с libx.a, поэтому ссылка на x23 легко компенсируется, включая x2.o из libx.a. Однако это добавляет y11 к списку неопределённых (который стал y22, y12, y11). Ни одна из этих ссылок не может быть разрешена использованием libx.a, таким образом, компоновщик принимается за liby.a.
Здесь происходит примерно то же самое, и компоновщик включает y1.o и y2.o. Первым объектом добавляется ссылка на y21, но так как y2.o всё равно будет включено, эта ссылка разрешается просто. Результатом этого процесса является то, что все неопределённые ссылки разрешены, и некоторые (но не все) объекты библиотек включены в конечный исполняемый файл.
Заметьте, что ситуация несколько изменяется, если, скажем, b.o тоже имел бы ссылку на y32. Если это было бы так, то компоновка libx.a происходила бы так же, но обработка liby.a повлекла бы включение y3.o. Включением этого объекта мы добавим x31 к списку неразрешённых символов и эта ссылка останется неразрешённой — на этой стадии компоновщик уже завершил обработку libx.a и поэтому уже не найдёт определение этого символа (в x3.o).
(Между прочим этот пример имеет циклическую зависимость между библиотеками libx.a и liby.a; обычно это плохо.)
Динамические библиотеки
Будем рассматривать на следующих занятиях.
Язык C++
C++ предлагает ряд дополнительных возможностей сверх того, что доступно в C, и часть этих возможностей влияет на работу компоновщика.
Перегрузка функций и декорирование имён
Первое отличие C++ заключается в том, что функции могут быть перегружены, то есть одновременно могут существовать функции с одним и тем же именем, но с различными принимаемыми типами (различной сигнатурой функции):
int max(int x, int y) { if (x>y) return x; else return y; } float max(float x, float y) { if (x>y) return x; else return y; } double max(double x, double y) { if (x>y) return x; else return y; }
Такое положение вещей определённо затрудняет работу компоновщика: если какой-нибудь код обращается к функции max, какая именно имелась в виду?
Решение к этой проблеме названо декорированием имён (name mangling), потому что вся информация о сигнатуре функции переводится (to mangle — искажать, деформировать) в текстовую форму, которая становится собственно именем символа с точки зрения компоновщика. Различные сигнатуры переводятся в различные имена. Таким образом проблема уникальности имён решена.
Схемы отличаются от платформы к платформе.
Symbols from fn_overload.o: Name Value Class Type Size Line Section __gxx_personality_v0| | U | NOTYPE| | |*UND* _Z3maxii |00000000| T | FUNC|00000021| |.text _Z3maxff |00000022| T | FUNC|00000029| |.text _Z3maxdd |0000004c| T | FUNC|00000041| |.text
Здесь мы видим три функции max, каждая из которых получила отличное имя в объектном файле, и мы можем проявить смекалку и предположить, что две следующие буквы после «max» обозначают типы входящих параметров — «i» как int, «f» как float и «d» как double (однако всё значительно усложняется, если классы, пространства имён, шаблоны и перегруженные операторы вступают в игру).
Также стоит отметить, что обычно есть способ конвертирования между именами, видимых программисту, и именами, видимых компоновщику. Это может быть и отдельная программа (например, c++filt) или опция в командной строке (например —demangle для GNU nm), которая выдаёт что-то похожее на это:
Symbols from fn_overload.o: Name Value Class Type Size Line Section __gxx_personality_v0| | U | NOTYPE| | |*UND* max(int, int) |00000000| T | FUNC|00000021| |.text max(float, float) |00000022| T | FUNC|00000029| |.text max(double, double) |0000004c| T | FUNC|00000041| |.text
Область, где схемы декорирования чаще всего заставляют ошибиться, находится в месте переплетения C и C++. Все символы, произведённые C++-компилятором, декорированы; все символы, произведённые C-компилятором, выглядят так же, как и в исходном коде. Чтобы обойти это, язык C++ разрешает поместить
вокруг объявления и определения функций. По сути этим мы сообщаем C++-компилятору, что определённое имя не должно быть декорировано — либо потому что это определение C++-функции, которая будет вызываться кодом C, либо потом что это определение C-функции, которая будет вызываться кодом C++.
Инициализация статических объектов
Следующее выходящее за рамки С свойство C++, которое затрагивает работу компоновщика, — это существование конструкторов объектов. Конструктор — это кусок кода, который задаёт начальное состояние объекта. По сути его работа концептуально эквивалентна инициализации значения переменной, однако с той важной разницей, что речь идёт о произвольных фрагментах кода.
Вспомним из первой главы, что глобальные переменные могут начать своё существование уже с определённым значением. В C конструкция начального значения такой глобальной переменной — дело простое: определённое значение просто копируется из сегмента данных выполняемого файла в соответствующее место в памяти программы, которая вот-вот-начнёт-выполняться.
В C++ процесс инициализации может быть гораздо сложнее, чем просто копирование фиксированных значений; весь код в различных конструкторах по всей иерархии классов должен быть выполнен, прежде чем сама программа фактически начнёт выполняться.
Чтобы с этим справиться, компилятор помещает немного дополнительной информации в объектный файл для каждого C++-файла; а именно это список конструкторов, которые должны быть вызваны для конкретного файла. Во время компоновки компоновщик объединяет все эти списки в один большой список, а также помещает код, которые проходит через весь этот список, вызывая конструкторы всех глобальных объектов.
Обратим внимание, что порядок, в котором конструкторы глобальных объектов вызываются, не определён — он полностью находится во власти того, что именно компоновщик намерен делать.
Шаблоны
Ранее мы приводили пример с тремя различными реализациями функции max, каждая из которых принимала аргументы различных типов. Однако, мы видим, что код тела функции во всех трёх случаях идентичен. А мы знаем, что дублировать один и тот же код — это дурной тон программирования.
C++ вводит понятия шаблона (templates), который позволяет использовать код, приведённый ниже, сразу для всех случаев.
template <class T> T max(T x, T y) { if (x>y) return x; else return y; } int main() { int a=1; int b=2; int c; c = max(a,b); // Компилятор автоматически определяет, что нужно именно max<int>(int,int) double x = 1.1; float y = 2.2; double z; z = max<double>(x,y); // Компилятор не может определить, поэтому требуем max<double>(double,double) return 0; }
Этот написанный на C++ код использует max<int>(int,int) и max<double>(double,double). Однако, какой-нибудь другой код мог бы использовать и другие инстанции этого шаблона.
Каждая из этих различных инстанций порождает различный машинный код. Таким образом, на то время, когда программа будет окончательна скомпонована, компилятор и компоновщик должны гарантировать, что код каждого используемого экземпляра шаблона включён в программу (и ни один неиспользуемый экземпляр шаблона не включён, чтобы не раздуть размер программы).
Как же это делается? Обычно используется прореживание повторяющихся экземпляров. Каждый объектный файл содержит код всех повстречавшихся шаблонов. Определения помечаются как слабые символы, и это значит, что компоновщик при создании конечного выполняемого файла может выкинуть все повторяющиеся экземпляры одного и того же шаблона и оставить только один. Самый большой минус в этом подходе — это увеличение размеров каждого отдельного объектного файла.
Практика: сборка статической библиотеки на Linux
$ gcc -c a.c $ gcc -c b.c $ ar -q libfoobar.a a.o b.o $ gcc main.c -L. -lfoobar $ ./a.out
Полезные ссылки
- Руководство новичка по эксплуатации компоновщика — Habrahabr
- ELF Object File Format
- ELF Sections & Segments and Linux VMA Mappings
- Программирование в Linux с нуля — OpenNET
- GCC and Make — Compiling, Linking and Building C/C++ Applications
Russian (Pусский) translation by Ilya Nikov (you can also view the original English article)
В этой второй и заключительной части этой серии мы рассмотрим плагин Jenkins Workflow в качестве решения для создания более сложных конвейеров Jenkins.
Мы продолжим там, где часть первой из серии прекратилась. В первой части Джефф Рейфман провел вас через создание экземпляра Jenkins в Digital Ocean и создание вашей первой сборки Jenkins. Если вы еще этого не читали, я предлагаю сделать это, прежде чем продолжить. Все в порядке — я буду ждать. Я могу быть очень терпеливым …
… Все догнали? Отличное! Давайте сделаем это.
Что такое рабочий процесс Дженкинса?
Jenkins Workflow — это плагин для Jenkins. После установки появляется новый тип элемента: «Workflow». Проекты Workflow могут использоваться для тех же целей, что и обычные проекты «Freestyle» Jenkins, но они также могут организовать гораздо более крупные задачи, которые могут охватывать несколько проектов, и даже создавать и управлять несколькими рабочими пространствами в одном рабочем процессе. Более того, все это управление может быть организовано в один скрипт, а не распространено через коллекцию конфигураций, проектов и шагов.
Предварительный процесс
Прежде чем мы начнем создавать Workflow, нам нужно установить плагин Jenkins Workflow. На панели инструментов Jenkins выберите «Управление Jenkins», затем «Управление плагинами». Перейдите на вкладку «Доступные» и найдите «Рабочий процесс».
Установите флажок для плагина Workflow, затем Установить без перезагрузки.
Теперь, готово. Существует несколько плагинов с именем «Workflow Plugin», поэтому вам нужно будет повторить вышеуказанные шаги несколько раз. Кроме того, вы также можете щелкнуть несколько флажков или установить плагин агрегатора рабочего процесса.
После того, как в списке доступных плагинов больше не отображается «Workflow Plugin», запустите Jenkins, перейдя в /restart и нажав «Да».
Простой поток
Давайте сделаем наш Workflow. Мы возьмем проект Jeff, созданный в первой части, и построим его как Workflow.
Для начала зайдите в панель инструментов Jenkins и нажмите «Новый элемент». Назовите новый элемент «Shell Test (Workflow)» и выберите тип Workflow.


Нажмите «ОК», чтобы создать новый проект. Вы попадете на страницу конфигурации проекта.


Вы заметите, что параметры конфигурации отличаются от стандартных проектов Jenkins. Больше не существует вариантов добавления репозитория GitHub, создания шагов или действий после сборки. Вместо этого есть новый раздел Workflow.
В разделе «Рабочий поток» находится текстовое поле с надписью «Сценарий». Именно здесь вы будете определять сценарий Workflow, который будет выполняться Jenkins, когда он инициализирует сборку проекта.
«Какой тип сценария?» Спросите вы. Отличный вопрос. Плагин Jenkins Workflow использует для скриптов язык Groovy. Groovy — это универсальный скриптовый язык для JVM. Не волнуйтесь, вам не нужно знать Groovy или Java, чтобы заставить все работать — плагин Jenkins Workflow использует небольшую DSL поверх Groovy, и очень легко комбинировать команды для создания рабочего процесса вашего проекта.
Идем дальше и добавляем в окно сценария следующее:
1 |
node { |
2 |
git 'https://github.com/redhotvengeance/hello-jenkins.git' |
3 |
sh 'uptime' |
4 |
}
|
Так что здесь происходит?
Прежде всего, мы открываем блок node. Node — это место, где происходят действия Workflow. При назначении node создается новое рабочее пространство (контекст / папка). Весь код внутри блока node выполняется внутри этого рабочего пространства. Это помогает гарантировать, что шаги сборки не загрязняют друг друга.
Затем мы запускаем команду Git git 'https://github.com/redhotvengeance/hello-jenkins.git'. Эта команда клонирует Git репозиторий в наше рабочее пространство.
Наконец, мы говорим Workflow о выполнении команды оболочки uptime с sh' uptime.


Нажмите «Сохранить», и вы попадете на целевую страницу проекта. В левом меню находится кнопка «Собрать сейчас». Нажмите на нее, чтобы начать сборку.


Как только сборка будет завершена, нажмите на сборку #1, найденную в разделе «История сборки». Затем нажмите «Консольный вывод» в левом меню.


Здесь мы можем увидеть все, что было записано во время сборки. Она началась с выделения node в рабочей области «Shell Test (Workflow)». Затем он стунял Git репозиторий. Наконец, он выполнил команду uptime, которая печатала статистику времени безотказной работы сервера.
Вот и все! Мы теперь воссоздали те же шаги, что и обычная настройка проекта Jenkins в первой части, за исключением того, что это был рабочий процесс. Теперь давайте использовать те же самые концепции, чтобы сделать что-то более сложное.
Подделайте это, пока не сделаете это
Прежде чем мы сможем создать наш сложный Workflow, нам нужна работа, которая пройдет через него. Поддельный проект (ы) на помощь!
Поскольку мы уже используем Groovy для написания нашего Workflow, давайте использовать Gradle для наших поддельных проектов. Gradle — это система сборки, которая использует Groovy (удивительно, я знаю!). Чтобы использовать Gradle, нам нужно установить его на нашем сервере. SSH на ваш сервер (проверьте часть Джеффа, если что-то забыли) и запустите:
1 |
sudo apt-get install gradle |
Двигаемся дальше.
Мы будем использовать два репозитория в нашем новом Workflow. Первый — строитель. Наш проект строителя очень прост: в нем есть скрипт сборки Gradle со следующим кодом:
1 |
task createBuild << { |
2 |
new File("built.txt").write("You cannot pass.n") |
3 |
}
|
Так что здесь происходит? Gradle работает, выполняя «задачи», а скрипт сборки Gradle определяет эти задачи. Мы определили задачу, называемую createBuild, и что она делает, это создать текстовый файл с именем build.txt со следующим содержимым:
Вы не пройдете.
Это оно. (Хорошо, я говорил, что это было просто!)
Второй Git-репо — наш упаковщик. У упаковщика также есть скрипт сборки Gradle, но он немного сложнее:
1 |
task createPackage << { |
2 |
String packageText = "I am a servant of the Secret Fire, wielder of the flame of Anor. You cannot pass. The dark fire will not avail you, flame of Udûn. Go back to the Shadow!" |
3 |
String builtText = new File('built.txt').text |
4 |
new File("package.txt").write(packageText + "nn" + builtText) |
5 |
}
|
Задача createPackage также создает текстовый файл (называемый package.txt), но он рассчитывает использовать контент из файла build.txt, которого нет в репозитории упаковщика. Если в репо существовал build.txt, сгенерированный файл package.txt содержал бы:
Я слуга Секретного Огня, обладателя пламени Анора. Вы не можете пройти. Темный огонь не поможет вам, пламя Удэна. Вернитесь к Тени!
Вы не можете пройти.
Если build.txt отсутствует, наша задача createPackage выдает ошибку.
Поэтому каждый раз, когда мы создаем наш упаковщик, нам нужно сначала запустить наш построитель и сделать полученный build.txt доступным для упаковщика, чтобы он мог создавать package.txt.
И это именно то, для чего мы будем создавать Jenkins Workflow!
Пусть поток работ через вас
Подойдите к панели инструментов Jenkins, нажмите «Новый элемент», назовите его «Ассемблер», выберите «Рабочий процесс» и нажмите «ОК».


Давайте начнем писать сценарии. Во-первых, как и раньше мы откроем блок node:
Затем давайте склонируем репозиторий нашего строителя:
1 |
node { |
2 |
git 'https://github.com/redhotvengeance/jenkins-workflow-build.git' |
3 |
}
|
Теперь нам нужно запустить скрипт сборки Gradle для создания файла build.txt:
1 |
node { |
2 |
git 'https://github.com/redhotvengeance/jenkins-workflow-build.git' |
3 |
sh 'gradle createBuild' |
4 |
}
|
Наконец, надо удостовериться, что все работает так, как мы ожидаем. Мы добавим cat, чтобы распечатать содержимое файла build.txt:
1 |
node { |
2 |
git 'https://github.com/redhotvengeance/jenkins-workflow-build.git' |
3 |
sh 'gradle createBuild' |
4 |
sh 'cat ./built.txt' |
5 |
}
|
Нажмите «Сохранить», а затем запустите сборку. Как только это будет сделано, взгляните на вывод консоли.


Отлично! Мы успешно клонируем репозиторий, запускаем задачу createBuild и подтверждаем, что содержимое build.txt содержит строку You cannot pass.. Теперь об упаковщике.
Как и у строителя, нам нужно клонировать наш репозиторий. Давайте добавим код упаковщика:
1 |
node { |
2 |
git 'https://github.com/redhotvengeance/jenkins-workflow-build.git' |
3 |
sh 'gradle createBuild' |
4 |
sh 'cat ./built.txt' |
5 |
}
|
6 |
|
7 |
node { |
8 |
git 'https://github.com/redhotvengeance/jenkins-workflow-package.git' |
9 |
sh 'gradle createPackage' |
10 |
sh 'cat ./package.txt' |
11 |
}
|
Поскольку мы явно не создавали новое рабочее пространство, задача createPackage будет работать в том же рабочем пространстве, что и задание createBuild, что означает, что файл build.txt, ожидаемый от него, будет доступен для него.


Идем дальше, а нажимаем Сохранить и Собрать сейчас, а затем просмотрим вывод консоли.


Все выполнилоась, как ожидалось, — наш строитель был клонирован и выполнился, и наш упаковщик был клонирован и тоже выполнился. И если мы посмотрим на результат — вот оно! «Балрог Моргот» был полностью Гэндальфом.
Круто! но разве это немного не …
Надумано? Вероятнее всего.
Но сложная концепция — это всего лишь куча простых концепций, сплетенных вместе. На поверхности мы собрали речь Гэндальфа на мосту Хазад-дем. Но на самом деле мы взяли сборку одного проекта и ввели его в сборку другого проекта.
Что, если вместо диалога Гэндальфа выходы сборки были исполняемыми файлами из отдельных кодовых баз, которые все должны собираться вместе для программного обеспечения, которое вы отправляете? Вы должны использовать тот же рабочий процесс, который мы создали здесь: клонирование, создание, копирование и упаковка. С плагином Jenkins Workflow все, что нужно, это несколько строк Groovy. И в качестве бонуса все содержится в одном скрипте!
Существуют также другие инструменты для управления и визуализации рабочего процесса Jenkins. CloudBees предлагает функцию просмотра рабочего процесса на своей корпоративной платформе Jenkins.


Мы лишь поверхностно коснулись того, что можно сделать с помощью плагина Jenkins Workflow. Обязательно ознакомьтесь с приведенными ниже ссылками, чтобы узнать больше.
Удачи с вашими процессами!
Ссылки по теме
- Сайт Дженкинса
- Страница плагина рабочего процесса Jenkins
- Плагин рабочего процесса Jenkins GitHub
- Учебное пособие по Jenkins Workflow Plugin
- Документация плагина Workflow CloudBees Jenkins
- Видео по интерфейсу Jenkins Workflow