Тестирование в больших компаниях, в enterprise, чаще всего дело сложное и неблагодарное. Разрыв между бизнес-подразделениями и IT огромный: когда разработчик имеет видение на уровне кода, а проверку – на уровне модульных тестов, а заказчик мыслит работающими или неработающими даже не услугами, а целыми процессами, выходящими за рамки одной команды разработки, а то и целого подразделениякомпании. И просит организовать бизнес-тестирование, или сквозное тестирование, или тестирование на основании сценариев от начала и до конца (end 2 end).

Давайте начнём с самого начала – с двух столпов, откуда появилось это пресловутое «сквозное бизнес-тестирование», а именно с пирамиды тестирования и со стандарта ISO9000.
Пирамида тестирования
С пирамидой тестирования, наверняка знаком любой тестировщик, поднаторевший в своей профессии и набившей шишек при общении со смежными подразделениями. Особенно часто к ней приходится апеллировать при обосновании автоматизации тестирования. Какие тесты дешевле и важнее разработать? А запустить?

Суть пирамиды тестирования не хитрая: в основе тестирования следует использовать самые простые и самые быстрые в написании и исполнении тесты – модульные тесты. Конечно, проверка интерфейсов классов и функций вряд ли та вещь, которую можно показать заказчику, но без этого прочного, монолитного, безотказного фундамента вряд ли что-то получится выстроить выше. Как правило несколько десятков функций, методов, классов реализуют какую-либо функциональность для заказчика, и по сути десяток модульных тестов можно свести к каким-то верхнеуровневым тестам. Заказчику нужна уже красивая квартира с отделкой, но при этом вряд ли он останется довольным, когда перекошенные окна в его квартире перестанут открываться, а пол и потолок пойдёт трещинами от первого подувшего ветерка. Однако самому заказчику зайти в квартиру и проверить её качество может быть не самой лучшей идеей. Согласитесь, сложно пользователю проверить качество бетона в фундаменте, так и воспроизвести все погодные условия. Так и в тестировании, конечно, верхнеуровневое тестирование нужно, то только тогда, когда у нас отработали модульные тесты, так и тесты уже более высокого уровня.

Сложнее в разработке и дольше в исполнении более высокоуровневые тесты – интеграционные тесты, которые проверяют корректность работы одновременно работающих модулей, над которыми трудилась вся команда, выпуская свой продукт (систему). То есть проверяется интеграция кода, тестируется система без учёта взаимодействия со внешними системами. Такие тесты уже подразумевают проверку высокоуровневую, скорее всего через обращение к систему через системное API или даже GUI (фронт). Работа с таким типом тестов сложнее – чтобы покрыть все ветки и нюансы кода нужно, скорее всего, задействовать большое количество сильно пересекающихся проверок на различных тестовых данных, а при автоматизации зачастую разрабатывать целый ворох условий и ветвлений в скриптах. То есть, с одной стороны мы уже приблизились к пользователю, усложнив себе жизнь, но с другой стороны, нам ещё сложно находить общий язык, нам это обходится дороже, а качества проверок всё ещё недостаточно. То есть мы можем запустить заказчика в новую квартиру, он может всё проверить, но без учёта взаимодействия с другими жильцами, погодными условиями и коммунальными службами. Согласитесь, толка от идеального мира, модели, в реальной жизни, как правило, немного.

Если мы добавим и эти условия – посмотрим как наша система взаимодействует со внешними системами – поставщиками и потребителями, с нашим окружением, то есть проведём системное тестирование, то легко увидим, что сложность тестирования тоже возрастёт. Нам нужно будет добиваться одновременной работоспособности всех взаимодействующих систем, хотя и без привлечения специалистов по ним. Нам пока что достаточно просто принять какие-то данные от наших поставщиков и передать наши данные нашим потребителям. В правильной последовательности и формате. Дальнейшая судьба данных нас не волнует. Главное – наша система работает правильно в правильном окружении. И всё бы тут хорошо – для нашего заказчика мы можем провести уже полномасштабную демонстрацию, да только в реальной жизни это ещё не все критерии успеха для нашей разработки. Конечно хорошо, что у заказчика появилась его квартира в прочном доме, но если от неё надо добираться, перелезая через колючую проволоку, затем на каноэ по озеру с крокодилами в шалаши, кишащие змеями, то, возможно, мы что-то не то и не там сделали?

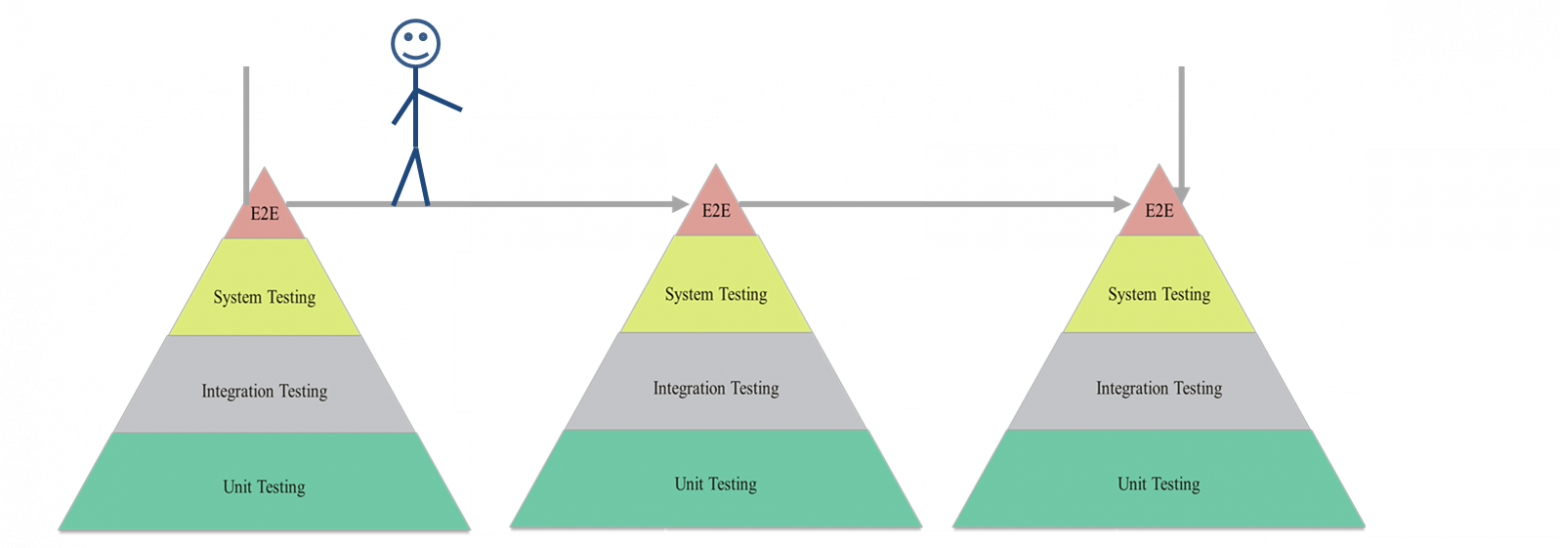
Поэтому тут первая идея для сквозного тестирования – проверять не только наше окружение, но и все взаимосвязанные системы, через которые проходят данные принимаемые или отправляемые нашей системой. А это, в свою очередь, означает, что мы должны будем совместить несколько таких «пирамид тестирования» между собой. Постройка хрупкого моста, по которому мы проведём за ручку данные, ценные для пользователя.
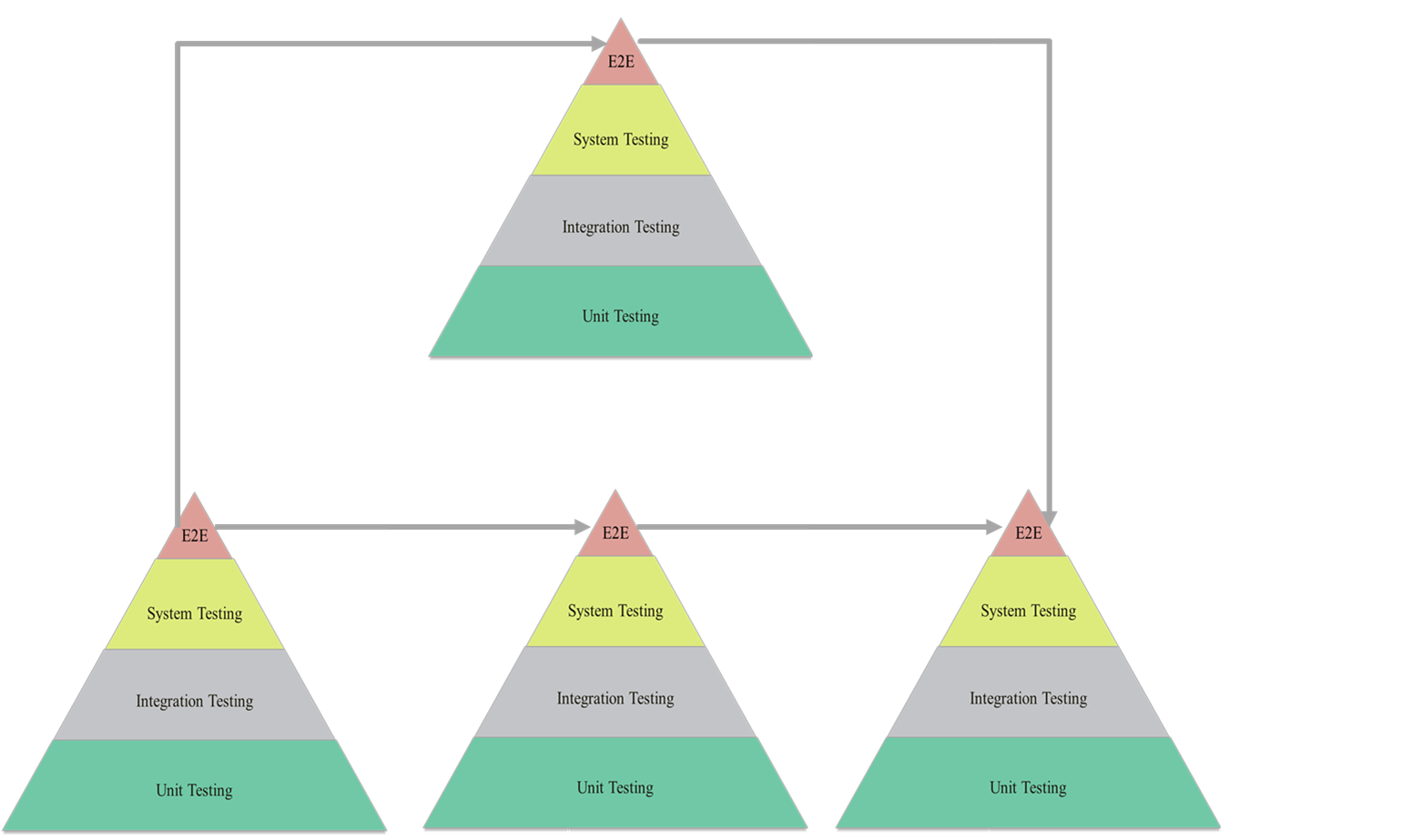
Вот только вопрос как это делать? Кому это делать? Как собирать воедино?
ISO9000

Серия стандартов, описывающих системы менеджмента качества, в том числе говорит о том, что любой процесс в организации должен быть описан, задокументирован, даже если это процесс выдачи граблей по осени дворнику. А раз так, что ни один процесс, который проходит внутри ПО, используемого и разрабатываемого в организации, не может не быть описан. Вопрос в том, как это делать? Конечно, лучшее описание, с точки зрения BDD — это описание поведения тестами, под которыми будет лежать пирамида тестирования. Но мы сразу же вернёмся к нашей дилемме с объединением нескольких пирамид тонкими канатами от верхушки к верхушке, по которым без страховки будет ходить наш канатоходец-заказчик и его пользователи.
Process approach is a management strategy that requires organisations to manage its processes and the interactions between them. Thus you need to consider each major process of the company and their supporting processes.
Поэтому проще всего воспользоваться абстракциями – создать хотя бы схему процесса, и указать её входы и выходы, сделать процесс контролируемым и измеряемым, обеспечить взаимосвязь с родительскими и дочерними процессами, как того и требует ISO9000
All processes have:
• inputs;
• outputs;
• operational control;
• appropriate measurement & monitoring.
Each process will have support processes that underpin and enable the process to become realised

Для этой цели лучше всего подходят бизнес-диаграммы, и чаще всего используются стандарты вроде UML, BPMN, ARIS и пр. А сами процессы становятся блок-схемами с нанизанными на них «кубиками». Между «кубиками» происходит взаимодействие, в стандарте BPMN — это поток действий и поток сообщений. И вот это как раз то, что нам нужно!

Любая компания, которая хочет иметь сертификат и следует стандарту ISO9000, скорее всего, обзавелась такими схемами, и они являются неотъемлемой частью верхнеуровневых требований. Если в компании работают хорошие аналитики, то, скорее всего, к низкоуровневым требованиям будут спускаться ссылки-требования на отдельные действия из схем. Они-то нам и нужны.
Фактически, на схемах мы можем увидеть процесс целиком, и понять, какой сценарий нам нужно построить, и к какой системекоманде бежать с какими данными в какой момент.
Я тут не преуменьшаю труд разработчиков, которые пишут грамотный код, который пересылает сообщения между разными частями программно-аппаратных комплексов, но всё держать в уме невозможно. И когда процесс используется во множестве других процессов, лучше иметь такую «карту» при себе для проведения грамотного тестирования, и, тем более для построения тестовой модели.
Что на практике
Итак, мы имеем две вводных – у каждой командысистемы должна быть подготовлена пирамида из тестов – от самых мелких, модульных тестов, до сложных системных тестов, а так же тот факт, что в рамках организации у нас обязаны быть описаны требования в виде бизнес-процессов. Этот факт нам позволит быстро ответить заказчику, какой бизнес-процесс как работает, и на каком моменте из-за чего ломается, а самим, при получения дефектов с промышленной эксплуатации быстро произвести root cause analysis (анализ корневых причин возникновения дефектов). В теории.
А на практике всё опять ложится на тестировщика – как из вороха тестов, тем более чужих, выбрать нужные, выстроить их в цепочку, а на вход каждой из систем подать нужные данные и сверить с корректно определённым ожидаемым результатом?

Самый простой вариант – изначально разрабатывать тесты на основании бизнес-моделей, а деление команд делать по проектам, реализующим тот или иной бизнес-процесс. Для этого в некоторых инструментах управления тестированием есть уже возможность загружать BPMN-схемы (например для HPE ALM – поддерживается загрузка в формате XPDL). HP ALM сам разобьет схему на набор требований (действий), а при желании создаст иерархию требований (модуль Requirements->Business Models). Далее наше дело покрыть требования тестами, а далее выстроить требования, а значит и тесты в цепочки, покрывающие наш бизнес-процесс. Эти цепочки в HPE ALM называются «путями» (path), и позволяют увидеть все комбинации последовательностей. При желании требования, цепочки можно сразу сконвертировать в тесты.


Но даже если не использовать инструменты тестирования, всё равно придётся из бизнес-процесса составлять цепочки. Тем более учитывая несовершенство инструментов (не всё так радужно), а так же тот факт, что, скорее всего, тестовую модель нужно будет собирать пост-фактум, а исполнять и вовсе в виде регресса «общей командой», не прилепленной к новым проектам.

Сколькими путями может дойти белочка до шишки?
В этом случае нам нужно будет открыть тесты каждой из команд, найти привязанные к фигурирующим в бизнес-модели требованиям, и выстроить из них цепочки, сохранив в «общем пространстве». Создание общего пространства – это какой-то суррогат, но в любом случае оно должно быть, пусть в виде амбарной книги, excel, или проектной области в инструменте управления тестированием. Если снова говорить о HPE ALM, то за данный функционал отвечает модуль BPT (Business Process Testing), заодно позволяющий передавать результаты одного теста в параметры другого. Впрочем, при желании и упорном труде на HPE ALM это возможно и реализовать через перестроения тестовых наборов (Test set) в поток выполнения (Execution flow). Тогда при запуске полного набора будут по очереди вызываться тестировщики, ответственные за прохождения каждой из компонент сквозного сценария.

И, увы, одним лишь средством управления тестирования не обойтись. Из моей практики, почти что все инструменты имеют какие-то фатальные недостатки, и поэтому, если вы дойдёте до этапа автоматизации тестирования по бизнес-процессу – то придёте к созданию скрипта, который будет дёргать в нужной последовательности тесты.

В итоге, можно сделать два вывода:
1) для сквозных сценариев используются с большой долей вероятности уже ранее разработанные тесты для каждой из систем, входящей в цепочку (сценарий) бизнес-процесса
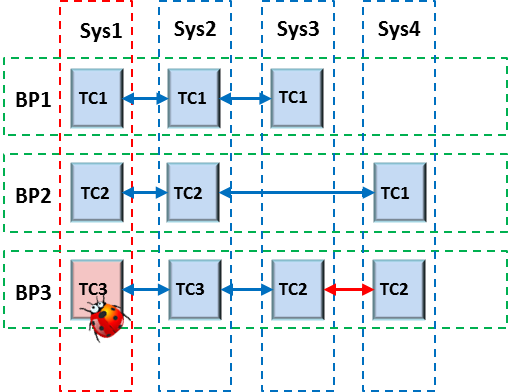
Можно все полные тестовые наборы компании представить в виде разреженной матрицы, где по столбцам распределены тесты для каждой системы (для простоты – системные), а по строкам – бизнес-процессы. То есть для тех или иных бизнес-процессов надо выбратьсоздать тесты, покрывающие бизнес-процесс, установить взаимосвязи. Если покрытия нет – это повод восполнить пробелы в тестовой модели, либо удостовериться, что качество обеспечивается другими уровнями тестирования (интеграционное тестирование, модульное тестирование, ревью кода и прогон его через анализаторы).
2) Необходим инструмент наблюдения, трассирования и актуализации бизнес-процесса на предмет синхронизации с тестовой моделью.
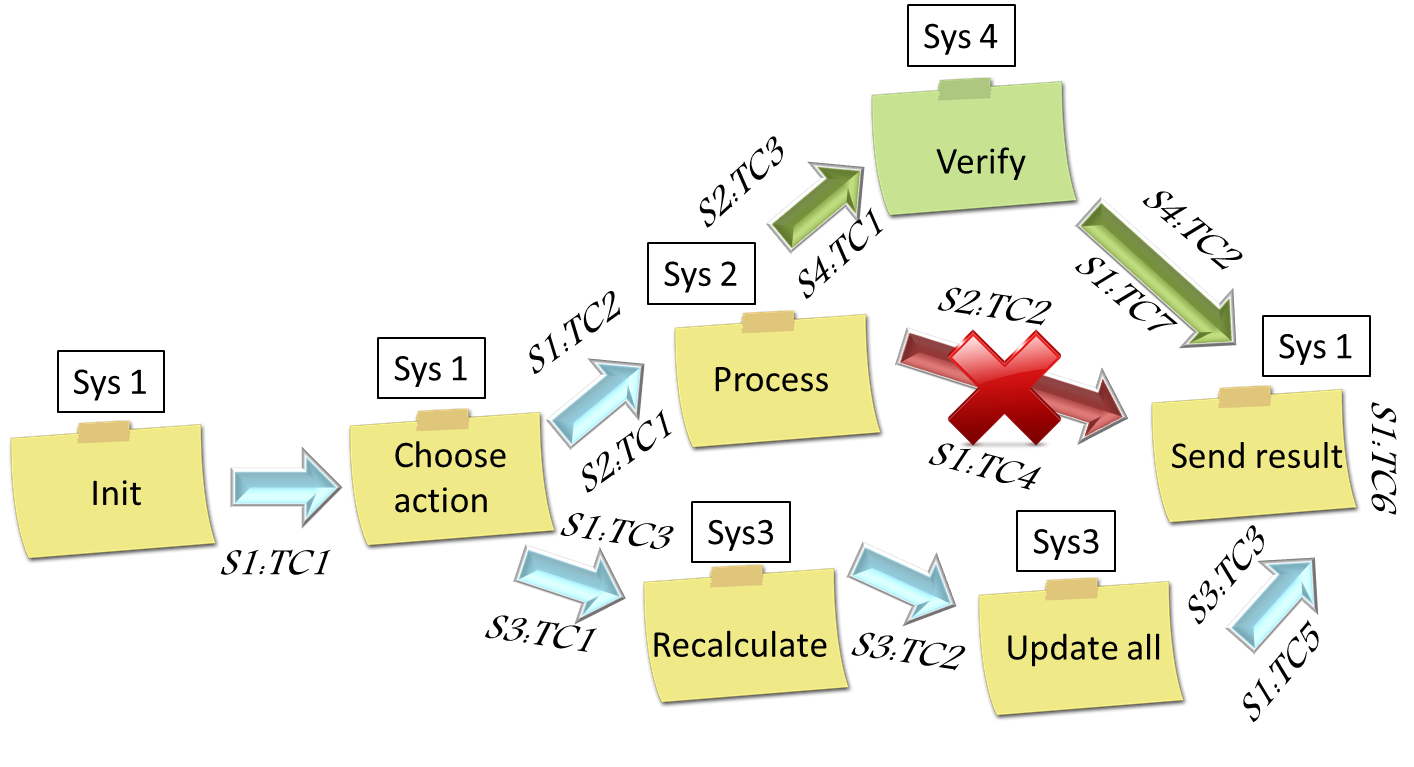
И если с созданием тестовой модели инструменты тестирования более-менее сносно справляются, то с актуализацией всё в действительности очень плохо, зачастую проще модель пересоздать заново, чем пытаться увидеть изменения в процессе и тестовой модели. И опыт реальных команд говорит о том, что лучше создавать живую визуализацию архитектуры. Проще всего это сделать в общей зоне, воспользовавшись простой маркерной доской и стикерами. Тогда, команды, которые участвуют в бизнес-процессе могут наглядно видеть, как видоизменяется процесс (убираются и добавляются связи, убираются и добавляются действия). Главное – чтобы все имели доступ к доске. Плюс, обратите внимание, что если в процессе подразумевается сообщений между системами, то, как правило, хотя бы должно быть два теста от каждой системы – на отправку и на приём данных. Впрочем, вместо стикеров можно использовать целый лего-город (из крупных блоков), или что-то ещё более креативное. Главное тут – один язык и одно информационное пространство, чего очень в enterprise не хватает.
В заключение
Организация наглядного и правильного тестирования по бизнес-процессам – сложная и очень дорогая вещь. Обратите внимание, что E2E тестирование – это не просто приёмка, пользовательское тестирование, которое будет выполнять заказчик, это выстраивание мостика, с учётом всех возможных ситуаций, по которому пойдёт заказчик и поведёт за собой в ногу пользователей.

Ещё раз – E2E – это не прогулка на Ладе-Калине через мост, и даже не проезд на двух камазах. Это сложная инженерная работа, обвешивание мостов датчиками и проведение всех возможных проверок и ситуаций — по крайней мере описание этих сценариев.
Нужно или нет вашей компании такой идеальный чистовой прогон – дело исключительно ваших целей и потребностей. Всегда, как и при любом тестировании, следует оценить потенциальные риски от пропущенных дефектах на этой стадии, так и стоимость работ по подготовке и проведения сквозного тестирования. Оценить, что из этого обойдётся вам дороже и только потом действовать. Но в случае сквозного тестирования по бизнес-процессам следует помнить, что оно не имеет смысла без прочного фундамента в виде 100% passrate unit-тестов (~90-100% coverage), без интеграционных тестов (~60-80% coverage, 90-100% passrate), без системных тестов (20-40% coverage, 80-100% passrate). Устанавливать критерии успешности (quality gates) – это больше требования к качеству выпускаемого продукта, главное здесь помнить, что объем E2E тестов – лишь верхушка пирамиды (1-2% coverage, ~99% passrate), которая не должна быть больше его основания, не быть при этом затычкой дыр с предыдущих этапов. Это – дополнение, которое априори считается закрытым на предыдущих этапах.
Организация подобного тестирования – главным образом работа по подготовке и синхронизации тестовых случаев и данных (тест-аналитика), а так же комплекс организационных мероприятий, синхронизация команд в одном месте в одно время на работоспособном тестовом полигоне. Помня это, не следует пробовать показывать заказчику «сквозное тестирование» раньше срока, чтобы не тратить время сразу большого количества людей без всех работающих компонентов, собранных воедино.
P.S. описанные инструменты, а так же практики – сугубо для примера, автор не ставил цели себе рекламировать продукты и декламировать единственно верным данный подход к сквозному тестированию.
Сквозное тестирование, оно же End-to-end или E2E, — это процесс тестирования, при котором происходит подробная эмуляция пользовательской среды. То есть при данном тестировании имитируют:
щелчки мышью,
нажатия на кнопки,
заполнение форм,
переходы по страницам и ссылкам,
и другие поведенческие факторы.
Суть этого тестирования — посмотреть, так ли работает программа для конечного клиента, как рассчитывалось изначально? При этом нужно учитывать, что пользователю все равно, функционирует ли программа «как надо», ему главное, чтобы программа функционировала и оправдывала ожидания, поэтому основной упор делается на корректное функционирование.
Е2Е—процесс — это конечный этап тестирования, после него никакого тестирования не проводят. Он самый трудозатратный и дорогой, именно поэтому находится на вершине пирамиды тестирования.
Е2Е—процесс — что это?
Е2Е—процесс происходит при помощи сложных программ для тестирования, написанных специально для тестирования или «вручную», от этого данный процесс требует много времени и затрат. Поэтому до его применения обычно проводят более дешевые и нетребовательные виды тестирования.
К примеру, компания Гугл при разработке своих продуктов следует правилу «70-20-10», цифры которого показывают процентное соотношение от общего количества тестов, то есть:
70% занимают юнит-тесты;
20% занимают интеграционные тесты;
10% занимают Е2Е—тесты.
Конечно, такая комбинация тестов не является эталонной. Для каждого проекта она будет своя. Но идея в том, что количество Е2Е—тестов должно быть куда меньше, чем остальных тестов. В некоторых проектах сквозного тестирования вообще может не быть, так как unit-тесты и интеграционные тесты покрывают все процессы программы. А иногда просто их нецелесообразно проводить из-за того, что проект небольшой и тестируемый функционал может быть еще много раз переписан. Поэтому можно сказать, что E2E — это процесс больших и сложных проектов.
Какие бывают Е2Е—тесты
Нет единого алгоритма сквозного тестирования, так как многое будет зависеть от сложности самого проекта и что конкретно нужно тестировать. Е2Е — это лишь название процесса тестирования, а не его метод или алгоритм. Но при этом выделяют два основных типа сквозного тестирования, на которых мы немного остановимся.
Типы Е2Е—тестирования:
Метод «черного ящика». Это специальный E2E-процесс тестирования, при котором само тестирование проводится только с интерфейсом пользователя. «Черным ящиком» называется, потому что тестировщика интересуют только проблемы интерфейса: работоспособность функций, ошибки при взаимодействии, ошибки при определенном поведении пользователей и т. д., и его абсолютно не интересует, как это все работает внутри программы. В большинстве случаев тестировщик даже не понимает, как с помощью кода получается тот или иной функционал. Такой тип тестирования считается самым распространенным.
Метод «белого ящика». В этом типе тестирования тестировщику известна «внутренняя кухня» программы. А это значит, что ему известно, как себя должна повести программа при определенном действии пользователя. Он анализирует, совпадает ли задуманный результат поведения с реально происходящим, и понимает, где нужно вносить необходимые корректировки.
Любой сквозной тест — это:
в первую очередь тестирование UI;
тяжелый и медленный тест;
применение метода «черного ящика» и найм сторонних тестировщиков, никак не связанных с разработкой программы;
тяжелый «отлов» найденной проблемы;
тестирование всех модулей и всех систем целиком, поэтому требуется сложный и эффективный софт или работа «руками»;
гарантия, что программа работает так, как задумано, или нет.
Заключение
Е2Е — это дорогой и сложный процесс тестирования, к которому нужно подготавливаться основательно. Давайте проведем аналогию с мостом. Мост через реку — это тестируемая программа. Так вот Е2Е—тестирование — это не просто проехать по мосту груженными КАМАЗами и смотреть издалека: выдержит или не выдержит. Е2Е — это куча всевозможных датчиков, расставленных по всему мосту, которые сигнализируют о каждом шаге и готовы фиксировать любой сценарий развития на «мосту»:
перегруз;
колебания;
микротрещены;
нагрузку на каждый трос или балку;
поведение моста при наводнении, землетрясении, пожаре или аварии на нем;
и др.
Нужен или нет Е2Е именно вашей компании/программе/разработке? Это дело индивидуальное и зависит только от поставленных целей и потребностей. Практика показывает, что до сквозного тестирования должно проводиться множество других более простых тестов и на основе полученных от них результатов решается, нужен ли проекту Е2Е—тест или нет.

Не так давно у нас случилась полная неразбериха с тестированием. Быстрый рост проекта, новые команды, новые люди. Неожиданно, всё это негативно повлияло на качество продукта.
В данной статье поделюсь опытом и расскажу, как мы осознали проблему, искали пути её решения и что в итоге нам помогло. История борьбы за качество 
Для начала, определимся с тем, что такое end-to-end тестирование.
End-to-end (E2E) — это верхушка пирамиды тестирования. Можно сказать, что это конечный этап тестирования. Проводя E2E, мы смотрим, как выглядит функциональность для её конечных пользователей. Всё ли работает так, как планировалось? Все ли потребности пользователя удовлетворяются?
При таком тестировании на первый план выходит именно то, что будет видеть пользователь. Как работает система изнутри, на данном этапе уже не проверяется (т.к. это задачи других уровней пирамиды тестирования). Мы смотрим на картинку в целом.
Немного предыстории:
Наш проект появился 2 года назад, когда один из Клиентов крупного Поставщика платформы для проведения электронных экзаменов и сертификаций захотел купить эту платформу и разрабатывать её своими силами.
Основными нашими задачами стало следующее:
-
Поддержание уже имеющегося функционала. Платформа крупная, существует более 20 лет. С её помощью можно пройти весь путь от создания контента для теста до оценки пройденного кандидатом экзамена. Составных частей очень много, и наша задача — следить за их работоспособностью и взаимодействием.
-
Оптимизация уже имеющегося функционала. Как бы ни было хорошо, всегда можно сделать лучше.
-
Разработка нового функционала. Главная причина, по которой появился наш проект. Вышеупомянутый Клиент видел свой вектор развития платформы, поэтому и было принято решение пойти своим путём.
Так мы и начали работать. На старте у нас было всего 2 команды, в каждой по 2 тестировщика. Взаимодействие выстраивалось крайне просто.
Во-первых, у всех есть знание системы (все ребята ранее уже работали с этой платформой).
Во-вторых, нас всего 4 человека, а это значит, что большинство вопросов можно решить на уровне чата. В крайнем случае — созвониться в Teams и обсудить всё голосом. Просто и эффективно.
Работа шла хорошо. Старт получился довольно резкий и многообещающий: мы участвовали в глобальных планированиях, бесперебойно поставляли новые фичи, предлагали свои идеи по оптимизации приложения, трудились над улучшением продукта.
Результат не заставил себя долго ждать — Заказчик оценил наши труды и инициировал расширение. Происходило оно поэтапно, но в конечном счете мы пришли к 5 командам (10 тестировщиков) + стажёры + команды со стороны Заказчика, с которыми также идёт активное взаимодействие.
Мы гордились за себя и свой проект, но, к сожалению, не долго. Мало того, что начал затягиваться регресс, так ещё и после нас находились баги на предрелизном окружении. Ситуация крайне неприятная.
Уже этого было достаточно, чтобы забить тревогу и понять, что нужно срочно что-то менять.
Собравшись со Scrum Master’ами, Delivery Manager’ом и Quality Control командой Заказчика мы начали искать источник проблемы: что же мы упустили?
Проблемы:
-
После расширения заметно сократилось межкомандное общение среди тестировщиков. Большая часть взаимодействия была на уровне команды и не выходила за её пределы. Т.е. все «варятся в собственном соку».
-
При планировании упускаются важные, но не очевидные сразу моменты (напомню, у нас только что случилось расширение, и пришло много новых ребят). Это выясняется под конец разработки, быстро делаются фиксы, быстро что-то тестируется — всё в режиме паники.
-
Больше команд — больше фич в релиз. Поскольку у нас довольно большой и сложный проект, над одной и той же областью могут работать сразу несколько команд. А это крайне плодотворная почва для багов.
Выводы:
Нам просто не хватает информации. Тестировщики слабо представляют, что происходит с тестированием в других командах. Получилась ситуация, при которой все вроде бы делают одно и тоже, но настолько по-разному, что получается сплошная путаница.
Решение:
Для себя мы поняли, что нужно унифицировать процесс тестирования. Сконцентрировались мы на end-to-end тестировании. Оно у нас было, но каждая команда проводила его по-своему, а результаты нигде не фиксировались. При таком положении дел прозрачности просто нет: совершенно непонятно, что команда посмотрела, а что осталось за рамками ее внимания.
Унифицировать мы решили посредством общедоступного документа, который поможет не только зафиксировать E2E-сценарии, но и будет содержать в себе полезную информацию, которая поможет подойти к тестированию фичи структурированно и системно.
Мы приняли решение создавать такой документ к каждой из фич.То есть ещё на этапе планирования мы начали создавать ещё одну user story — E2E (в дополнение к уже описанным user story, относящимся к этой фиче). В ней по ходу разработки создаётся некий end-to-end тест-план по заданному шаблону.
Далее приведу немного обезличенный пример того, как это может выглядеть. За основу я взяла наш end-to-end тест-план, но опустила некоторые специфичные детали.
Пример структуры:
-
Полезные ссылки, которые могут пригодиться по ходу создания E2E-плана. Что можно добавить:
-
Wiki с инструкцией о том, как взаимодействовать с тест-планом (у нас она была написана параллельно с разработкой самого E2E).
-
Wiki с рекомендациями по продукту (product considerations) — справочник о том, какие есть ключевые области приложения, какие требования предъявляются к системе (разрешение экрана, браузеры, языки и т.д).
-
Wiki об обратной совместимости (backward compatibility) — если есть версионность.
-
-
Вопросы, на которые должен отвечать документ:
-
Какие сценарии должны быть протестированы, основываясь на функциональных требованиях к фиче?
-
Какие сценарии должны быть протестированы в рамках обратной совместимости?
-
Какие области продукта были затронуты при разработке фичи?
-
Какие из этих областей наиболее критичны и требуют особого внимания?
-
-
Нефункциональные требования (тут нужно выбрать то, что актуально, и описать, что именно будет тестироваться). Пример нашего списка:
-
Нагрузочное тестирование (Performance / Load testing).
-
Тестирование доступности (Accessibility testing).
-
Тестирование локализации (Localization testing).
-
Кроссбраузерное и кроссплатформенное тестирование (Cross browser and cross platform testing).
-
-
Автоматизированное тестирование (выделить нужное, описать сценарии):
-
Selenium.
-
API / Integration tests.
-
Unit tests.
-
-
Сценарии, которые не входят в данную фичу (out of scope).
-
Ссылки на все тест-кейсы по фиче.
Данный список можно и нужно адаптировать под особенности своего проекта, чтобы эффект от него был максимальный. Наш же список может послужить отправной точкой в ваших поисках
Важные примечания:
-
С таким тест-планом можно и нужно начинать работать ещё на этапе планирования фичи, чтобы задать все вопросы как можно раньше.
-
Как только будет готова первая версия, можно дополнительно визуализировать план — создать по нему mind-map. Глянуть на картинку быстрее и проще, чем читать полное описание. Наши Заказчики особенно оценили этот пункт.
-
Ревью тест-плана другой командой повысит прозрачность и поможет найти недочёты.
-
План следует дорабатывать по ходу разработки фичи.
Увидеть первые результаты после внедрения мы смогли уже в рамках ближайшего регресса. К нему мы подошли более подготовленными, что не могло не сказаться положительно на качестве нашего тестирования.
Что нам дали изменения:
-
К финалу разработки каждой фичи есть документ, в котором зафиксированы все особенности тестирования.
-
План — это user story, а значит он общедоступен для всех членов команд разработки: Заказчиков, Product Owner’ов и т.д.
-
Благодаря ревью планов, увеличилось взаимодействие между тестировщиками из разных команд; к тому же появилась возможность расшаривать экспертизу по областям.
-
План стал хорошим помощником в планировании задач, количество «неожиданно всплывших нюансов» заметно уменьшилось.
-
Т.к. черновик плана есть уже на этапе планирования, можно показать его Product Owner’у и уточнить, верно ли мы понимаем задачу.
-
К плану всегда можно вернуться и освежить знания по фичам.
Не скажу, что получилось сразу хорошо. К финальной версии мы шли через несколько этапов обсуждений. Весь процесс создания, апробации и оттачивания занял у нас примерно 2-3 месяца.
P.S.:
Так как не все любят перемены, вот небольшой бонус — пара слов о том, как сделать процесс внедрения максимально комфортным (советы капитана Очевидность):
-
Создайте шаблон, если ваша система управления задачами это позволяет. Не все люди встречают перемены с радостью (особенно те перемены, которые влекут за собой дополнительную работу). Но если попробовать облегчить процесс использования нововведений, сопротивления будет меньше.
-
Обсуждайте с командой. Плохая практика — создать что-то «в одного» и кинуть этим в коллег: «Нате, работайте». Обсуждения стоит начать сразу же, как только у вас будет первая версия документа. Чем больше вы вовлекаете людей, тем меньше будет «Фу, опять нам навязывают какую-то бюрократию», и тем больше будет чувства причастности и ответственности за совместные решения.
-
Совершенствуйтесь. Опыт показывает, что с первого раза идеально не бывает. Да и со второго, да и с третьего… Дополнительные встречи-обсуждения после реального использования плана помогут понять, с чем работать хорошо, с чем не очень, что можно улучшить. Проведите несколько таких сессий, чтобы довести ваш документ до его лучшего воплощения. Оно того стоит.
-
При необходимости, создайте wiki. Ссылку на wiki можно поместить прямо в шаблон. Первые месяцы после внедрения это будет очень полезно. Вы получите единый справочник с актуальной информацией, которая будет полезна как настоящим, так и будущим участникам проекта.
-
Ревью. Перед внедрением покажите финальную версию документа тем, кто не принимал участие в его разработке, но всё же будет с ним сталкиваться в работе (например, разработчикам). Свежий взгляд может натолкнуть на новые полезные идеи. Главное — найти инициативного разработчика

Заключение
Обсуждения, безусловно, требуют время. Так же как и создание end-to-end тест-плана для каждой фичи, когда он уже введён в эксплуатацию. Но эффект, который мы наблюдаем от внедрения этого документа, с лихвой покрывает все эти усилия. Мы получили прозрачность в тестировании и стандартизацию процесса.
К тому же наша идея понравилась и используется теперь и другими командами Заказчика. Мы все идём по одному пути, вместе ищем узкие места и улучшаем их, стараемся сделать процесс общим, удобным для каждого из его участников.
На этом у меня всё, спасибо за внимание
Оригинальная публикация
У вас наверняка было такое, когда вы и ваши друзья очень хотели посмотреть какой-нибудь фильм, а после жалели о том, что потратили на него время. Или, может быть, вы помните тот момент, когда ваша команда думала, что нашла «киллер фичу» и обнаруживала ее «подводные камни» только после выпуска продукта.
Хорошие идеи часто терпят неудачу на практике, и в мире тестирования хорошим примером этого может служить стратегия тестирования, построенная на автоматизации end-to-end тестов.
Тестировщики могут инвестировать свое время на написание многих типов автоматических тестов, включая модульные тесты, интеграционные тесты и end-2-end тесты, но эта стратегия в основном направлена на end-2-end тесты, которые проверяют продукт или услугу в целом. Как правило, эти тесты имитируют реальные пользовательские сценарии.

Источник
Хотя полагаться в первую очередь на end-2-end тесты — плохая идея, но теоретически можно придумать несколько доводов в пользу этого утверждения.
Итак, номер один в списке Google из десяти вещей, которые, как мы знаем, являются правдой: «Интересы пользователей превыше всего». Таким образом, использование end-2-end тестов, которые фокусируются на реальных пользовательских сценариях, выглядит отличной идеей. Кроме того, эта стратегия в целом привлекательна для многих участников процесса.
- Разработчикам эта стратегия нравится, потому что можно перенести бОльшую часть тестирования, если вообще не всю, на других.
- Руководителям и лицам, принимающим решения, она нравится, потому что тесты, имитирующие реальные пользовательские сценарии, могут помочь им легко определить, как неудачный тест повлияет на пользователя.
- Тестировщикам такая стратегия нравится, потому что они беспокоятся как бы не пропустить ошибки влияющие на пользователей и как бы не не написать тест, который не проверяет реальное поведение; написание тестов отталкиваясь от сценариев работы пользователя часто позволяет избежать обеих проблем и дает тестировщику чувство выполненного долга.
End-2-end тесты на практике
Итак, если эта стратегия тестирования выглядит так хорошо в теории, то что же с ней не так на практике? Чтобы продемонстрировать это, я ниже приведу выдуманный сценарий, но который основан на реальных ситуациях, знакомых как мне, так и другим тестировщикам.
Допустим команда создает сервис для редактирования документов в режиме онлайн (например, Google Docs). Давайте предположим, что у команды уже есть какая-то фантастическая инфраструктура для тестирования. Каждую ночь:
- выполняется сборка последней версии сервиса,
- затем эта версия развертывается в среде тестирования команды,
- затем в этой среде тестирования прогоняются все сквозные тесты,
- команда получает по электронной почте отчет с кратким изложением результатов тестирования.
Крайний срок приближается быстро. Чтобы поддерживать высокую планку качества продукции, допустим, мы решаем, что требуется по крайней мере 90% успешных end-2-end тестов, чтобы мы считали что версия готова. Допустим, крайний срок наступает через один день.
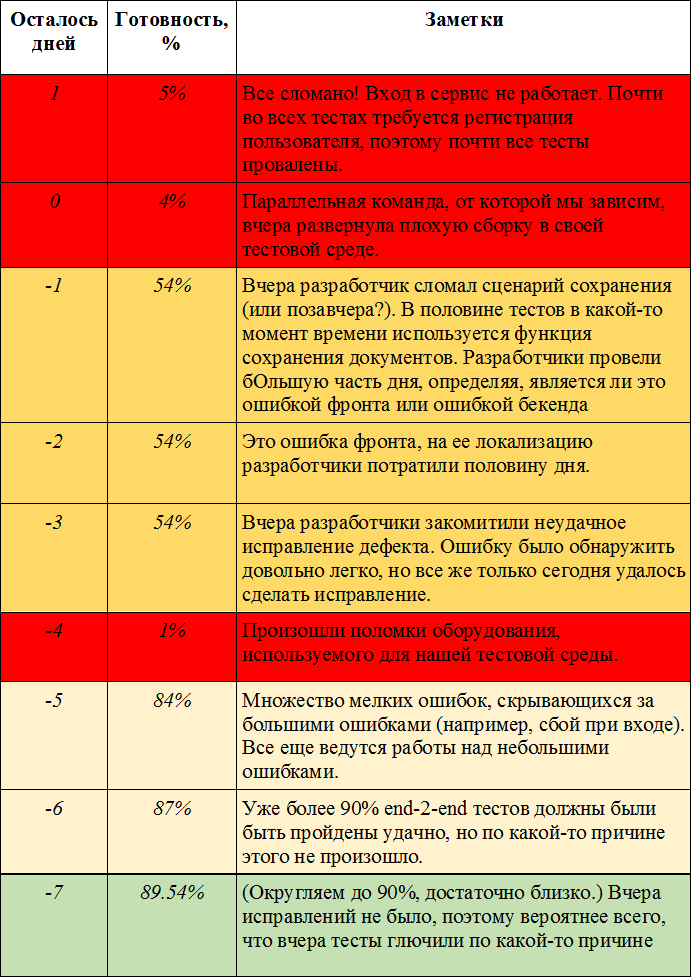
Несмотря на многочисленные проблемы, тесты в конечном итоге выявили реальные ошибки.
Что прошло хорошо
Ошибки, влияющие на пользователя, были выявлены и исправлены до того, как они к нему попали.
Что пошло не так
- Команда завершила свой этап программирования на неделю позже (и много работала сверхурочно).
- Поиск основной причины неудачного end-2-end теста является трудоемким и может занять много времени.
- Неудачи параллельной команды и сбои в оборудовании сдвинули результаты тестов на несколько дней.
- Многие мелкие ошибки были спрятаны за большими ошибками.
- Результаты end-2-end тестов временами были ненадежными.
- Разработчикам пришлось подождать до следующего дня, чтобы узнать, сработало ли исправление или нет.
Итак, теперь, когда мы знаем, что пошло не так в end-2-end стратегии, нам нужно изменить наш подход к тестированию, чтобы избежать многих из вышеперечисленных проблем. Но каков правильный подход?
Истинная ценность тестов
Как правило, работа тестировщика заканчивается, когда тест провален. Ошибка регистрируется, и затем задача разработчика — исправить ошибку. Однако чтобы определить, где end-2-end стратегия не срабатывает, нам нужно выйти за рамки этого мышления и подойти к проблеме используя наши базовые принципы. Если мы «сосредоточимся на пользователе (а все остальное приложится)», мы должны спросить себя: приносит ли проваленный тест пользу пользователю?
Вот ответ: «Проваленный тест напрямую не приносит пользы пользователю».
Хотя это утверждение, на первый взгляд, кажется шокирующим, оно верно. Если продукт работает, он работает, независимо от того, говорит ли тест, что он работает или нет. Если продукт сломан, он сломан, независимо от того, говорит ли тест, что он сломан или нет. Итак, если проваленные тесты не приносят пользы пользователю, то что же приносит ему пользу?
Исправление ошибок напрямую приносит пользу пользователю.
Пользователь будет счастлив только тогда, когда это непредсказуемое поведение (ошибка) исчезнет. Очевидно, чтобы исправить ошибку, вы должны знать, что она существует. Чтобы узнать, что ошибка существует, в идеале у вас должен быть тест, который ее обнаруживает (потому что если тест не выявит ошибку, то ее найдет пользователь). Но во всем этом процессе, от провала теста до исправления ошибки, добавленная стоимость появляется на самом последнем шаге.

Таким образом, чтобы оценить любую стратегию тестирования, вы не можете просто оценить, как она находит ошибки. Вы также должны оценить, как это позволяет разработчикам исправлять (и даже предотвращать) их.
Построение правильной обратной связи
Тесты создают цикл обратной связи, который информирует разработчика о том, работает продукт или нет. Идеальный цикл обратной связи имеет несколько свойств.
- Он должен быть быстрым. Ни один разработчик не хочет ждать часами или днями, чтобы узнать, работает ли его изменение. Иногда изменение не работает (никто не совершенен), и цикл обратной связи должен выполняться несколько раз. Более быстрый цикл обратной связи приводит к более быстрым исправлениям. Если цикл достаточно быстр, разработчики могут даже запустить тесты перед проверкой изменений.
- Он должен быть надежным. Ни один разработчик не хочет тратить часы на отладку теста, только для того, чтобы выяснить, что сам тест был ошибочным. Ненадежные тесты снижают доверие разработчика к ним, и в результате такие тесты часто игнорируются, даже когда они обнаруживают реальные проблемы с продуктом.
- Он должен позволять быстро находить ошибки. Чтобы исправить ошибку, разработчикам необходимо найти конкретное строки кода, вызывающие ошибку. Когда продукт содержит миллионы строк кодов, а ошибка может быть где угодно, это все равно что пытаться найти иголку в стоге сена.
Думайте о малом, а не о большем
Так как же нам создать этот идеальный цикл обратной связи? Думая о малом, а не о большем.
Модульное тестирование
Модульные тесты берут небольшой фрагмент продукта и тестируют его изолированно от всего остального. Они почти создают тот самый идеальный цикл обратной связи:
- Модульные тесты быстрые. Нам нужно написать небольшой блок кода и мы уже можем тестировать его. Модульные тесты, как правило, довольно маленькие. На самом деле, одна десятая секунды — слишком долго для модульных тестов.
- Модульные тесты надежны. Простые системы и небольшие модули кода, как правило, гораздо более устойчивые. Кроме того, лучшие практики модульного тестирования — в частности, практики, связанные с герметичными тестами — полностью устраняют такие проблемы.
- Модульные тесты позволяют быстро найти ошибки. Даже если продукт содержит миллионы строк кода, если модульный тест не пройден, то вы, скорее всего, взглянув на тестируемый модуль сразу поймете в чем ошибка.
Написание эффективных модульных тестов требует навыков в таких областях, как управление зависимостями, написание заглушек/ mock-ов и герметичное тестирование. Я не буду описывать эти навыки здесь, но для начала типичный пример, предлагаемый новому Googler -у (или как их называют в Google — Noogler-у), — это то, как Google создает и тестирует секундомер.
Модульные тесты против end-2-end тестов
При end-2-end тестах вам нужно подождать: сначала создания всего продукта, затем его развертывания и, наконец, выполнения всех end-2-end тестов. Когда тесты все же заработали, вероятнее всего, они периодически будут сбоить. И даже если тест обнаружит ошибку, она может быть в любом месте продукта.
Хотя сквозные тесты лучше справляются с моделированием реальных пользовательских сценариев, это преимущество быстро перевешивается всеми недостатками сквозного цикла обратной связи:
![]()
Интеграционные тесты
У модульных тестов есть один существенный недостаток: даже если модули работают хорошо по отдельности, вы не знаете, хорошо ли они работают вместе. Но даже тогда вам не обязательно проводить end-2-end тесты. Для этого вы можете использовать интеграционный тест. Интеграционный тест берет небольшую группу модулей, часто два, и тестирует их поведение как единого целого.
Если два блока не интегрируются должным образом, зачем писать сквозной тест, когда вы можете написать гораздо меньший, более сфокусированный интеграционный тест, который обнаруживает ту же ошибку? Конечно, вы должны понимать весь контекст при тестировании, но для того, чтобы проверить работу двух модулей вместе вам всего лишь нужно совсем чуть-чуть расширить перспективу.
Пирамида тестов
Даже при проведении и модульных, и интеграционных тестов вам, скорее всего, потребуется небольшое количество end-2-end тестов для проверки системы в целом. Чтобы найти правильный баланс между всеми тремя типами тестов, лучше всего использовать визуальную пирамиду тестирования. Вот упрощенная версия пирамиды тестирования из вступительной речи конференции Google Test Automation 2014 года.
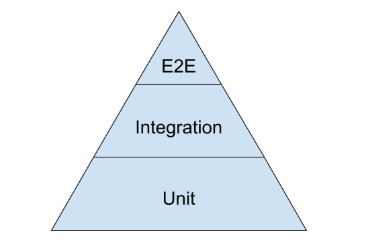
Основная часть ваших тестов — это модульные тесты в нижней части пирамиды. По мере того как вы продвигаетесь вверх по пирамиде, ваши тесты становятся более всеобъемлющими, но в то же время количество тестов (ширина вашей пирамиды) уменьшается.
По-хорошему, Google предлагает разделение 70/20/10: 70% модульных тестов, 20% интеграционных тестов и 10% end-2-end тестов. Точное соотношение будет отличаться для каждой команды, но в целом она должна сохранять форму пирамиды. Старайтесь избегать следующих «форм»:
- Перевернутая пирамида / рожок мороженого. Команда опирается в основном на сквозные тесты, используя несколько интеграционных тестов и совсем немного модульных тестов.
- Песочные часы. Команда начинает с большого количества модульных тестов, а затем использует сквозные тесты там, где должны использоваться интеграционные тесты. Песочные часы имеют много модульных тестов в нижней части и много сквозных тестов в верхней части, но мало интеграционных тестов в середине.
Точно так же, как обычная пирамида имеет тенденцию быть самой стабильной структурой в реальной жизни, пирамида тестирования также имеет тенденцию быть самой стабильной стратегией тестирования.
Вакансии
Если вы любите и умеете писать модульные тесты, то вам к нам! В компании ЛАНИТ открыта вакансия разработчика Java в DevOps команду, где вы найдете себе единомышленников.
Обсудить в форуме

Any serious application should be accompanied by a few test suites to validate its stability and performance.
There are many types of tests, each with their own purpose that cover specific aspects of the application. And so when you’re testing your app, you should make sure that you have a good balance of various tests.

But one type of test is often favored by developers over all others, and therefore tends to be overused. This type of testing is end-to-end testing (E2E).
For those who are still exploring the world of Software Testing, E2E testing is when you validate your entire application from start to finish, along with any of its dependencies.
In E2E testing, you create an environment identical to the one that will be used by real users. Then you test all actions that your users might perform on your application.
With End-To-End testing, you test entire flows – like logging onto a website or buying a product from an online store.

But if you overuse E2E testing, you’re Inverting the Testing Pyramid. I was in a situation like this. In one of my projects, I was planning to cover most cases with E2E tests – or even worse, use only the E2E test. Fortunately, I changed my mind. So now I want to share with you what I learned.
Why You Should Respect the Test Pyramid
Chaotically written tests look and feel normal at first, but they will always be painful in the end.
We write tests to gain more time, and we do that with test automation. Of course, we could open our applications ourselves and test them manually. If we only had to do this once, then there would be no problem. But that’s rarely the case.
Software is always getting updated. So you need to perform continuous testing to stay on top of things. You can’t run all the tests manually each time the application gets updated. If you can write a test suite once and then run it every time you want to test an aspect of your application, you’ll save a lot of time.
Each test has its own purpose. If you go beyond the boundaries of each type of test, your tests will start to harm rather than help you. This is because you will end up spending more time writing tests and maintaining them than developing the application itself. In other words, you’ll lose one of the biggest benefits of automated testing.
A good starting point is to follow the Testing Pyramid. It helps you figure out the right balance of tests. It represents an industry-standard guideline, and it has endured since the mid-2000s because it continues to be practical.
So does that mean developers always follow its guidelines? Not really. A few times the pyramid will look like an inverted one, where most of the tests are E2E. Or it will look like an hourglass, where there are a lot of unit tests and E2E tests, but not many integration tests.

The Three Layers of the Testing Pyramid
A testing pyramid typically has three layers: Unit Tests, Integration Tests, and End-to-End Tests. Let’s learn more about them now.
1. Unit Tests
Unit Tests focus on the smallest unit of code, like functions or classes.
They are short and don’t have any external dependencies. If they have an external dependency, you use mocks instead.
If a unit test fails, finding the issue is typically a simple process. They also have a reduced testing scope which makes them simple to write, fast to run, and easy to maintain.
2. Integration Tests
Integration Tests focus on the interaction between two distinct entities. They are typically slower to run because more things need to be set up.
If integration tests fail, finding the issue is a bit more challenging because the failure range is bigger.
They are also harder to write and maintain, mostly because they need more advanced mocking and increased testing scope.
3. End-To-End tests
Lastly, E2E tests focus on flows, from the simplest up to the most complex. They can be viewed as a multi-step integration test.
These tests are the slowest to run because they involve building, deploying, firing up a browser, and performing actions around the application.
If E2E tests fail, finding the issue is often difficult because now the failure range is expanded to the entire application. Basically, along the path, anything could have broken.
They are by far the hardest type of tests to write and maintain (from the three types considered here) because of the huge test scope and because they involve the entire application.
Hopefully you can now see why the testing pyramid has been designed in this way. From the bottom to the top, each layer of testing represents a decrease in speed and an increase in scope, complexity and maintenance.
That’s why one important thing to remember is that E2E testing cannot replace other methods – it is meant to extend them. The purpose of E2E testing is well-defined, and the tests should not extend beyond that boundary.
Ideally, tests should catch bugs as close to the root of the pyramid as possible. E2E is here to validate buttons, forms, changes, links, external processes, and generally and entire workflow’s function without problems.
Testing with Code vs Codeless Testing
In general, there are two types of testing: manual testing and automated testing. This means that we do the testing either by hand or by using scripts.
The second method is the most commonly used. But automated testing can be further separated into two parts: testing with code and codeless testing.
Testing with Code
When you’re testing with code, you use frameworks that can automate browsers. One of the most popular tools is Selenium, but I prefer and often use Cypress in my projects (only for JavaScript). Still, they mostly work in the same way.
Basically, with tools like this, you mock up web browsers and instruct them to perform different actions on your target application. After that, you test to see if your application has responded to the corresponding actions.
This is a simple mock example taken from the Cypress documentation to help you better understand how this tool works:

Let’s look at what’s going on:
- Given a user visits https://example.cypress.io
- When they click the link labeled type, then the URL should include /commands/actions
- If they type “fake@email.com“ into the .action-email input then the .action-email input has “fake@email.com“ as its value
Codeless Testing
In a codeless testing situation, you use frameworks powered by Artificial Intelligence that record your actions. Based on some additional information, they test if the target application responds as expected.
These tools often look like low code platforms, where you drag and drop different panels. One of these tools is TestCraft which is a codeless solution built upon Selenium.

Because of the features they offer (like creating, maintaining, and running tests with simple drag-and-drop options and no coding knowledge), this kind of tool usually comes at a higher price. But I wanted to mention TestCraft because they have a free plan which basically includes everything.
Now, of course, a codeless solution can be an advantage if you want speed and money, but these solutions are still new. Therefore, they can’t yet reach the complexity of test suites that you can develop by writing the code yourself.
If the target application has some very complex flows that include multiple moving parts, then a classic testing situation is the way to go. But if you have simple flows, then a codeless solution is what you need.
Wrapping up
Writing tests is a must for any application. If you follow solid principles and write your test suites according to their type, then your tests will only improve your application and will also be fairly easy to write and maintain.
You should only use end-to-end tests, like any other test, in the ways their meant to be used. They’re created to test the application’s workflow from beginning to end by replicating real user scenarios. But in the end, remember that most bugs should be caught as close to the root as possible.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Any serious application should be accompanied by a few test suites to validate its stability and performance.
There are many types of tests, each with their own purpose that cover specific aspects of the application. And so when you’re testing your app, you should make sure that you have a good balance of various tests.
But one type of test is often favored by developers over all others, and therefore tends to be overused. This type of testing is end-to-end testing (E2E).
For those who are still exploring the world of Software Testing, E2E testing is when you validate your entire application from start to finish, along with any of its dependencies.
In E2E testing, you create an environment identical to the one that will be used by real users. Then you test all actions that your users might perform on your application.
With End-To-End testing, you test entire flows – like logging onto a website or buying a product from an online store.
But if you overuse E2E testing, you’re Inverting the Testing Pyramid. I was in a situation like this. In one of my projects, I was planning to cover most cases with E2E tests – or even worse, use only the E2E test. Fortunately, I changed my mind. So now I want to share with you what I learned.
Why You Should Respect the Test Pyramid
Chaotically written tests look and feel normal at first, but they will always be painful in the end.
We write tests to gain more time, and we do that with test automation. Of course, we could open our applications ourselves and test them manually. If we only had to do this once, then there would be no problem. But that’s rarely the case.
Software is always getting updated. So you need to perform continuous testing to stay on top of things. You can’t run all the tests manually each time the application gets updated. If you can write a test suite once and then run it every time you want to test an aspect of your application, you’ll save a lot of time.
Each test has its own purpose. If you go beyond the boundaries of each type of test, your tests will start to harm rather than help you. This is because you will end up spending more time writing tests and maintaining them than developing the application itself. In other words, you’ll lose one of the biggest benefits of automated testing.
A good starting point is to follow the Testing Pyramid. It helps you figure out the right balance of tests. It represents an industry-standard guideline, and it has endured since the mid-2000s because it continues to be practical.
So does that mean developers always follow its guidelines? Not really. A few times the pyramid will look like an inverted one, where most of the tests are E2E. Or it will look like an hourglass, where there are a lot of unit tests and E2E tests, but not many integration tests.
The Three Layers of the Testing Pyramid
A testing pyramid typically has three layers: Unit Tests, Integration Tests, and End-to-End Tests. Let’s learn more about them now.
1. Unit Tests
Unit Tests focus on the smallest unit of code, like functions or classes.
They are short and don’t have any external dependencies. If they have an external dependency, you use mocks instead.
If a unit test fails, finding the issue is typically a simple process. They also have a reduced testing scope which makes them simple to write, fast to run, and easy to maintain.
2. Integration Tests
Integration Tests focus on the interaction between two distinct entities. They are typically slower to run because more things need to be set up.
If integration tests fail, finding the issue is a bit more challenging because the failure range is bigger.
They are also harder to write and maintain, mostly because they need more advanced mocking and increased testing scope.
3. End-To-End tests
Lastly, E2E tests focus on flows, from the simplest up to the most complex. They can be viewed as a multi-step integration test.
These tests are the slowest to run because they involve building, deploying, firing up a browser, and performing actions around the application.
If E2E tests fail, finding the issue is often difficult because now the failure range is expanded to the entire application. Basically, along the path, anything could have broken.
They are by far the hardest type of tests to write and maintain (from the three types considered here) because of the huge test scope and because they involve the entire application.
Hopefully you can now see why the testing pyramid has been designed in this way. From the bottom to the top, each layer of testing represents a decrease in speed and an increase in scope, complexity and maintenance.
That’s why one important thing to remember is that E2E testing cannot replace other methods – it is meant to extend them. The purpose of E2E testing is well-defined, and the tests should not extend beyond that boundary.
Ideally, tests should catch bugs as close to the root of the pyramid as possible. E2E is here to validate buttons, forms, changes, links, external processes, and generally and entire workflow’s function without problems.
Testing with Code vs Codeless Testing
In general, there are two types of testing: manual testing and automated testing. This means that we do the testing either by hand or by using scripts.
The second method is the most commonly used. But automated testing can be further separated into two parts: testing with code and codeless testing.
Testing with Code
When you’re testing with code, you use frameworks that can automate browsers. One of the most popular tools is Selenium, but I prefer and often use Cypress in my projects (only for JavaScript). Still, they mostly work in the same way.
Basically, with tools like this, you mock up web browsers and instruct them to perform different actions on your target application. After that, you test to see if your application has responded to the corresponding actions.
This is a simple mock example taken from the Cypress documentation to help you better understand how this tool works:
Let’s look at what’s going on:
- Given a user visits https://example.cypress.io
- When they click the link labeled type, then the URL should include /commands/actions
- If they type “fake@email.com“ into the .action-email input then the .action-email input has “fake@email.com“ as its value
Codeless Testing
In a codeless testing situation, you use frameworks powered by Artificial Intelligence that record your actions. Based on some additional information, they test if the target application responds as expected.
These tools often look like low code platforms, where you drag and drop different panels. One of these tools is TestCraft which is a codeless solution built upon Selenium.
Because of the features they offer (like creating, maintaining, and running tests with simple drag-and-drop options and no coding knowledge), this kind of tool usually comes at a higher price. But I wanted to mention TestCraft because they have a free plan which basically includes everything.
Now, of course, a codeless solution can be an advantage if you want speed and money, but these solutions are still new. Therefore, they can’t yet reach the complexity of test suites that you can develop by writing the code yourself.
If the target application has some very complex flows that include multiple moving parts, then a classic testing situation is the way to go. But if you have simple flows, then a codeless solution is what you need.
Wrapping up
Writing tests is a must for any application. If you follow solid principles and write your test suites according to their type, then your tests will only improve your application and will also be fairly easy to write and maintain.
You should only use end-to-end tests, like any other test, in the ways their meant to be used. They’re created to test the application’s workflow from beginning to end by replicating real user scenarios. But in the end, remember that most bugs should be caught as close to the root as possible.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started

Сквозное тестирование
Сквозное тестирование (End-to-end, E2E, Chain testing) — это вид тестирования, используемый для проверки программного обеспечения от начала до конца, а также его интеграцию с внешними интерфейсами. Цель сквозного тестирования состоит в проверке всего программного обеспечения на предмет зависимостей, целостности данных и связи с другими системами, интерфейсами и базами данных для проверки успешного выполнения полного производственного сценария.
Наряду с программной системой тестирование также обеспечивает проверку пакетной обработки и обработки данных из других вышестоящих и нижестоящих систем. Отсюда и название «End-to-End». Сквозное тестирование обычно проводится после функционального и системного тестирования. Для его проведения используются реальные данные и тестовая среда для имитации рабочего режима.

Зачем нужно сквозное тестирование?
Сквозное тестирование проверяет весь системный флоу и повышает уверенность за счет своевременного обнаружения проблем и увеличения покрытия тестами подсистем. Современные системы ПО сложны и взаимосвязаны с большим количеством подсистем, которые могут существенно отличаться от существующих систем. Вся система может разрушиться из-за отказа любой подсистемы, что представляет собой серьезный риск. Этого риска мы как раз и стремимся избежать с помощью сквозного тестирования.
Процесс сквозного тестирования:
На схеме ниже представлен обзор процесса сквозного тестирования.

Основные виды деятельности, связанные со сквозным тестированием:
-
Изучение требований к сквозному тестированию;
-
Настройка тестовой среды и требования к оборудованию/программному обеспечению;
-
Описание всех процессов системы и ее подсистем;
-
Описание ролей и ответственности для всех систем;
-
Методология и стандарты тестирования;
-
Сквозное отслеживание требований и разработка тест-кейсов;
-
Входные и выходные данные для каждой системы.
Как писать тест-кейсы для сквозного тестирования?

Фреймворк сквозного тестирования включает в себя три части:
-
Создание пользовательских функций
-
Создание условий
-
Создание тест-кейсов
Рассмотрим каждую из них подробно.
Создание пользовательских функций
Как часть построения пользовательских функций, должны быть выполнены следующие действия:
-
Перечислить функции системы и их взаимосвязанные компоненты;
-
Перечислить входные данные, действия и выходные данные для каждой характеристики или функции;
-
Определить отношения между функциями;
-
Определить, является ли функция многократно используемой или независимой.
Например, рассмотрите сценарий, при котором вы входите в свой банковский аккаунт и переводите деньги со своего счета на счет в другой банк (сторонняя подсистема):
-
Войти в банковскую систему.
-
Проверить сумму остатка на счете.
-
Перевести определенную сумму со своего счета на другой банковский счет (сторонняя подсистема).
-
Проверить текущий баланс счета.
-
Выйти из приложения.
Построение условий на основе пользовательских функций
В рамках построения условий выполняются следующие действия:
-
Построение набора условий для каждой определенной пользовательской функции;
-
Условия включают последовательность, время и условия данных.
Например, проверка дополнительных условий, таких как:
Страница авторизации
-
Неверное имя пользователя и пароль
-
Проверка с действительным именем пользователя и паролем
-
Проверка надежности пароля
-
Проверка сообщений об ошибках
Сумма остатка
-
Проверьте текущий баланс через 24 часа (Если перевод отправляется в другой банк)
-
Проверьте сообщение об ошибке, если сумма перевода больше суммы текущего баланса.
Создайте тестовый сценарий
Построение тестового сценария для определенной пользовательской функции
В нашем случае,
-
Войти в систему
-
Проверить сумму остатка на банковском счете
-
Перевести сумму остатка на банковском счете
Создание нескольких тест-кейсов
Создайте один или несколько тест-кейсов для каждого определенного сценария. Тест-кейсы могут включать каждое условие как отдельный тестовый пример.
Инструмент сквозного тестирования
testRigor
В мире сквозного тестирования лидером отрасли является testRigor. Он помогает создавать тесты без кода для веб-интерфейса, нативных и гибридных мобильных приложений, мобильных браузеров и API. С его помощью можно тестировать электронную почту и SMS, загруженные файлы .XLS, .DOC, .PDF и т. д.
Функции:
-
Написание тестов без кода просто на английском языке.
-
Покрытие Web + Mobile + API в одном тесте. Кроссплатформенная и кроссбраузерная поддержка.
-
Создание тестов в 15 раз быстрее по сравнению с Selenium.
-
Сокращение обслуживания тестов до 99,5%.
-
testRigor безопасен и соответствует стандарту SOC 2 Type 2.
-
Интеграция с CI/CD и управлением тест-кейсами.
-
Выполнение 1000 тестов и получение результатов менее чем за 30 минут.
Метрики сквозного тестирования:
Ниже приведены некоторые метрики, используемые для оценки прогресса сквозного тестирования.
-
Статус подготовки тест-кейса: показывает реальный прогресс подготовки тест-кейса по сравнению с запланированным.
-
Еженедельный прогресс тестирования. Дает подробную информацию о завершении теста за неделю в процентах. Неудачные, не выполненные и выполненные тесты по сравнению с запланированными для выполнения тестами.
-
Статус и детали дефектов — показывает процент открытых и закрытых дефектов понедельно. Кроме того, распределение дефектов по неделям в зависимости от серьезности и приоритета.
-
Доступность среды — общее количество часов доступности / общее количество часов, запланированных в день для тестирования.
Сквозное тестирование vs системное тестирование
|
Сквозное тестирование |
Системное тестирование |
|
Проверяет программную систему, а также взаимосвязанные подсистемы. |
Проверяет только программную систему в соответствии со спецификациями требований. |
|
Проверяет весь сквозной поток процессов. |
Проверяет функциональные возможности и функции системы. |
|
Для тестирования рассматриваются все интерфейсы и серверные системы. |
Рассматриваются функциональное и нефункциональное тестирование |
|
Выполняется после завершения тестирования системы. |
Выполняется после интеграционного тестирования. |
|
Сквозное тестирование включает в себя проверку внешних интерфейсов, которую сложно автоматизировать. Следовательно, ручное тестирование предпочтительнее. |
Для тестирования системы можно выполнять как ручное, так и автоматизированное тестирование. |
В заключение
Сквозное тестирование — это процесс проверки программной системы вместе с ее подсистемами. Самая большая трудность при этом типе тестирования состоит в том, что необходимо располагать достаточным количеством информации о всей системе, а также о взаимосвязанных подсистемах.
Приглашаем всех желающих на открытое занятие, на котором мы познакомимся с фреймворком Selenide и перепишем существующие тесты на него. Регистрация доступна по ссылке.
Не так давно у нас случилась полная неразбериха с тестированием. Быстрый рост проекта, новые команды, новые люди. Неожиданно, всё это негативно повлияло на качество продукта.
В данной статье поделюсь опытом и расскажу, как мы осознали проблему, искали пути её решения и что в итоге нам помогло. История борьбы за качество
Для начала, определимся с тем, что такое end-to-end тестирование.
End-to-end (E2E) — это верхушка пирамиды тестирования. Можно сказать, что это конечный этап тестирования. Проводя E2E, мы смотрим, как выглядит функциональность для её конечных пользователей. Всё ли работает так, как планировалось? Все ли потребности пользователя удовлетворяются?
При таком тестировании на первый план выходит именно то, что будет видеть пользователь. Как работает система изнутри, на данном этапе уже не проверяется (т.к. это задачи других уровней пирамиды тестирования). Мы смотрим на картинку в целом.
Немного предыстории
Наш проект появился 2 года назад, когда один из Клиентов крупного Поставщика платформы для проведения электронных экзаменов и сертификаций захотел купить эту платформу и разрабатывать её своими силами.
Основными нашими задачами стало следующее:
-
Поддержание уже имеющегося функционала. Платформа крупная, существует более 20 лет. С её помощью можно пройти весь путь от создания контента для теста до оценки пройденного кандидатом экзамена. Составных частей очень много, и наша задача — следить за их работоспособностью и взаимодействием.
-
Оптимизация уже имеющегося функционала. Как бы ни было хорошо, всегда можно сделать лучше.
-
Разработка нового функционала. Главная причина, по которой появился наш проект. Вышеупомянутый Клиент видел свой вектор развития платформы, поэтому и было принято решение пойти своим путём.
Так мы и начали работать. На старте у нас было всего 2 команды, в каждой по 2 тестировщика. Взаимодействие выстраивалось крайне просто.
Во-первых, у всех есть знание системы (все ребята ранее уже работали с этой платформой).
Во-вторых, нас всего 4 человека, а это значит, что большинство вопросов можно решить на уровне чата. В крайнем случае — созвониться в Teams и обсудить всё голосом. Просто и эффективно.
Работа шла хорошо. Старт получился довольно резкий и многообещающий: мы участвовали в глобальных планированиях, бесперебойно поставляли новые фичи, предлагали свои идеи по оптимизации приложения, трудились над улучшением продукта.
Результат не заставил себя долго ждать — Заказчик оценил наши труды и инициировал расширение. Происходило оно поэтапно, но в конечном счете мы пришли к 5 командам (10 тестировщиков) + стажёры + команды со стороны Заказчика, с которыми также идёт активное взаимодействие.
Мы гордились за себя и свой проект, но, к сожалению, не долго. Мало того, что начал затягиваться регресс, так ещё и после нас находились баги на предрелизном окружении. Ситуация крайне неприятная.
Уже этого было достаточно, чтобы забить тревогу и понять, что нужно срочно что-то менять.
Собравшись со Scrum Master’ами, Delivery Manager’ом и Quality Control командой Заказчика мы начали искать источник проблемы: что же мы упустили?
Проблемы
-
После расширения заметно сократилось межкомандное общение среди тестировщиков. Большая часть взаимодействия была на уровне команды и не выходила за её пределы. Т.е. все «варятся в собственном соку».
-
При планировании упускаются важные, но не очевидные сразу моменты (напомню, у нас только что случилось расширение, и пришло много новых ребят). Это выясняется под конец разработки, быстро делаются фиксы, быстро что-то тестируется — всё в режиме паники.
-
Больше команд — больше фич в релиз. Поскольку у нас довольно большой и сложный проект, над одной и той же областью могут работать сразу несколько команд. А это крайне плодотворная почва для багов.
Выводы:
Нам просто не хватает информации. Тестировщики слабо представляют, что происходит с тестированием в других командах. Получилась ситуация, при которой все вроде бы делают одно и тоже, но настолько по-разному, что получается сплошная путаница.
Решение
Для себя мы поняли, что нужно унифицировать процесс тестирования. Сконцентрировались мы на end-to-end тестировании. Оно у нас было, но каждая команда проводила его по-своему, а результаты нигде не фиксировались. При таком положении дел прозрачности просто нет: совершенно непонятно, что команда посмотрела, а что осталось за рамками ее внимания.
Унифицировать мы решили посредством общедоступного документа, который поможет не только зафиксировать E2E-сценарии, но и будет содержать в себе полезную информацию, которая поможет подойти к тестированию фичи структурированно и системно.
Мы приняли решение создавать такой документ к каждой из фич.То есть ещё на этапе планирования мы начали создавать ещё одну user story — E2E (в дополнение к уже описанным user story, относящимся к этой фиче). В ней по ходу разработки создаётся некий end-to-end тест-план по заданному шаблону.
Далее приведу немного обезличенный пример того, как это может выглядеть. За основу я взяла наш end-to-end тест-план, но опустила некоторые специфичные детали.
Пример структуры:
-
Полезные ссылки, которые могут пригодиться по ходу создания E2E-плана. Что можно добавить:
-
Wiki с инструкцией о том, как взаимодействовать с тест-планом (у нас она была написана параллельно с разработкой самого E2E).
-
Wiki с рекомендации по продукту (product considerations) — справочник о том, какие есть ключевые области приложения, какие требования предъявляются к системе (разрешение экрана, браузеры, языки и т.д).
-
Wiki об обратной совместимости (backward compatibility) — если есть версионность.
-
-
Вопросы, на которые должен отвечать документ:
-
Какие сценарии должны быть протестированы, основываясь на функциональных требованиях к фиче?
-
Какие сценарии должны быть протестированы в рамках обратной совместимости?
-
Какие области продукта были затронуты при разработке фичи?
-
Какие из этих областей наиболее критичны и требуют особого внимания?
-
-
Нефункциональные требования (тут нужно выбрать то, что актуально, и описать, что именно будет тестироваться). Пример нашего списка:
-
Нагрузочное тестирование (Performance / Load testing).
-
Тестирование доступности (Accessibility testing).
-
Тестирование локализации (Localization testing).
-
Кроссбраузерное и кроссплатформенное тестирование (Cross browser and cross platform testing).
-
-
Автоматизированное тестирование (выделить нужное, описать сценарии):
-
Selenium.
-
API / Integration tests.
-
Unit tests.
-
-
Сценарии, которые не входят в данную фичу (out of scope).
-
Ссылки на все тест-кейсы по фиче.
Данный список можно и нужно адаптировать под особенности своего проекта, чтобы эффект от него был максимальный. Наш же список может послужить отправной точкой в ваших поисках
Важные примечания:
-
С таким тест-планом можно и нужно начинать работать ещё на этапе планирования фичи, чтобы задать все вопросы как можно раньше.
-
Как только будет готова первая версия, можно дополнительно визуализировать план — создать по нему mind-map. Глянуть на картинку быстрее и проще, чем читать полное описание. Наши Заказчики особенно оценили этот пункт.
-
Ревью тест-плана другой командой повысит прозрачность и поможет найти недочёты.
-
План следует дорабатывать по ходу разработки фичи.
Увидеть первые результаты после внедрения мы смогли уже в рамках ближайшего регресса. К нему мы подошли более подготовленными, что не могло не сказаться положительно на качестве нашего тестирования.
Что нам дали изменения
-
К финалу разработки каждой фичи есть документ, в котором зафиксированы все особенности тестирования.
-
План — это user story, а значит он общедоступен для всех членов команд разработки: Заказчиков, Product Owner’ов и т.д.
-
Благодаря ревью планов, увеличилось взаимодействие между тестировщиками из разных команд; к тому же появилась возможность расшаривать экспертизу по областям.
-
План стал хорошим помощником в планировании задач, количество «неожиданно всплывших нюансов» заметно уменьшилось.
-
Т.к. черновик плана есть уже на этапе планирования, можно показать его Product Owner’у и уточнить, верно ли мы понимаем задачу.
-
К плану всегда можно вернуться и освежить знания по фичам.
Не скажу, что получилось сразу хорошо. К финальной версии мы шли через несколько этапов обсуждений. Весь процесс создания, апробации и оттачивания занял у нас примерно 2-3 месяца.
P.S.:
Так как не все любят перемены, вот небольшой бонус — пара слов о том, как сделать процесс внедрения максимально комфортным (советы капитана Очевидность):
-
Создайте шаблон, если ваша система управления задачами это позволяет. Не все люди встречают перемены с радостью (особенно те перемены, которые влекут за собой дополнительную работу). Но если попробовать облегчить процесс использования нововведений, сопротивления будет меньше.
-
Обсуждайте с командой. Плохая практика — создать что-то «в одного» и кинуть этим в коллег: «Нате, работайте». Обсуждения стоит начать сразу же, как только у вас будет первая версия документа. Чем больше вы вовлекаете людей, тем меньше будет «Фу, опять нам навязывают какую-то бюрократию», и тем больше будет чувства причастности и ответственности за совместные решения.
-
Совершенствуйтесь. Опыт показывает, что с первого раза идеально не бывает. Да и со второго, да и с третьего… Дополнительные встречи-обсуждения после реального использования плана помогут понять, с чем работать хорошо, с чем не очень, что можно улучшить. Проведите несколько таких сессий, чтобы довести ваш документ до его лучшего воплощения. Оно того стоит.
-
При необходимости, создайте wiki. Ссылку на wiki можно поместить прямо в шаблон. Первые месяцы после внедрения это будет очень полезно. Вы получите единый справочник с актуальной информацией, которая будет полезна как настоящим, так и будущим участникам проекта.
-
Ревью. Перед внедрением покажите финальную версию документа тем, кто не принимал участие в его разработке, но всё же будет с ним сталкиваться в работе (например, разработчикам). Свежий взгляд может натолкнуть на новые полезные идеи. Главное — найти инициативного разработчика
Заключение
Обсуждения, безусловно, требуют время. Так же как и создание end-to-end тест-плана для каждой фичи, когда он уже введён в эксплуатацию. Но эффект, который мы наблюдаем от внедрения этого документа, с лихвой покрывает все эти усилия. Мы получили прозрачность в тестировании и стандартизацию процесса.
К тому же наша идея понравилась и используется теперь и другими командами Заказчика. Мы все идём по одному пути, вместе ищем узкие места и улучшаем их, стараемся сделать процесс общим, удобным для каждого из его участников.
На этом у меня всё, спасибо за внимание