Нагрузочное тестирование предназначено для проверки поведения веб-приложения в условиях реальной и пиковой нагрузки. Такое тестирование позволяет узнать пределы устойчивости приложения, а также найти проблемные места, и откорректировать элементы, которые являются причиной сбоев при большой нагрузке.
Обсудим, как написать план такого тестирования. Нужно рассмотреть следующие моменты.
- Какой результат ожидается от нагрузочного тестирования?
- Как мы будем тестировать это веб-приложение:
- В реалистичных условиях
- В пиковых условиях
- Сбор данных для тестовых сценариев
- Какое реальное количество одновременных пользователей ожидается?
- Какие места в приложении «принимают» больше пользователей?
- Какой результат нагрузочного тестирования будет приемлемым?
- Написание тестовых сценариев
- Выполнение сценариев
- Работа с результатами тестирования
Какой результат ожидается от нагрузочного тестирования?
При нагрузочном тестировании веб-приложения, тестировщик может получить огромное количество данных по поведению приложения под нагрузкой. Если не продумать тесты наперед, не рассчитать результаты, то есть вероятность упустить что-то важное. Нужно думать, что ты хочешь от тестирования.
Что нужно уяснить во время нагрузочного тестирования:
- Какой элемент приложения будет “стопорящим” (так называемый bottleneck), когда резко возрастет количество пользователей?
- Корректно ли масштабируется приложение под большой нагрузкой?
- Корректно ли ведет себя приложение во время тестирования в условиях, имитирующих реальную нагрузку?
- Сколько пользователей одновременно может работать с приложением в “пиковых” условиях?
- Как время ответа (response time) изменяется в ответ на рост числа пользователей?
- Как можно оптимизировать производительность приложения?
Как мы будем тестировать приложение?
В нашем тестовом наборе будет несколько сценариев. Сценарии будут состоять из этапов, каждому из которых соответствует какое-то количество пользователей (в терминологии нагрузочного тестирования — потоков, или виртуальных пользователей, или VU—пользователей). Виртуальные VU-пользователи будут направлять трафик в приложение.
Также задается так называемая скорость роста пользователей, и скорость снижения. Это показатель ступенчатого роста и снижения количества новых одновременных пользователей в приложении.
Будем тестировать приложение в двух условиях нагрузки.
При реалистичной нагрузке
Когда приложение идет в релиз, нужно удостовериться, что оно способно выдержать какой-то приемлемый трафик. Для этого проводится анализ паттернов поведения пользователей (как они обычно работают с приложением), и создать тестовые сценарии, имитирующие реальное поведение.
При пиковой нагрузке
Тестирование в пиковых условиях задействует те же сценарии что в реальных, но с другими параметрами. Количество одновременных пользователей повышают выше реалистичных значений, пока приложение не перестанет отвечать на запросы. Такая нагрузка считается максимальной емкостью приложения.
Сбор начальных данных для сценариев
Тестовым сценариям требуется ввод каких-то данных, имитирующих паттерны поведения реальных пользователей. Для этого нужно поставить следующие вопросы:
Какое максимальное количество одновременных пользователей ожидается?
Если веб-приложение является заменой или апгрейдом уже существующего приложения, это намного проще. Уже можно знать примерные количества пользователей, которые будут реалистичными.
- Идем на страницу «Сессии» или «Пользователи» в приложении аналитики посещаемости (той же Google Alalytics, Яндекс.Метрике и т.п.)
- Находим самый нагруженный день за последний год.
- В этом дне, выделяем 2 самых нагруженных часа.
- Из этих цифр посещаемости, вычисляем количество одновременных пользователей, по формуле:
Количество одновременных пользователей = (количество пользователей за 2 часа) * среднее время проведенное на странице, в секундах / 3600 секунд / 2 часа = ?
Так мы находим количество одновременных пользователей в самом нагруженном дне за последний год, и это будет наш искомый параметр для расчета нагрузки в реалистичных условиях.
В нашем случае, у нас было 20 тысяч сессий, а среднее время проведенное на странице составило 2 минуты. В итоге получилось 333 одновременных пользователя.
Всего сессий за 2 часа = 20 000 сессий
Среднее время проведенное на странице = 120 секунд
Одновременных пользователей = 333 пользователя
Какие части веб-приложения нагружаются больше всего?
Это важно знать, чтобы сбалансировать части приложения, базируясь на реалистичных ожиданиях.
Например если главная страница принимает больше всего трафика, то тестовый набор должен в первую очередь оценивать главную страницу. Опять же, для этого нужно внимательно посмотреть соответствующий раздел в Google Analytics.
Анализ может выглядеть примерно так (сайт магазина):
| Страница | Процент трафика |
|---|---|
| / | 60% |
| /articles | 20% |
| /shop | 15% |
| /contact | 5% |
Проверяем пределы выносливости приложения
Теперь нужно знать предел, на котором приложение перестает отвечать на тестовые запросы.
- Сколько времени приложению нужно, чтобы обработать запрос?
- Какой ответ считается успешным?
| Максимальное время ответа | 30 секунд |
| Успешный ответ (HTTP-код) | HTTP 200, 201, 301, 302, 308 |
Эти пределы должны быть испытаны в тестовом наборе.
Создание тестовых сценариев
Когда у нас уже есть вводные данные, можно приступать к написанию тестовых сценариев. Набор надо отконфигурировать, вводя в него эти сценарии, и затем вывести результаты отдельно по каждому, чтобы было проще анализировать результаты.
В таблице ниже — у нас 3 сценария реалистичной нагрузки, и 3 сценария пиковой нагрузки. При пиковой нагрузке количество одновременных пользователей увеличивается “по ступенькам”, таким образом и оценивается устойчивость приложения.
Нужен также “нулевой сценарий”, когда пользователь только один. Тогда имеем прямую линию, “базовую”, она нужна чтобы видеть “базовое” время ответа при отсутствии нагрузки. “Базовая линия” позволяет оценить влияние скачкообразных повышений нагрузки.
| Сценарий | Одновременное количество пользователей | Время роста нагрузки | Длительность нагрузки |
|---|---|---|---|
| Один пользователь | 1 | 0 минут | 5 минут |
| Реалистичные условия #1 | 100 | 5 минут | 20 минут |
| Реалистичные условия #2 | 200 | 10 минут | 30 минут |
| Реалистичные условия #3 | 350 | 20 минут | 60 минут |
| Пиковые условия #1 | 300 | 10 минут | 30 минут |
| Пиковые условия #2 | 400 | 15 минут | 40 минут |
| Пиковые условия #3 | 600 | 20 минут | 50 минут |
Выполнение тестов
После создания плана, и написания скриптов, выполняем тесты.
При этом надо учесть следующее:
- Запускаться тестовый набор должен на сервере достаточной мощности, способном генерировать пиковую нагрузку на веб-приложение.
- Наладить мониторинг в реальном времени, чтобы сразу видеть последствия нагрузки; как высокий трафик влияет на веб-приложение и другие части сервера.
- Тестировать приложение в продакшн-среде, или среде, сопоставимой по мощности.
- Выполнять нагрузочное тестирование надо с привлечением разработчиков приложения, чтобы они видели как приложение себя ведет при пиковой нагрузке.
Разбор результатов
Все это выглядит примерно так:

После тестирования нужно сохранить результаты — в raw-форме, и в виде скриншотов мониторинга, а также ситуации неожиданных сбоев и т.п. Лучше всего сохранять результаты в системе контроля версий (там же сохраняя скрипты выполненного тестирования). Это нужно, чтобы при переносе в другое окружение не пришлось заново писать скрипты и настраивать окружение.
Также желательно написать выводы из тестирования, в виде ответов на перечисленные в начале вопросы. Таким образом, создастся удобный отчет, фиксирующий текущую устойчивость приложения.

Всем привет!
Меня зовут Дмитрий Винокуров и я работаю инженером по нагрузочному тестированию в Miro. Я хочу рассказать о личном опыте и опыте нашей команды в развитии направления нагрузочного тестирования (для краткости НТ). В статье я расскажу самые основы НТ, как на эти основы ложится наш процесс и на какие конкретные шаги он делится. Наш опыт местами может быть специфическим, но по большей части он будет применим ко многим компаниям, разрабатывающим веб-приложения и не только.
Новичкам статья полезна будет тем, что содержит введение в нагрузочное тестирование и базовый план действий, а опытным людям покажет пример того, как делают НТ в другой компании, и даст возможность почерпнуть что-то новое для себя или наоборот даст повод поделиться своим опытом, поэтому буду рад комментариям и примерам из вашего опыта.
Описываемый подход основывается на нашем опыте и множестве просмотренных и прочитанных материалов. Подобный доклад делался на конференции DUMP в Екатеринбурге 14 мая 2021 г., эта статья представляет собой значительно дополненный и переработанный вариант выступления.
Автор арта на «обложке» — Orest Terremoto.
Содержание
- О Miro и об авторе
- Что такое нагрузочное тестирование?
- Что нужно для нагрузочного тестирования?
- Этапы нагрузочного тестирования
- С чего начинали нагрузочное тестирование в Miro
- С какими препятствиями столкнулись при развитии нагрузочного тестирования в Miro
- Роли, которые в Miro решили воспитывать в инженерах команды нагрузочного тестирования
- Некоторые общие принципы работы QA в Miro
- Распределённая команда нагрузочного тестирования в Miro
-
Процесс нагрузочного тестирования в Miro
- Детализация требований
- Подготовка тестового окружения
- Подготовка сценария
- Запуск теста и измерения
- Анализ
- Отчёт
- Результаты внедрения нагрузочного тестирования в Miro
- Планы в отношении нагрузочного тестирования в Miro
- Пожелания читателям
- Полезные ссылки
Наша компания разрабатывает веб-приложение Miro — онлайн платформу для совместной работы с множеством интеграций. В основе используется бесконечная интерактивная доска, на которую можно добавлять текст, схемы, изображения, стикеры, таблицы, эмоджи, майндмапы, связывать с тикетами в Jira, создавать канбаны и многое другое. Приложение содержит удобные инструменты для проведения мозговых штурмов, воркшопов, планирования проектов, дизайна новых продуктов и сервисов, фасилитации Agile встреч, презентаций и многого другого.

Цель Miro — дать возможность распределённым командам работать так эффективно, как будто они находятся в одном помещении.
Что особенно важно относительно темы статьи — Miro поддерживает совместную работу в реальном времени большого числа пользователей, в этом самая основа нашей платформы. Это причина, почему нам особенно нужно нагрузочное тестирование. Когда люди собираются у одной оффлайн доски в офисе — они не испытывают никаких задержек в коммуникации и в работе с доской, так же и у нас, только в намного больших масштабах.
В прошлом году внезапно множество людей перешло на удалёнку по известным причинам и им понадобились инструменты для удалённой работы, подобные нашему. Количество зарегистрированных пользователей в Miro с начала 2020 до весны 2021 выросло в 8 раз, другие метрики росли схожим образом. Поэтому нам понадобилось срочно развивать все имеющиеся наработки по нагрузочному тестированию. Причём это не краткосрочная задача, а, учитывая перспективы рынка, весьма долгоиграющая. Что получилось и что ещё предстоит — об этом и будет статья.
Сам я уже около 12 лет занимаюсь разработкой ПО и последние несколько лет — разработкой инструментов автоматизации тестирования. Ещё я активно участвую в работе над публичной базой знаний по НТ вместе с соответствующим сообществом, ссылки про это и многое другое будут в конце статьи.
Что такое нагрузочное тестирование?
Нагрузочное тестирование — это тип тестирования, в котором мы проверяем, соответствует ли наша система поставленным нефункциональным требованиям к производительности при работе под высокой нагрузкой в различных сценариях. Это намного сложнее, чем unit тестирование, где всё просто работает или нет. При нагрузочном тестировании снимается целый ряд метрик, и даже задача проверки на соответствие требованиям уже является непростой. Существенные трудности состоят также в том, как воспроизвести поведение пользователей с прода, как воспроизвести сам прод, в том числе базу, и как поставить тестирование так, чтобы ручная работа была минимальной.
Тестирование вообще — это способ узнать об ошибках не от конечных пользователей, а раньше, и тем самым избежать потерь, репутационных и прочих. Нагрузочное тестирование — это способ подготовиться к высоким нагрузкам заранее и сделать так, чтобы большое число запросов от множества пользователей было благом, а не головной болью. Причин для бурного роста может быть множество и отказываться от подготовки к таким сценариям значит существенно повышать риск выхода из строя вашей системы в тот момент, когда она стала особенно нужна людям.
Что нужно для нагрузочного тестирования?
Итак, мы определились, НТ нам нужно, теперь перед его проведением необходимо наличие ряда ресурсов:
- Общие требования. Нам нужно понимать, чего мы ожидаем от нашей системы в контексте нагрузки и производительности, хотя бы в общих чертах. Это может звучать просто, но не всегда у людей есть ясное представление о таких требованиях. «Система должна отвечать быстро под высокой нагрузкой» — это не требование, это пожелание. Я покажу примеры удачнее дальше в статье.
- Специалисты. Для проведения НТ нужны инженеры. Поскольку серьёзное тестирование всегда требует автоматизации, нужны инженеры с навыками тестирования и разработки, а также аналитики и девопсы.
- Платформа для тестового окружения. Если вы делаете НТ в первый раз — вам определённо понадобится подготовить инфраструктуру. Хорошо если у вас внедрён подход IaC (англ. infrastructure as a code, инфраструктура как код), он очень пригодится для создания окружения, подобного проду. Если нет — надо внедрять или придётся страдать даже на небольших конфигурациях. И в подавляющем большинстве случаев тестирование на проде — плохая идея. Но есть и исключения, можете погуглить «Netflix testing in production».
- Время. НТ — это очень затратный по времени процесс, особенно когда вы делаете его впервые. Автоматизация экономит много времени, но всё равно нужно быть готовым потратить на подготовку и проведение НТ несколько дней или существенно больше, зависит от масштабов прода, используемого стэка, сценариев использования и поставленных задач.
Этапы нагрузочного тестирования
Мы собрали то, что необходимо для НТ. Перейдём к плану действий.
- Детализация требований — что требуется от системы в терминах нагрузки и производительности, какой тип теста проводим и какие метрики необходимо собрать для проверки требований. Как я писал ранее, общие требования нужны ещё до тестирования, а когда процесс начат, нужно их декомпозировать в предельно конкретные и технические требования. Также нужно выбрать тип теста, реализуемого в тестовом сценарии, и составить список метрик, на сбор которых нужно настроить приложение, сценарий и инфраструктуру. Это аналитическая задача.
- Подготовка тестового окружения — где будем моделировать прод и пользователей. Необходимо выбрать одно из доступных или создать новое тестовое окружение под разработанные требования и настроить сбор метрик, нужных для оценки степени соответствия требованиям. Это задача DevOps специалистов.
- Выбор инструмента тестирования и подготовка сценария — как будем моделировать поведение пользователей. В сценарии тоже нужно запрограммировать сбор метрик. Это задача разработки.
- Проведение теста и замеры — каковы значения метрик. Это может звучать просто, но весьма редко всё работает с первого раза. Бывает нужно откатиться на один из предыдущих шагов и что-то поправить. На данном этапе проводится анализ некоторых ключевых показателей, чтобы убедиться, что нет критических ошибок теста. Этот шаг — задача тестирования. Основная работа по анализу будет вестись на следующем этапе.
- Анализ — соответствует ли система требованиям, есть ли проблемы. Если собираются правильные метрики, всё должно быть относительно просто, хотя и трудоёмко, а если нет — опять может понадобиться откатиться вплоть до первого шага. Здесь, в отличие от предыдущего шага, мы глубоко погружаемся в большое количество метрик чтобы выявить все возможные значимые факты. Это аналитическая задача.
- Подготовка отчёта — какие знания мы получили?.. Это самый важный этап. НТ — процесс очень затратный по ресурсам и вы явно захотите получить максимум знаний от него. Снова аналитическая задача.
Есть ещё один этап, опциональный — план улучшения системы, то есть ответ на вопрос «как можно исправить обнаруженные недостатки?». Это не относится напрямую к нагрузочному тестированию, но упомянуто здесь, потому что результаты НТ в большинстве случаев должны быть «actionable», побуждать к действиям. Как видно из списка выше, нужны разные роли для проведения всего процесса НТ и эти роли должны сочетать в себе или одни люди, или нужно привлекать разных специалистов.
С чего начинали нагрузочное тестирование в Miro
К росту нагрузки мы начали готовиться задолго до пандемии и вот что у нас было:
- Несколько человек занимались НТ часть своего времени.
- Мы использовали JMeter как наиболее популярное решение. У нас был свой плагин для WebSocket, так как ключевой функционал Miro связан с работой с досками и требует очень быстрого клиент-серверного взаимодействия, как в играх. Кстати движок, с которого много лет назад начинала компания, был как раз игровым. Это с самого начала дало высокую интерактивность и скорость отклика.
- Наш кластер был prod-like. К счастью, у нас был IaC. Нельзя сказать, что IaC — это серебряная пуля, сложности с ним тоже есть, но без него сложности с ростом масштаба становятся фатальными препятствиями.
- Один достаточно объёмный и сложный WebSocket&HTTP API тест.
Ссылки на подробности про предыдущие наработки и многое другое будут в конце статьи.
С какими препятствиями столкнулись при развитии нагрузочного тестирования в Miro
НТ, особенно для сложной системы, — задача непростая. Чем глубже мои коллеги погружались в неё, тем больше возникало сложностей.
Технические препятствия:
- JMeter перестал нас устраивать. В нём было очень неудобно программировать и отлаживать. Сложные сценарии — это почти всегда разработка, а не заполнение форм или написание отдельных небольших скриптов. Сценарий в JMeter — это не программа в обычном понимании, а сочетание инструкций, заполненных в формах, с встроенным кодом скриптов. Также в JMeter плохо с контролем версий, т.к. сценарий хранится в огромном XML. А у нас большое количество WebSocket взаимодействия со своим бинарным протоколом и достаточно сложные сценарии, над которыми работает несколько человек. Не хотелось изобретать обходные пути вокруг «особенностей» JMeter.
- Много ручных действий для каждого запуска НТ на тестовом окружении. TODO лист состоял из 16 пунктов для каждого запуска, которые надо было проделывать вручную… И это была боль… А боль — это сильный стимул что-то поменять.
- Не хватало инструментов для генерации разных распределений тестовых данных. А сценарии тестирования для разных компонентов возможны разные и нужно было уметь быстро создать нужное распределение. Идеально использовать базу максимально близкую проду и откатывать после каждого теста, но не всегда это возможно: это могут быть огромные объёмы и надо чистить сенситивные данные пользователей, а воспроизводить синтетические данные в нужном объёме — тоже сложная задача.
Организационные препятствия:
- Много задач.
- Недостаточно опыта.
- Недостаточно доступных людей.
Роли, которые в Miro решили воспитывать в инженерах команды нагрузочного тестирования
Итак, мы столкнулись с рядом трудностей в проведении НТ и конечно можно было подумать «а давайте просто наймём больше QA инженеров» и действительно надо было нанимать людей специально для НТ, но вопрос на самом деле шире. QA инженеров нанять недостаточно, учитывая сложность этого направления необходимо было строить многопрофильную команду. Причём часть ролей отводилась будущим сотрудникам, а часть — имеющимся.
Так почему нам было недостаточно просто QA? Главная причина — прогнозируемый уровень сложности задач по НТ. У нас несколько десятков команд, все разрабатывают компоненты, которые должны работать в соответствии с требованиями по производительности в составе сложной системы. Но у каждой компании свой масштаб разрабатываемых систем. Кому-то может хватить просто одного человека, который умеет в JMeter, и может даже особо большого кластера для подачи нагрузки не понадобится. Кому-то нужно будет значительно больше, чем надо было нам. Всё зависит от уровня сложности системы.
С ростом скорее всего происходит более узкая специализация, но у нас для инженеров НТ было решено развивать следующие роли:
- QA. Должен уметь искать проблемные места и выстраивать процесс обеспечения качества.
- Аналитик. Должен уметь выявлять причинно-следственные связи, исследовать паттерны поведения пользователей и разбираться в сложных системах.
- Разработчик. Должен уметь проектировать и программировать средства автоматизации и тестовые сценарии.
- Преподаватель*. Должен уметь помогать учиться специалистам из других команд и готовить базу знаний, причём здесь речь не только про документацию.
- DevOps*. Должен ориентироваться в архитектуре тестового окружения и уметь её модифицировать.
* 4-я и 5-я роли только для участников «центра» НТ команды, а не для всех НТ инженеров, о конкретной структуре я расскажу чуть позже.
Некоторые общие принципы работы QA в Miro
В нашей компании есть QA гильдия, объединяющая QA инженеров из разных функциональных команд и инженеров, разрабатывающих и отвечающих за общие инструменты обеспечения качества. И раз НТ у нас — это часть QA, а для QA уже были сформулированы и применялись ряд принципов, то и к НТ они были применены.
Вот ключевые из этих принципов:
- Ответственность за качество лежит на всей команде. Не только на QA инженерах.
- Тесты всех уровней пишут QA и разработчики. Чтобы не было пинг-понга «сделал-проверь-поправь-проверь-поправь-проверь-вроденорм».
- Минимизация эффекта «единой точки отказа». Чтобы не было так, что QA в отпуске, а критичные баги просочились на прод.
- Главный фокус QA инженеров — построение процесса разработки с точки зрения качества. Не столько искать ошибки, сколько предотвращать. Уровень задач становится выше, чем просто тестирование.
Распределённая команда нагрузочного тестирования в Miro
Если ранее я рассказывал об опыте коллег, то в описываемом далее я принимал уже непосредственное участие. В компанию вместе со мной были взяты люди, которые занимались уже только НТ. И вот какую команду мы строили и какими задачами занимались.
-
«Центр» — команда НТ — центр компетенций и поддержки. Зоны ответственности:
- Разработка инструментария (особое внимание к качеству!). У функциональных команд заказчик — клиенты Miro, у нашей команды заказчик — функциональные команды. Внутренние инструменты не должны быть поделками, сделанными «на коленке». Это должны быть полноценные и качественные продукты с должным уровнем поддержки всех видов. Функциональные команды и так загружены и повышать их уровень стресса плохими инструментами — недопустимо. Поэтому у нас есть:
- Мастер-классы.
- Miro доски-презентации.
- Confluence документация.
- Версии, changelog, детальная отладочная информация в ходе работы инструмента.
- Общий репозиторий с примерами кода и всеми НТ сценариями, чтобы было единое место, где собрана вся практика НТ.
- Отдельные чаты на каждый инструмент для поддержки, сообщений о релизах, багрепортов и фичереквестов.
- Помощь в обучении и консультирование коллег из функциональных команд, не только QA инженеров.
- Проведение больших тестов, когда нужна проверка суммы функционала от множества команд.
- Поддержка тестовых окружений совместно с QA Automation Team и DevOps Team.
- Разработка инструментария (особое внимание к качеству!). У функциональных команд заказчик — клиенты Miro, у нашей команды заказчик — функциональные команды. Внутренние инструменты не должны быть поделками, сделанными «на коленке». Это должны быть полноценные и качественные продукты с должным уровнем поддержки всех видов. Функциональные команды и так загружены и повышать их уровень стресса плохими инструментами — недопустимо. Поэтому у нас есть:
- «Агенты» — QA инженеры и разработчики в функциональных командах — проводят более узконаправленные тесты.
Процесс нагрузочного тестирования в Miro
Шаг 1/6. Детализация требований
Мы рассмотрели, что такое НТ и посмотрели на то, как устроена распределённая команда НТ в Miro. Теперь пройдёмся по этапам НТ, наложенным на наш процесс. Начнём с самого важного этапа.
Ещё раз подчеркну, что к формулировке требований стоит подойти особенно ответственно. Без чёткого понимания, чего вы хотите от тестируемого приложения, дальше двигаться нельзя.
Источники требований
- OKR, цели и ключевые результаты. Часть из них может относиться к поддерживаемой нагрузке и производительности для всех многопользовательских систем.
- Соглашения о качестве работы системы. Все, кто работают с клиентами, должны обеспечивать определённый уровень качества, формально описанный или неформально принятый. И это лучшее место для спецификации таких нефункциональных требований, как требования по производительности.
- Аналитика сайта. Нужна не напрямую для формулировки требований, а для определения текущего профиля использования, который может служить основанием для сценария воспроизведения поведения пользователей и как основа для прогнозов.
- Пользовательские сценарии. Мы должны понимать, как наши клиенты используют нашу систему, чтобы понимать, каким частям системы уделить внимание.
- Прогнозы. Мы должны примерно представлять, что будет в будущем с показателями использования системы и всегда иметь запас прочности.
- Знания и опыт продакт-менеджеров. Не всегда всё нужное зафиксировано в документах и мониторинге.
Остановлюсь подробнее на паре используемых нами инструментов:
- Looker — инструмент для сбора и анализа бизнес-показателей. Мы сформулировали требования, далее в ходе составления сценария в большинстве случаев нам нужно опираться на множество текущих показателей работы прода. Здесь могут помочь такие бизнес-показатели, как данные о том, какой диапазон размера досок используется каким количеством пользователей.
- Grafana — примерно то же самое, но для системных метрик. Например, мы хотим проверить требование «Miro должен держать 500К онлайн пользователей с такими-то показателями скорости ответа по критичным компонентам». Чтобы смоделировать это, нужно знать, как при существующем уровне нагрузки используется сайт, какими функциями и с какой частотой пользуются клиенты, чтобы в итоге перевести абстрактных «500К пользователей» в RPS по основных типам запросов. В получении RPS как раз помогает Grafana.
Выбор модели нагрузки
Различают две модели нагрузки:
- Закрытая. В генераторе нагрузки есть очередь определённого размера: если она заполнена и ответы от сервера ещё не пришли, то новые запросы не отправляются до тех пор, пока не поступят ответы на старые запросы. Серверу стало плохо? Подождём, пусть разгребёт.
- Открытая. Генератор нагрузки отправляет запросы, не дожидаясь ответов сервера и не обращая внимания на его состояние. Серверу стало плохо? Это его проблемы, жизнь такая, продолжаем грузить.
Подробнее по отличиям этих моделей нагрузки и про сценарии использования каждой можно посмотреть в видео из школы Яндекса — «Нагрузочное тестирование типичного интернет-сервиса» от Андрея Похилько.
Выбор типа теста
Для разных требований нужны разные тесты. Вот основные примеры типов тестов:
- Smoke-тесты — проверка всех составляющих НТ на малом масштабе.
- Тесты на базовый уровень — снимаем текущие метрики работы системы.
- Тесты на объём — выдержит ли система повышенную нагрузку при «нормальном» сценарии использования?
- Тесты на лимиты — до какого уровня можно грузить систему, прежде чем она начнёт деградировать?
- Тесты на стабильность — как долго система сможет держать определённый уровень нагрузки?
- Тесты на масштабируемость — ведёт ли добавление новых серверов к поддержке большего числа запросов?
- Тесты на пиковые нагрузки — выдержит ли система резкое повышение нагрузки?
- Тесты на восстанавливаемость — достаточно ли быстро система восстанавливается после сбоя?
- Тесты на взаимодействие — эффективно ли взаимодействуют компоненты системы?
- Деградационные тесты — один или несколько тестов, описанных ранее, запускаются автоматизированно и регулярно, с построением отчётов с отображением динамики за длительный период.
Эти тесты могут быть совмещены и не все могут быть нужны.
Декомпозиция требований
«Cистема должна отвечать быстро при высокой нагрузке» – это плохое требование, слишком расплывчатое и оставляющее больше вопросов, чем определённости в том, как его проверять.
Более конкретное требование — «система должна обеспечивать столь же комфортный опыт использования как сейчас при росте нагрузке в X3 пользователей». Здесь указано, что такое «высокая нагрузка» — указано «X3 пользователей» и указано что опыт работы с системой должны быть «столь же комфортным как сейчас». Здесь есть на что опираться — на текущие показатели работы с системой.
Детализация означает конвертацию пользователей в RPS, основываясь на существующем и ожидаемом профилях использования. Такая конвертация уместна только для Stateless протоколов, как самые распространённые HTTP и HTTP, а для Stateful число подключенных клиентов может быть очень важно, как например для FTP, протокола работы с MySQL или некоторых банковских протоколов. Ещё один важный момент — не доверяйте средним значениям времён ответа, используйте персентили, т.к. среднее зачастую является плохой метрикой.
Вот примеры конкретных требований, которые могли быть получены из высокоуровнего и других источников данных:
- RT1. Запрос типа #1 при нагрузке X1 RPS должен иметь p(50) в A1 ms, p(95) в B1 ms …
- RT2. Запрос типа #2 при нагрузке X2 RPS должен иметь p(50) в A2 ms, p(95) в B2 ms …
- …
- ER1. Процент ошибок для критичных сервисов не должен превышать N%
- ER2. Процент ошибок для некритичных сервисов не должен превышать M%
- …
- IS1. Нагрузка CPU не должна превышать P%
- IS2. Система должна иметь резерв для обработки +10% нагрузки
- …
Метрики
Есть очень хорошая книга по SRE от Google, где среди прочего описаны «4 золотых сигнала»:
- Время ответа. Именно то, что заметит пользователь.
- Трафик. RPS, число запросов в секунду, всё просто.
- Ошибки. Об их максимально допустимом проценте могут быть свои требования.
- Насыщение. Если даже требования по остальным показателям выполняются, но при этом сервера загружены по полной — это должно наводить на соответствующие выводы. Всегда нужно иметь запас.
И даже если попытаться, сложно придумать другие необходимые категории метрик. Все 4 необходимы и достаточны.
Естественно, метрики всех четырёх типов тесно взаимосвязаны. Повышение трафика и соответственно насыщения со временем приведёт к росту времени ответа и ошибок. Резко упавшее время ответа может говорить о том, что у нас отказала БД и время ответа упало из-за того, что все запросы просто быстро завершаются с ошибкой.
Некоторые добавляют и другие показатели. Например, стабильность, которая показывает как долго система может работать без остановки и как быстро восстанавливается после проблем. Это сложный показатель и скорее его стоит отнести не к типам метрик, а к выводу отчёта после целого теста на стабильность. Подобная ситуация с доступностью и масштабируемостью. Есть ещё понятие критического ресурса, как компонента, от которого сильнее всего зависит качество работы всей системы.
APDEX
Индекс производительности приложений Application Performance inDEX (APDEX) может быть использован для преобразования ряда времён ответов в одно число, если определены диапазоны удовлетворительных, допустимых и недопустимых времён.
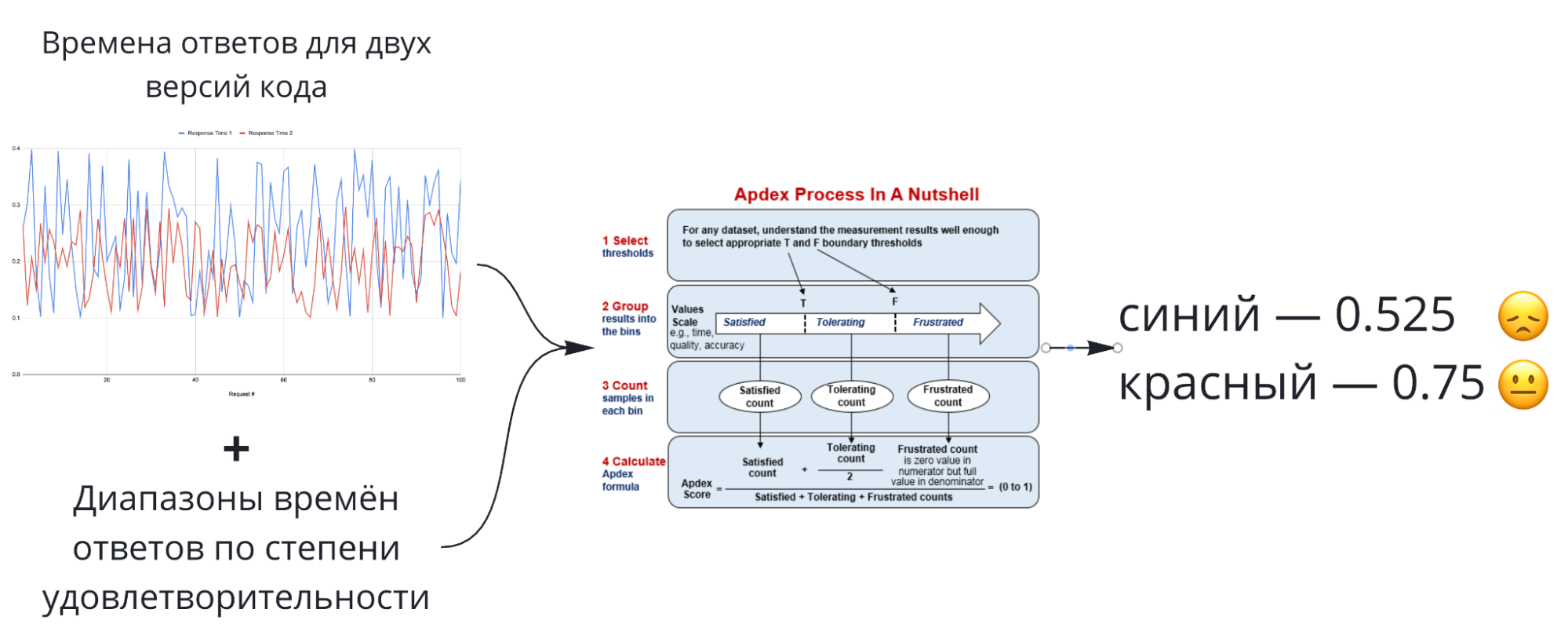
Значения APDEX легки в сравнении, но тяжелы в интерпретации.
Шаг 2/6. Подготовка тестового окружения
Сценарий готов, далее нужно подготовить целевую систему, которую тестовый сценарий будет проверять.
Тестовое окружение состоит из двух частей:
- Целевая система (имитация прода).
- Кластер подачи нагрузки (имитация пользователей).
Для их реализации у нас используются:
-
IaC
- AWS. Когда счёт используемых серверов идёт на десятки и сотни, без автоматизации никак. У нас был давно принят выбор перейти от арендованного железа в облако. Вопрос выбора конкретного провайдера (AWS, Google Cloud, Microsoft Azure) — тема отдельного доклада. Я лишь скажу, что в своих инструментах я активно использую AWS API и это на самом деле удобно, не знаю как можно было бы жить без этого или аналогичного инструмента.
- Terraform, Terragrunt (дефакто стандарт для IaC)
-
Ansible. Систем управления конфигурациями много и многие по-своему хороши, тут надо девопсов спрашивать почему Ansible, хотя мне как в основном Python-разработчику нравится этот выбор

-
Свой управляющий инструмент (консольная Python утилита с множеством команд, опций и конфигом), который выполняется в части подготовки тестового окружения (он же ещё используется при запуске сценария)
- Запуск кластеров целевой системы и подачи нагрузки.
- Деплой версий и запуск приложений на серверах приложений.
- Создание серверов подачи нагрузки.

Шаг 3/6. Подготовка сценария
Мы определились с тем, что требуется от системы и как пользователи с ней работают, теперь это поведение нужно смоделировать в тестовом сценарии.
Эскиз на человеческом языке
Перед началом разработки хорошей практикой является создание эскиза сценария на «человеческом языке». Это поможет выразить, какое поведение пользователей планируется моделировать без траты времени на погружение в детали инструментов НТ. И инструмент тоже поможет подобрать, если такой вопрос стоит. А ещё, при составлении отчёта, такой эскиз поможет ревьюерам понять моделируемое поведение пользователей, не погружаясь в код.
Как было показано ранее, на этапе детализации требований мы разделяем активность пользователей на отдельные RPS. Иногда бывает нужно ещё объединять запросы в подобие подсценария.
Вот пример такого эскиза сценария:
- Подсценарий #1 — получение уведомлений (X RPS)
- Подсценарий #2 — получение статуса серверов (Y RPS)
- Подсценарий #3 (Z SPS)
- Логин
- Открытие дэшбоарда
- Открытие доски с W1 виджетов для U1 доли пользователей, W2 для U2 и так далее
- Движение курсором
- Добавление нескольких виджетов
- Закрытие доски
Выбор инструмента
В данный момент у нас используется три инструмента для НТ:
- Свой инструмент для моделирования работы с досками.
- k6. Для него мы в своём управляющем инструменте реализовали обёртку для кластерного запуска и сбора результатов.
- JMeter (legacy, практически не используется).
Вообще говоря, с инструментами НТ вопрос сложный. Их множество и коллегами был проведён детальный разбор наиболее популярных, чтобы понять, что сможет справиться в первую очередь с ключевым функционалом Miro — работой с досками. У нас используется бинарный протокол, работающий через WebSocket, требуемый для высокой скорости работы с досками. Основы, необходимой для его реализации, не было найдено и между доработкой какого-то из имеющихся решений и разработкой собственного узкоспециализированного решения выбор был в пользу второго варианта, разработки своего инструмента. Насчёт остальных направлений НТ и выбора инструментов — мы решили не ограничивать команды, а реализовывать поддержку в нашем управляющем инструменте для каждого инструмента, который коллегам показался подходящим. Под управляющим инструментом я имею ввиду средство управления тестовой средой и запуска НТ, об этом будет позже. Интеграция в него дополнительного инструмента НТ — задача в принципе несложная, поэтому мы можем позволить командам пользоваться тем, чем им мы удобно. Так, например, несколько человек экспериментируют с Locust. А мы наблюдаем за успешностью использования инструментов и на базе этого формируем проверенные практикой советы по выбору инструмента НТ для тех, кто только начинает этим заниматься.
Исследование
Ещё один шаг перед написанием кода — исследование того, как реальный фронтенд взаимодействует с бэкендом с помощью инструментов разработчика в браузере и попробовать несколько простых взаимодействий вручную, например через Postman.
Но иногда проще начать сразу с кода.
Данные
Было бы идеально тестировать на базе, подобной проду, и сбрасывать её перед каждым тестом, но это очень редко возможно из-за колоссальных объёмов данных и необходимости использования сложных инструментов чистки реальных данных. Поэтому у нас есть свой инструмент генерации данных, который умеет создавать в нужном объёме и в разумный срок основные бизнес-сущности: пользователей, команды, организации, доски разного размера, проекты и строить связи между ними. Этот генератор использует то же API, что и основное веб-приложение, и каждый сеанс генерации данных представляет собой немного хаотичный пример НТ. На выходе получается подробный лог и набор файлов, которые можно подключать к НТ сценариям.
Советы по коду
При написании кода может быть полезно следовать таким рекомендациям (известным, впрочем, и в других областях):
- Сценарий нужно разрабатывать насколько возможно настраиваемым, чтобы иметь возможность например запустить его на других RPS без изменения кода, поэтому хардкод подобных параметров должен быть минимальным.
- Не стоит пренебрегать документацией по инструменту НТ. Не изобретайте колесо, инструменты НТ разрабатываются на основе большого опыта и в большинстве случаев то, что вам нужно, уже существует.
- Мониторинг чаще всего придётся доделывать на основе базовых компонентов, гораздо реже можно найти то, что идеально подойдёт.
- Помните, что чем больше статистики, мониторинга и логирование — тем выше побочная нагрузка, нужно уметь найти баланс.
- Никогда не используйте код подобный `… request(); sleep(N); request() …` для моделирования 60/N RPM, это не работает, найдите компоненты для вашего инструмента НТ, реализующие требуемую частоту запросов, или хотя бы используйте асинхронный код.
Шаг 4/6. Запуск теста и измерения
Целевая система готова, переходим к самому интересному — запуску теста и снятию метрик. Как я говорил ранее, НТ — это не функциональное тестирование, поэтому мы не просто снимаем ряд булевых показателей типа работает/не работает, а получаем целый ряд разнообразных метрик. Как разбираться в них — большая тема, здесь я затрону только некоторые моменты из неё.
Какие метрики снимать — есть базовый набор и есть специальные для каждого теста, это надо решать ещё при подготовке сценария и тестового окружения.
В ходе собственно выполнения теста у нас используются:
-
Свой управляющий инструмент. Функции:
- Деплой тестового сценария и данных (поддерживается несколько сценариев и инструментов НТ).
- Запуск теста.
- Сбор результатов и логов инструмента НТ.
- Универсальные средства мониторинга и сбора логов.
Здесь ещё можно упомянуть Open Source проект Taurus, который, как и наше внутреннее решение, предназначен для запуска разных инструментов НТ и поддерживает более 20 инструментов тестирования. Ещё есть тоже открытый Яндекс.Танк. Свой инструмент я решил разрабатывать, потому что задумывалась тесная интеграция с управлением тестовым окружением и инструмент больше про это. Сделать просто распределённый запуск инструмента НТ — задача не такая уж сложная.
И пара советов:
- Не пытайтесь сразу запустить полный тест, начните с нескольких небольших smoky-тестов. Проверьте, что сценарий выполняется как надо, RPS воспроизводятся и все нужные метрики собираются.
- Не стоит полагаться на сценарий и метрики полностью. Попробуйте поработать с системой вручную.
Шаг 5/6. Анализ
Паттерны
Давайте предположим, что сценарий выполнился и у нас множество метрик. На что стоит обратить внимание в первую очередь? Вот некоторые примеры. Первые три могут говорить или не говорить о неполадках, а последние вероятнее всего говорят о проблеме:
- «Пила». Значимые скачки показателя вверх/вниз с достаточно большими промежутками между ними могут говорить, например, о насыщении какого-то ресурса до предела и падении ряда агентов, поднятии новых и повторе ситуации. Или такой может быть внутренняя логика работы приложения.
- «Полка». Может говорить о том, что мы достигли предела и дальше система не справляется, хотя и не падает. Здесь надо смотреть состояние генераторов нагрузки, возможно больше этого предела они и не грузят и это не ошибка, а просто достижение необходимого уровня. Ещё это может быть предельное значение, выше которого подняться в принципе невозможно — например, загрузка CPU под 100%. Такие случаи требуют особого внимания.
- «Всплеск». Резкий скачок, причину которого надо изучать. Это может быть, например, внезапно запустившаяся сборка мусора. Но если это график ошибок, то очевидны проблемы.
- Резкое падение. Например, в начале теста при постепенном увеличении нагрузки может умереть один из воркеров, генерирующих трафик. Или это может быть график общего числа RPS для всего кластера, что может говорить об отказе одного из серверов.
- Плавная деградация. Это может быть, например, график RPS на сервере, которые начали проседать при стабильной нагрузке. Или обратная ситуация, нагрузка тоже стабильна, а на графике использование оперативной памяти в течение продолжительного срока. Тоже однозначно нужно обратить внимание.
- Линейный/нелинейный рост связанных показателей. Если некоторый входной параметр растёт линейно, важно чтобы уровень нагрузки подсистем тоже рос хотя бы линейно, но никак не быстрее на несколько степеней. Здесь самое время вспомнить про сложность алгоритмов: O(n), O(log n), O(n^2) и подобное. Чем сильнее нелинейность — тем меньше будет толку от новых и новых серверов.
На графиках ниже показаны синтетические примеры описанных выше паттернов: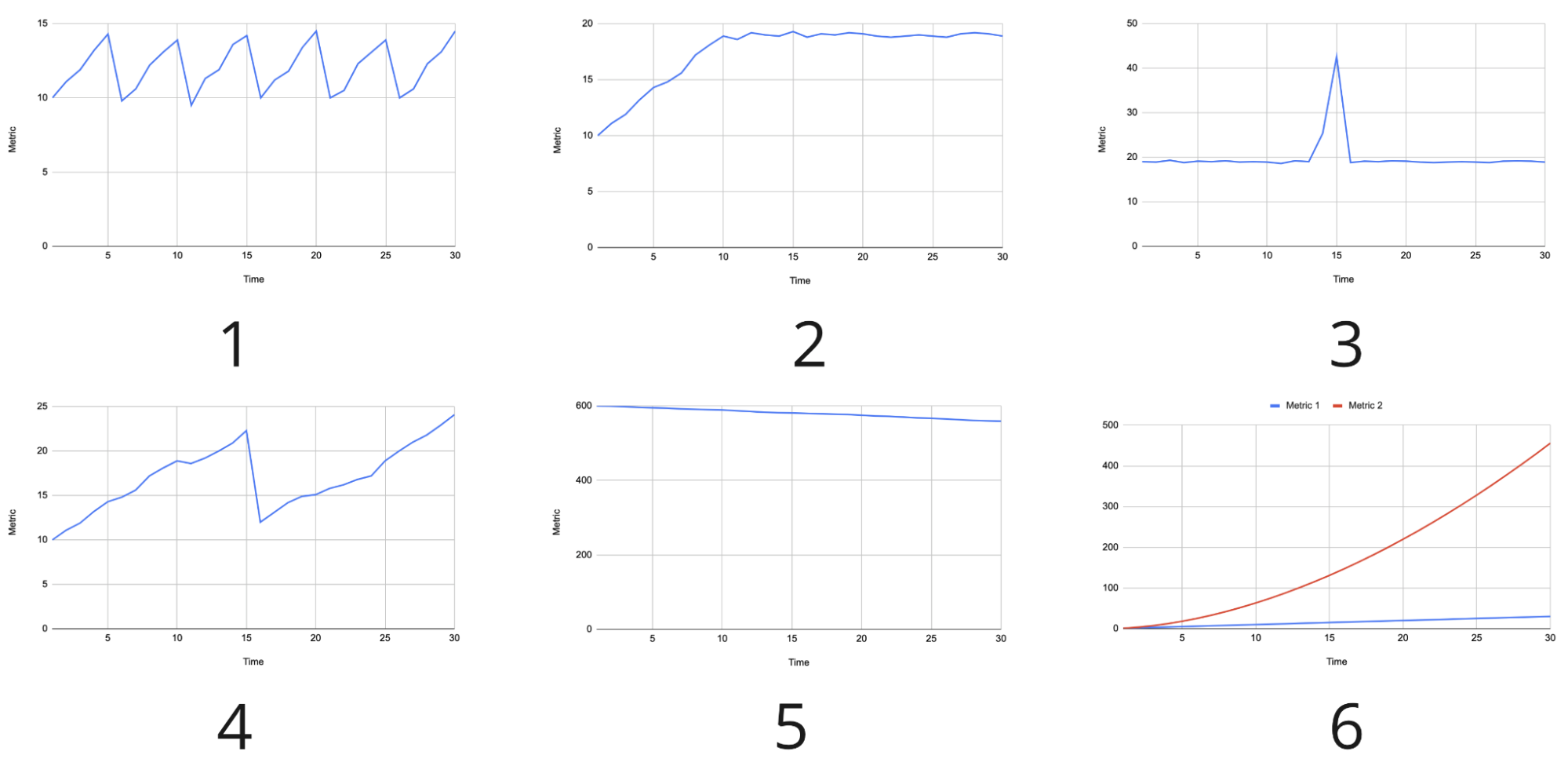
Пример
Разберём простейший пример, который может научить нескольким полезным вещам:
- Проблема: система отвечает слишком медленно на некоторый сценарий. Пусть 95-я персентиль времени выполнения стала 15 с вместо 2 с.
-
Анализ:
- Найти узкое место, которое тормозит сценарий. Пусть это будет некоторый API запрос.
- Проверить насыщение API серверов. CPU, RAM, IO, очереди сообщений и прочее.
- Проверить зависимости. Допустим, в нашей системе используется другой компонент системы, который отвечает слишком медленно.
- Проверить сервер, на котором работает этот другой компонент. Допустим там ~100% CPU.
- Действие — добавить результаты разбора в отчёт. Какие действия предпринимать, чтобы исправить проблему — это не такой простой вопрос. Изменить тип инстанса на больший — это просто, но это не всегда правильное решение. Если используется алгоритм с сильно нелинейной сложностью, то даже увеличение мощности CPU сервера ненадолго поможет.
-
Броки:
- Наблюдайте за всем, за чем можно, помня про побочную нагрузку от замеров.
- Ищите подлинные причины проблем.
- Простой вывод — не всегда правильный.
Шаг 6/6. Отчёт
Самое главное сделано. Остаётся подвести итоги и зафиксировать полученные в ходе нагрузочного тестирования знания. Особо хочу отметить, что НТ — это операция, требующая весьма существенных затрат труда, времени и прочих ресурсов. Поэтому вы явно захотите получить максимум пользы, потратив всё это.
Чтобы извлечь максимум пользы из проведённого НТ — нужен хороший отчёт. Каковы же критерии хорошего отчёта? НТ делается НТ инженерами не только и не столько для себя, а много для кого и для разных людей польза от отчёта зависит от наличия развёрнутых ответов на соответствующие вопросы:
- Для менеджера — насколько система соответствует требованиям, есть ли запас и какая ситуация может вызвать проблемы с системой?
- Для DevOps — есть ли слабые места системы со стороны инфраструктуры?
- Для разработчиков — есть ли слабые места системы со стороны кода?
- Для НТ инженера — какие инструменты НТ с какими настройками использовались, какой сценарий использовался, на какой конфигурации инфраструктуры проводился тест? Все эти знания в том числе для того, чтобы можно было воспроизвести сценарий при каких-либо изменениях кода или инфраструктуры для сравнения.
Нет отчёта — нагрузочное тестирование впустую!
Ещё один очень важный момент. Серьёзный подход требует регулярного НТ. Оно невозможно без автоматизации построения отчётов и степень этой автоматизации зависит от частоты проведения тестирования.
Результаты внедрения нагрузочного тестирования в Miro
Я рассказал о том, какие этапы НТ есть и как мы работаем на каждом из них.теперь перечислю, чего мы добились благодаря внедрению НТ в таком виде:
- Понятный и описанный процесс. Чётко описано, какие шаги нужно выполнить и что нужно делать на каждом из шагов.
- Большие тесты: 200K, 500K пользователей online при типичном сценарии использования. Каждый сложный тест зачастую проходит много итераций перед успешным выполнением, поэтому без автоматизации столько раз гонять большие тесты было бы чрезвычайно долгим и утомительным занятием, полным ошибок.
- Проверка компонентов перед выкаткой на прод.
- Обоснованный выбор параметров компонентов для поддержки планируемой нагрузки. То есть не просто с потолка брать «ну наверное хватит сотни воркеров», а выбирать параметры на основе результатов проверок.
- Автоматизация, упрощение и ускорение проведения НТ. Я говорил в начале про список из 16 пунктов, которые надо было пройти вручную при каждом запуске НТ на кластере. Теперь это один конфиг и одна команда. Больше автоматизации даёт больше надёжности и больше возможностей уделить время более творческим и сложным задачам.
- Деградационное тестирование (начало). Автоматическое выполнение тестов по реалистичному API сценарию на типичной нагрузке каждую ночь на последней версии сервера и построение графиков трендов для отслеживания динамики показателей скорости ответа и числа ошибок.
Планы в отношении нагрузочного тестирования в Miro
Несмотря на то, что было сделано многое, ещё больше предстоит. Вот планируемые направления развития:
- Деградационное тестирование (полноценная интеграция с CI/CD). В идеале постоянное НТ должно быть встроено в пайплайн и так же как функциональные тесты влиять на принятие решения о релизе.
- Тестирование микросервисов. Мы в процессе переезда с монолита, и всё больше работы появляется в этом направлении.
- Вовлечение большего числа команд. У нас их несколько десятков и пока не все включены в процесс.
- Улучшение инструментария. При бурном росте не всегда получается выдержать хорошую архитектуру, так что есть немного техдолга.
- Дополнение внутренней документации НТ примерами конкретных кейсов: как тестировали, что и как выявили, как доработали. Общая документация — это хорошо, но дополнение её солидным набором описаний конкретных кейсов — бесценно.
- Более исследовательская работа: профилирование, хаос-тестинг и т.д.
Пожелания читателям

Напоследок пожелаю следующее:
- Верьте в свой проект. Если не будете верить вы, пользователи и подавно не будут.
- Делайте НТ. Высокие нагрузки должны стать источником дополнительной прибыли или других благ, а не источником проблем.
- Делайте НТ заранее. Профилактика всегда лучше лечения.
- Делайте НТ правильно. Ресурсы у всех ограничены, и лучше тратить их с умом.
- Делайте НТ регулярно. Всё течёт, всё изменяется.
- Автоматизируйте. Ну это очевидно в 21 веке, я думаю.
Полезные ссылки
В ходе работ по НТ мной и моими коллегами были в том числе использованы источники из базы знаний, создание которой было инициировано русскоязычным QA Load сообществом и в которой я один из мейнтейнеров, также мы многое почерпнули и из самого чата этого сообщества. Ссылки:
- Русскоязычное QA Load сообщество в Telegram
- База знаний QA Load сообщества
Предыдущие материалы о НТ в Miro:
- Достоверный нагрузочный тест c учетом непредвиденных нюансов (доклад с DUMP-2019)
- Достоверный нагрузочный тест с учётом непредвиденных нюансов
- Управление сотнями серверов для нагрузочного теста: автомасштабирование, кастомный мониторинг, DevOps культура
QA процесс в Miro:
- Качество — ответственность команды. Наш QA опыт
- QA-процесс в Miro: отказ от водопада и ручного тестирования, передача ответственности за качество всей команде
Прочие ссылки:
- Ликбез о том, кто такие QA инженеры и кто такие тестировщики (от Dodo Engineering) — «Кто ты, QA-инженер или тестировщик?»
- Глава про «4 золотых сигнала» в книге по SRE от Google
Просмотров: 8079
Дата последнего изменения: 23.09.2021
Сложность урока:
4 уровень — сложно, требуется сосредоточиться, внимание деталям и точному следованию инструкции.
5
В качестве примера нагрузочного тестирования опишем, как тестируется коробка «Битрикс24».
Описание и цели
Коробочная версия Битрикс24 уже проходила нагрузочное тестирование в 2015 году, и на тот момент были получены очень неплохие результаты. Тестирование продемонстрировало, что продукт, развернутый в компании из 15 тысяч сотрудников, работает стабильно и быстро.
За прошедшее время продукт сильно изменился, получил новые возможности и сценарии. Росло и количество крупных клиентов, появилось много заказчиков из ТОП-100 Forbes/РБК. В последнее время продуктом стали интересоваться действительно очень крупные клиенты с десятками тысяч сотрудников. Только за последние пару лет Битрикс24 был запущен в НЛМК, DNS, СУЭК, Полюс Золото, Почте России, ФК Открытие и многих других.
Одним из ключевых запросов от заказчиков такого уровня является надежность и стабильность в работе, производительность решения. Корпоративные порталы в крупных предприятиях, особенно после начала пандемии, стали понемногу переходить в разряд критических для бизнеса приложений. В них заводятся информационные потоки компании, организуются цифровые сервисы для сотрудников. В целом тенденция последних лет — это превращение интранета в единое корпоративное цифровое пространство для работы и коммуникации тысяч сотрудников.
Стало понятно, что кроме опыта аналогичных внедрений нужны новые подтверждения, что «Битрикс24» может справиться с такими нагрузками. Поэтому был запущен проект нового нагрузочного тестирования.
Партнером по проекту тестирования стала компания Selectel, традиционно предоставляющая оборудование для тестов. Также в работе над тестированием вендору помогали коллеги из QSOFT.
Цели тестирования
- смоделировать работу интранет-портала большой корпорации (100 тысяч сотрудников, большое количество демонстрационных данных);
- обеспечить методику тестирования, максимально близкую к поведению пользователей в реальной жизни;
- продемонстрировать стабильную работу портала без наличия ошибок в случае одновременной работы с порталом трети от всех сотрудников корпорации (не менее 30 тыс.) на доступном оборудовании;
- подтвердить эффективность технологии Веб-кластер в продукте 1С-Битрикс24: Enterprise;
- обеспечить уверенную одновременную работу примерно 1/3 из общего числа сотрудников и среднее время отклика портала в районе 1 секунды (для 95% запросов).
Параметры тестирования
Выделенное оборудование
Оборудование включало в себя физические серверы двух конфигураций:
| Сервер | Процессор | Оперативная память | Жёсткий диск |
|---|---|---|---|
| Базы данных | Intel Xeon W-2255 3.7 ГГц (10 ядер) | 128 ГБ DDR4 | 2 × 960 ГБ NVMe +2 × 8000 ГБ HDD |
| Приложений | Intel Xeon E-2236 / 3.4 ГГц, 6 ядер | 32 ГБ DDR4 | 2 x 480 ГБ SSD |
Был развернут кластер, включающий 2 сервера баз данных и 3 сервера приложений (веб-серверы). Данная конфигурация была выбрана для обеспечения высокой производительности кластера с одновременным обеспечением высокой отказоустойчивости. Схема кластера и его описание приведены в детальном отчете.
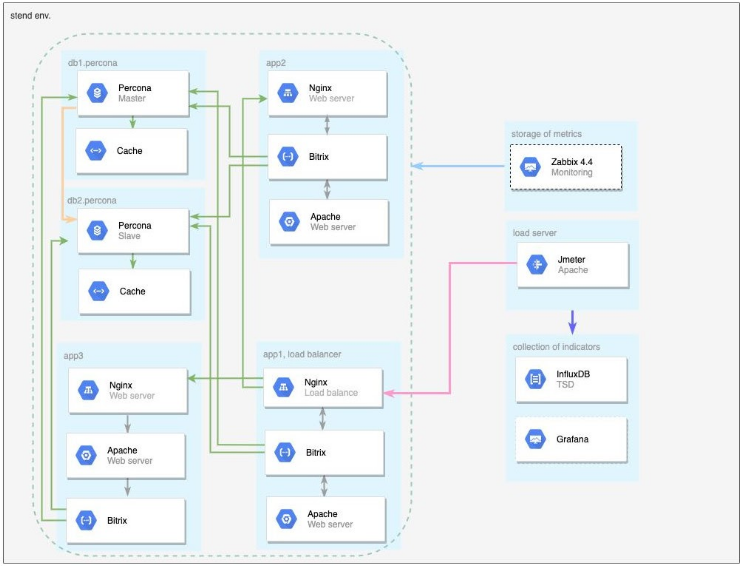
Программное обеспечение
Программное обеспечение серверов было сконфигурировано с помощью продукта «1С-Битрикс: Виртуальная машина». Кластерное решение реализовано на основе технологии Веб-кластер.
Параметры тестового интранет-портала:
- Типовое коробочное решение 1С-Битрикс24: Enterprise, версия 20.x.x с последними обновлениями, задействован модуль «Веб-кластер» для построения кластерного решения
- Демонстрационный контент на момент старта финального теста: 590 тыс. сообщений в живой ленте, 540 тыс. комментариев, 40 тыс. новостей, 180 тыс. задач, 415 тыс. мгновенных сообщений
- Количество сотрудников в базе данных портала на момент старта финального теста: 111 304 (распределены по 67 структурным подразделениям)
Указанное количество пользователей за 1 час генерируют на тестовом портале:
- 39 новостей
- 4 614 сообщений в ленте Новостей
- 4 685 комментариев
- 440 чатов
- 3 386 мгновенных сообщений
- 2 297 заданий бизнес-процессов
- 912 задач
- 367 документов
- 92 рабочие группы и проекта
- 291 встречу в календарях
- 2 385 уведомления
За сутки (24 часа) на таком портале генерируются:
- 936 новостей
- 110 736 сообщений в ленте Новостей
- 112 440 комментариев
- 10 560 чатов
- 81 264 мгновенных сообщения
- 55 128 заданий бизнес-процессов
- 21 888 задач
- 8 808 документов
- 2 208 рабочих групп и проектов
- 6 984 встречи в календарях
- 57 240 уведомлений
Методика генерации нагрузки
Нагрузка создавалась инструментом JMeter версии 5.3.3. Данные теста записывались в
InfluxDB
Высокопроизводительная БД, предназначенная для обработки высокой нагрузки записи и запросов.
Подробнее…
. Для визуализации аналитики использовали приложение Grafana. Мониторинг серверов осуществлялся при помощи системы мониторинга Zabbix.
Для тестирования было выбрано 29 сценариев из 13 блоков, свойственных для типового интранет-портала:
- авторизация,
- живая лента,
- поиск,
- чат (групповой и один на один),
- задачи,
- календарь,
- мой диск,
- новости,
- фотогалерея,
- сотрудники,
- профиль,
- бизнес-процессы,
- рабочие группы.
Для каждого теста были подобраны веса, учитывающие работу различных пользователей на портале и долю каждого из блоков в общей нагрузке.
Была применена новая методика генерации нагрузки от пользователей. Вместо одного виртуального пользователя, перебирающего в случайном порядке типовые цепочки действий, нагрузка генерировалась большим количеством разных пользователей со своей учетной записью на портале. Генератор нагрузки авторизовывал каждого такого пользователя в системе, а затем выполнял под этим пользователем разнообразный набор сценариев. При этом между выполнением каждого нового сценария выполнялось ожидание (от 20 сек до 10 минут). Таким образом, эмулировалось максимально реальное поведение сотрудников предприятия, которые зашли в интранет-портал и работают с ним в течение дня.
Важно отметить, что не преследовалась цель максимизации показателей по сгенерированному контенту на портале за время теста (новостям, задачам, документам, сообщениям и другим). Важнее было обеспечить их соответствие реальной жизни. И тем не менее, скорость добавления информации на портал оказалась также очень высокой, что покрывает потребности многих заказчиков с большим запасом!
Результаты тестирования и сертификат
Демонстрационный портал, развернутый в кластерном решении из 5 серверов, обеспечил одновременную работу 30 тысяч пользователей, а это соответствует примерному профилю нагрузки для крупной корпорации, в которой работает 100 – 200 тысяч сотрудников.
При этом система обеспечила быстрый (даже по меркам интернет-проектов) отклик, для подавляющего большинства запросов не превышающий 1 сек, что, безусловно, делает работу с порталом комфортной для современного пользователя. Технология Веб-кластера вновь подтвердила свою производительность и надежность.
Ссылка на запрос подробного отчета.

 Автор: Кристин Джеквони (Kristin Jackvony)
Автор: Кристин Джеквони (Kristin Jackvony)
Оригинал статьи
Перевод: Ольга Алифанова
Сегодня мы поговорим о нагрузочном тестировании. Нагрузочное тестирование – это способы измерения надежности и скорости вашего приложения во времена повышенного спроса на него. Это может означать тест-сценарии при приемлемой, разумной нагрузке, или же это могут быть тесты на экстремальный стресс, чтобы выяснить пределы возможностей приложения.
Довольно легко найти инструмент нагрузочного тестирования, создать несколько тестов и прогнать их при нагрузке в пару сотен пользователей, чтобы создать метрики. Но это не особенно вам поможет, если вы не знаете, зачем вы это делаете, и чем вам помогут полученные результаты.
Поэтому, прежде чем приступать, важно ответить на следующие вопросы:
- Какие сценарии будут тестироваться?
- Каково ожидаемое поведение в этих сценариях?
Допустим, у вас есть сайт-магазин по продаже коробок шоколада. Вы заметили, что сайт наиболее активен субботним утром. К тому же приближается день святого Валентина, и вы ожидаете, что на неделе перед праздником вы получите повышенное количество заказов. В марте вашу компанию покажут в популярном кабельном ТВ-шоу, и вы надеетесь, что это привлечет тысячи посетителей.
Держа это в уме, вы ожидаете вот какого поведения:
- Страницы сайта должны загружаться за не более чем две секунды под обычной субботней утренней нагрузкой.
- Сайт должен быть способен обрабатывать пятьсот заказов в час – это поможет справиться с загруженным сезоном дня святого Валентина.
- Сайт должен выдерживать десять тысяч посетителей в час – такое количество ожидается сразу после эфира ТВ-шоу.
Следующий шаг – выяснить, какое тест-окружение будет использоваться. Конечно, тестирование в продакшене – это наиболее реалистичное окружение, но нагрузочное тестирование в этих условиях – плохая идея, если результатом станет падение сайта. Следующий наиболее реалистичный вариант – это тест-окружение, которое точно отражает реальное окружение в смысле количества используемых серверов и размера базы данных бэкэнда. Идеальная ситуация – когда тест-окружение используется только для нагрузочного тестирования, но это не всегда возможно; вам может понадобиться делиться этим окружением с другими тестировщиками, и тогда вам надо знать, какие тесты они запускают, и как это может на вас повлиять. Они, в свою очередь, должны знать, когда проводятся ваши нагрузочные тесты, и не удивляться повышенному времени отклика.
Как только тест-окружение подготовлено, можно провести ряд простых тестов, чтобы определиться с базовыми значениями метрик. Тут можно использовать стратегии, упомянутые в статье «Введение в тестирование производительности» и выяснить, как долго грузятся страницы, и каково типичное время ответа ваших API-эндпойнтов. Знание этих чисел поможет вам определить, какой эффект окажет нагрузка.
Теперь настало время проектировать тесты. Здесь можно пользоваться различными стратегиями:
- Можно тестировать индивидуальные компоненты – например, загрузку страницы или единичный запрос к API.
- Можно тестировать целые пользовательские сценарии – просмотр сайта, добавление товара в корзину, оформление заказа.
Возможно, имеет смысл использовать обе стратегии, но не одновременно. Скажем, вы можете замерить, как долго будет грузиться домашняя страница при десяти тысячах запросов этой страницы в час. В отдельном тесте можно создать сценарий, при котором сотни пользователей бродят по сайту, добавляя товары в корзину и делая заказ, и отслеживать результаты на предмет появления ошибок.
Для каждого теста нужно определиться:
- Сколько пользователей будет единовременно взаимодействовать с приложением?
- Будут ли они добавляться единовременно, или постепенно, каждые несколько секунд?
- Будут ли они выполнять одно действие и останавливаться, или же они будут непрерывно повторять его в течение теста?
- Как долго продлится тест?
Давайте создадим тест для сценария «Валентинов день». Предположим, что вы уже создали тест-шаги, загружающие страницу, листающие три продуктовых страницы, добавляющие товар в корзину, и оформляющие заказ. Выше упоминалось, что мы хотим выдерживать пятьсот заказов в час, поэтому на это и будет нацелен наш тест. Вряд ли в реальном мире все пять сотен пользователей начнут заказывать одновременно, поэтому укажем тесту добавлять нового пользователя каждые пять секунд. Каждый пользователь пройдет по сценарию единожды, а затем остановится. Тест будет длиться час, или же до момента, когда все пятьсот пользователей завершат сценарий.
Перед прогоном теста убедитесь, что шаги возвращают ошибки, если не получают ожидаемого результата. Когда я только начинала работать в нагрузочном тестировании, я прогнала несколько тестов с сотнями запросов, прежде чем обнаружила, что все мои запросы возвращали пустоту. Они возвращались со статусом 200, поэтому я и не заметила, что что-то пошло не так! Убедитесь, что ваши шаги убеждаются, что приложение работает именно так, как задумано.
Когда шаги созданы, тест-параметры (количество пользователей, частота их добавления и продолжительность теста) заданы, а вы убедились, что валидация результата в порядке, наступает время прогона! Пока тест запущен, следите за временем ответов и загрузкой процессора. Если пойдут ошибки или всплески загрузки CPU, можно остановить тест и отметить, при какой нагрузке это произошло.
Неважно, надо ли вам остановить тест раньше времени, или он успешно завершен – понадобится несколько прогонов, чтобы убедиться, что результаты соответствуют друг другу. В конце тестирования вы сможете ответить на вопрос, выдержит ли ваше приложение пятьсот заказов в час. Если все заказы прошли без ошибок, а время ответа было приемлемым, то ответ «да». Если вы столкнулись с ошибками, или время ответа увеличилось до нескольких секунд, то ответ «нет». Если ответ «нет», то собранными данными стоит поделиться с разработчиками, чтобы показать, при каком количестве пользователей система начала медленнее работать.
Нагрузочное тестирование – это не то, чем стоит заниматься просто ради того, чтобы поставить галочку «этот тип тестирования покрыт». Потратив время на размышления, какие сценарии нужно замерять, какого поведения вы ожидаете, как именно можно протестировать это поведение, и как анализировать результаты, вы убедитесь, что нагрузочное тестирование – продуктивная и информативная деятельность.
Обсудить в форуме