Лекция 5
Семантические сети.
В бытовом понимании семантика означает
смысл слова, действия, художественного
произведения и т.п. Семантическая сеть
– это граф, вершинам которого сопоставляются
понятия (объекты, процессы, явления),
дуги графа – это отношения между
вершинами. Объект –структура, содержащая
конкретную информацию.
Метки вершин имеют ссылочный характер
и представляют собой некоторые имена.
В роли имен могут выступать, например,
слова естественного языка. Метки дуг
обозначают элементы множества отношений.
В семантических сетях используются три
основных типа объектов: понятия, события,
свойства.
Понятие – это сведения об абстрактных
или физических объектах предметной
области. Общие понятия интерпретируются
как множество параметров или констант.
События – это действия, которые могут
внести изменения в предметную область.
Результатом события является некоторое
новое состояние предметной области.
Можно задать желаемое (целевое) состояние
предметной области и поставить задачу
отыскания в семантической сети
последовательности событий, приводящей
к новому состоянию.
Свойства – используются для уточнения
понятий или событий. Для понятий это
особенности или характеристики (цвет,
размер, качество). Для свойств –
продолжительность, время, место.
Объекты предметной области, отображаемые
в семантической сети, можно разделить
на три группы: обобщенные, индивидные
(конкретные) и агрегатные.
Обобщенный объект соответствует
некоторой собирательной абстракции
реально существующего объекта, процесса
или явления предметной области. Например,
«изделие», «предприятие», «сотрудник»
и т.п. Обобщенные объекты фактически
представляют определенные классы
предметной области.
Индивидный объект – это каким-то
образом выделенный единичный представитель
(экземпляр) класса. Например, «сотрудник
Петров» И.Н.».
Агрегатным называется составной
объект, образованный из других объектоа,
которые рассматриваются как его составные
части. Например, изделие состоит из
совокупности деталей, предприятие
состоит из совокупности отделов, служб,
цехов.
Введенная классификация является
относительной. В зависимости от решаемой
задачи один и тот же объект может
рассматриваться как обобщенный или
индивидный, как агрегатный или
неагрегатный.
Возможные отношения в семантических
сетях (не полный список):
Агент – это то, что (тот, кто) вызывает
действие. Агент часто является подлежащим
в предложении. Например, «Иванов ударил
мяч».
Объект – это то, на что (на кого)
направлено действие. В предложении
объект часто выполняет роль прямого
дополнения. Например, «Робот взял
пирамиду».
Инструмент – это средство, которое
используется агентом для выполнения
действия. Например, «Иванов открыл дверь
с помощью ключа».
Соагент – служит как подчиненный
партнер главному агенту. Например,
«Иванов сдал экзамен с помощью Петрова».
Пункт отправления и пункт назначения
– это отправная и конечная позиция при
перемещении агента или объекта. Например,
«Робот переместился от одного станка
к другому».
Траектория – это перемещение от
пункта отправления к пункту назначения.
Например, «Они прошли через дверь по
ступенькам на лестницу».
Средство доставки – то в чем или на
чем происходит перемещение. Например,
«Иванов всегда едет домой на машине».
Местоположение – то место, где
произошло (происходит, будет происходить)
действие. Например, «Он работал за
столом».
Потребитель – то лицо, для которого
выполняется действие. Например, «Иванов
собрал шпаргалки для Кати».
Сырье – это, как правило, материал
из которого что-то сделано или состоит.
Обычно сырье вводится предлогом из.
Например, «Иванов собрал робот из
интегральных схем».
Время – указывает на момент совершения
действия. Например, «Он закончил работу
поздно вечером».
Под фактом понимают конкретизацию
определенного отношения между объектами.
В графической интерпретации факт – это
подграф семантической сети, имеющий
звездообразную структуру. Корень
подграфа – вершина предикатного типа,
помеченная уникальной меткой, включающей
имя соответствующего отношения. Из
вершины факта выходят ребра, помеченные
именами атрибутов данного факта, ведущие
в вершины базового множества, которые
являются значениями этих атрибутов.
Иногда удобна табличная форма записи
фактов.
Например:
|
Метка факта |
Отношение «меньше» |
|
1 |
|
|
F1 F2 F3 |
1 2 0 2 |
Отношения могут быть самого роапзличного
вида, но чаще всего применяются следующие
основные связиP: «род-вид».
«является представителем». «является
частью». Наличие связи типа «род-вид»
между обобщенными объектами А и В
означает, что понятие А более общее, чем
понятие В. Любой объект, отображаемый
понятием В, отображается и понятием А,
но ге наоборот. Например, понятие
«предприятие» — это родовое понятие для
объекта «цех».
Связь «является представителем»
существует обычно между обобщенным и
индивидным объектом, когда индивидный
объект выступает в роли представителя
некоторого класса. Так, индивидный
объект «овчарка Альма» является
представителем обобщенного объекта
«овчарка».
Иерархические отношения между объектами
системы имеют двусторонний характер:
«сверху-вниз» и «снизу-вверх». Отношение
«снизу-вверх» — это отношение типа
«это-есть» (англ. – is-a).
Например, скорость — это-есть
кинематическая величина, кинематическая
величина – это-есть механическая
величина, механическая величина –
это-есть физическая величина.
Отношения «сверху-вниз» — это отношения
типа «одним-из» (англ.kind-of).
Например, «одним-из» видов физических
величин есть механические величины,
«одним-из» видов механических величин
есть кинематические величины, «одним-из»
видов кинематических величин есть
скорость.
В ряде случаев между связями «род-вид»
и «является представителем» не делают
различий, отмечая, что эти связи задают
отношение «общее-частное», используя
для формализации таких связей отношения
АКО и is-a.
Не менее важно отношение «является
частью» (англ. part of).
Данное отношение связывает агрегатный
объект с его составными частями. Оно
позволяет отражать в базе знаний
структуру объектов предметной области.
Иногда данное отношение обозначают
меткой «имеет». Такие отношения являются
отношениями по горизонтали.
Такие отношения окружают нас повсеместно.
В целое могут быть объединены самые
разнообразные части. Известно, что
многие объекты состоят из частей и могут
быть расчленены на части. Но при этом
существует общее свойство, заключающееся
в том, что целое обладает признаками,
которыми не обладает ни одна из его
частей. Из частей состоит работающий
двигатель, движущийся автомобиль и т.п.
Вышесказанное в полной мере относится
и к знаниям.
Пример семантической сети (рис.10):
Поставщик осуществил поставку изделий
по заказу клиента до 1 июня 2008 г. в
количестве 1000 шт.

Рис.10. Пример семантической сети.
Каким же образом осущкствляется вывод
на семантических сетях? Мощным средством
вывода в семантических сетях является
сопоставление с образцом. В данном
случае происходит сопоставление
отдельных фрагментов сети. При этом
запрос к базе знаний представляется в
виде автономного подграфа, который
строится по тем же правилам, что и
семантическая сеть. Поиск ответа на
запрос реализуется сопоставлением
подграфа с фрагментами семантической
сети. Для этого осуществляется наложение
подграфа запроса на соответствующий
фрагмент сети. Успешным будет то
наложение, в результате которого фрагмент
сети оказывается идентичным подграфу
запроса. При этом допускается использование
в запросе переменных. Переменная запроса
сопоставляется с константой фрагмента
сети.
Поиск в семантической сети (рис.11): Какой
объект находится на желтом блоке?

Рис.11. Поиск в семантической сети.
Совместив запрос с сетью получим ответ
– пирамида.
Классификация сетей.
По структуре:
Сети простого типа – у которых вершины
не имеют собственной внутренней
структуры.
Однородные сети – при одинаковых
отношениях между вершинами.
Сети иерархического типа – таким сетям
свойственны структуры с вершинами
разного ранга, имеющими разный уровень
или подчиненность от низших к высшим.
По характеру отношений, приписываемых
дугам сети:
Функциональные сети. Дуги отражают тот
факт, что вершина, из которой выходит
дуга, играет по отношению к вершине,
куда идет дуга, роль аргумента. Описания,
соответствующие вершине – функции,
задают процедуру нахождения результата.
Сценарии – однородные сети, в которых
в качестве единственного отношения
выступает отношение нестрогого порядка
(например, отношение «не раньше, чем»),
которое допускает одновременность.
Чаще всего эти отношения определяют
все возможные последовательности
событий.
Семантические сети делятся на
интенсиональные и экстенсиональные.
Интенсиональная сеть содержит
интенсиональные знания и описывает
общую структуру модернизируемой
предметной области на основе абстрактных
объектов и отношений, т.е. обобщенных
представителей некоторых классов
объектов и отношений. Например, такие
объекты как производственный участок,
груз, деталь могут являться обобщенными
понятиями множества значений от которых
образуется множество имен конкретных
производственных участков (токарный,
прессовый и т.п.), множество имен грузов
(заготовка, кассета), множество классов
деталей (болт, вал, гайка и т.п.).
Экстенсиональная семантическая сеть
описывает экстенсиональные знания о
модернизируемых объектах, являясь как
бы «фотографией» его текущего состояния.
Интенсиональная сеть предложения «Робот
сверлит отверстие в детали сверлом
диаметром 10 мм (рис. 12).
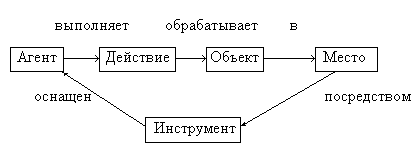
Рис. 12. Интенсиональная сеть.
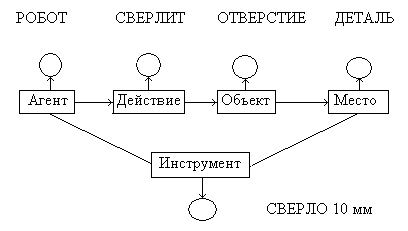
Рис.13. Экстенсиональная сеть.
Семантические отношения делят на четыре
класса: лингвинистические, логические,
теоретико-множественные и квантифицированные.
Лингвинистические отношения –
наиболее употребительные – падежные,
к которым относятся , в частности,
следующие: агент – отношение между
событием и тем кто (что) его вызывает;
объект – отношение между событием и
тем, над чем производится действие;
условие – отношение, указывающее
логическую зависимость между событиями;
инструмент – объект, с помощью которого
совершается событие; место – место
совершения события. Другой тип
лингвинистических отношений – это
характеризация глаголов и атрибутивных
отношений. К характеризации глаголов
относятся наклонение, время, род, число,
залог. Атрибутивные отношения – цвет,
форма, размер. Например: фраза «Большие
красные шары» с использованием
атрибутивных отношений может быть
представлена структурой, изображенной
на рис.14..
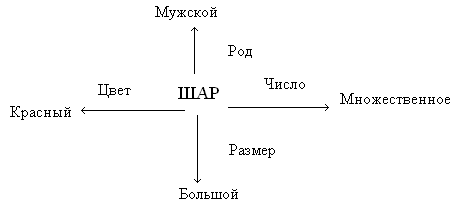
Рис.14. Фраза «большие красные шары»
Логические отношения представляют
собой операции алгебры логики..
Теоретико-множественные – это
подмножество, супермножество, элемент
множества, отношение части и целого и
др. Этот класс отношений используется
для построения иерархических соподчиненных
структур, для представления обобщенной
информации (рис.15).
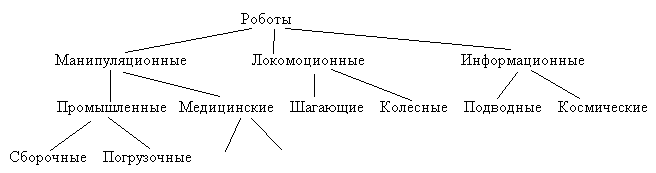
Рис.15. Иерархия классификации роботов.
Квантифицированные отношения –
это логические кванторы общности и
существования. Логические кванторы
применяются для представления знаний
декларативного типа. Например: «каждый
станок требует профилактического
ремонта», «Существует робот А, который
может обслуживать станки группы В».
Важным понятием в семантических сетях
является десигнат – уникальное
внутрисистемное имя, которое ставится
в соответствие некоторому объекту в
предметной области, если о нем в данный
момент времени нет полной информации.
Например, «Станок С1 имеет накопитель».
Это предложение имеет неопределенность
относительно характеристик накопителя.
По мере поступления информации будут
уточняться емкость накопителя и другие
данные.
(F1: имеет агент Станок
объект D1)
(D1: имя накопитель)
(D1: габарит ______)
(D1: емкость _______)
F1 – метка факта, D1
– метка десигната.
В момент первого напоминания вводится
информация, которая используется в
дальнейшем. В семантических сетях
информация может представляться в
фреймовом виде..
При построении интеллектуальных банков
данных на основе семантических сетей
основным принципом их организации
является разделение экстенсиональных
и интенсиональных знаний, при этом
экстенсиональные семантические сети
являются основой базы данных, а
интенсиональные сети – основой базы
знаний (рис.16).
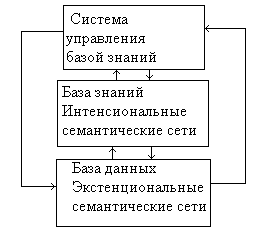
Рис.16. Формирование интеллектуальных
банков на основе сетей.
Частным случаем семантических сетей
являются сценарии, или однородные
семантические сети. Сценарий – это
структурированное представление,
описывающее стереотипную последовательность
событий в частном контексте. Сценарии
используются в системах понимания
естественного языка для организации
базы знаний в терминах ситуаций, которые
система должна понимать. Объекты в этих
сетях связаны единственным отношением
строгого или нестрогого порядка с
различной семантикой(например,
«причина-следствие», «цель-подцель»,
«часть-целое»). Каждая последовательность
действий в сценах обладает свойством
казуальных цепочек: всякое предшествующее
действие создает условия для последующего
действия.
Сценарий включает следующие компоненты:
Начальные условия, которые должны быть
истинными при вызове сценария.
Результаты или факты, которые являются
истинными, когда сценарий завершается.
Предположения, которые поддерживают
контекст сценария. Множество предположений
описывают принятые по умолчанию условия
реализации сценария.
Роли являются действиями, которые
совершают отдельные участники сценария.
Сцены. Сценарий состоит из последовательности
сцен, каждая из которых представляет
временные аспекты сценария.
Сценарии рассматриваются как средство
представления проблемно-зависимых
казуальных знаний и задаются в виде
фреймоподобных списочных структур.
сценарий: название
роли: список участников сценария.
цель: ключевое событие сценария, посылки
и следствия ключевого события..
Сцена 1:наименование сцены
(ход сцены)
Сцена 2:наименование сцены
(ход сцены)
Сцена 3:наименование сцены
(ход сцены)
……………………..
Сцена N:наименование сцены
(ход сцены)
Особенности представления знаний в
семантических сетях состоят в следующем:
— в семантической сети могут быть
представлены такие виды объектов как
понятия, события, специализированные
методы решения. Увеличение номенклатуры
объектов снижает однородность сети и
приводит к необходимости увеличения
набора механизмов и методов вывода.
— многомерность семантических сетей
позволяет представить в них сложные
семантические отношения, связывающие
отдельные понятия, понятия и события в
предложении, а также предложения в
текстах.
— на каждой стадии формирования решения
можно четко разделить полное знание
системы (полная семантическая сеть) и
текущее знание – возбуждаемый участок
сети, в котором производятся некоторые
операции (процесс вывода, понимания и
т.п.).
Известны многие варианты семантических
сетей, общие характеристики которых
сводятся к следующему:
— описание объектов предметной области
происходит на уровне естественного
языка;
— все знания, включая вновь поступающие
факты, а также специализированные методы
решения, накапливаются в относительно
однородной структуре памяти;
— определяется ряд более или менее
унифицированных семантических отношений
между объектами, которым ставятся в
соответствие унифицированные методы
вывода;
— запросы вместе с методами вывода
определяют участки знания (семантической
сети), имеющие отношение к поставленной
задаче, фиксируя тем самым понимание
запроса и вытекающую из него цепь
выводов, соответствующих решению задачи;
выводы в семантических сетях отличаются
значительной полнотой.
Управление выводом.
Механизм вывода использует особый метод
генерации выводов, так называемый «метод
распространяющейся активности и техники
пересечений». Процесс осуществляется
построением на основе введенных
высказываний цепочек возможных выводов
во всех направлениях до тех пор, пока в
сети не обнаружится пересечение или не
найден фрагмент, отражающий поставленный
запрос к базе знаний. Недостаток –
сложность организации процедуры вывода.
Область применения семантических сетей
– системы обработки естественного
языка, системы технического зрения и
другие.
Пример составления семантической
сети.
Предложение: Если станок закончил
обработку, робот грузит кассету с
деталями на робокар, который перевозит
их на склад, где штабелер помещает
кассету в ячейку.
Выделяем факты (факт – конкретизация
отношений между объектами).
F1 – станок закончил
обработку;
F2 – робот грузит;
F3 – робокар перевозит;
F4 – кассета содержит;
F5 – штабелер размещает.
Обозначаем факты кружками, а связанные
с ними события – прямоугольниками. Дуги
помечаем наименованиями отношений,
которые они выражают рис.17).
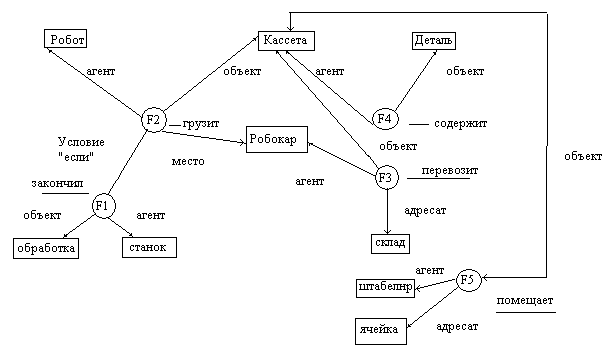
Рис.17. Пример семантической сети.
Запрос можно представить графом,
в котором вершины, соответствующие
некоторым переменным, не определены.
Запрос: Оператор сообщил, что робокар
что-то перевозит. Определить, что и как
перевозит робокар (рис.18).
Факт сообщил
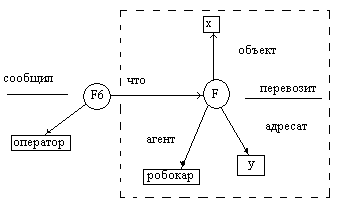
Рис.18. Пример подграфа.
Вложив этот подграф в семантическую
сеть (совместив с F3) получим
конкретные ответы: х – кассета, у –
склад. Ответ будет выглядеть так:
робокар перевозит кассету на склад.
Таким образом:
-
семантические сети описывают отношения
между объектами, которые задаются
узлами сети; -
узлы обозначаются окружностями и имеют
имена; -
отношения между узлами указываются
связывающими их линиями; -
семантические сети можно использовать
для создания структур или объектов; -
семантические сети можно использовать
для создания правил баз знаний.
|
|
|


So he went down to the agora, or marketplace, where there were a lot of unemployed philosophers—which means philosophers which were not thinking at that time.
Thought—in other words, philosophers can tell you millions of things that thought isn’t, and they can’t tell you what it is—and this bugs them!
—Severn Darden, Lecture on Metaphysics
In the beginning, there was no Web. The Web began as a concept of Tim Berners-Lee, who worked for CERN, the European organization for physics research. CERN’s technical staff urgently needed to share documents located on their many computers. Berners-Lee had previously built several systems to do that, and with this background, he conceived the World Wide Web. The design had a relatively simple technical basis, which helped the technology take hold and gain critical mass.
Berners-Lee wanted anyone to be able to put information on a computer and make that information accessible to anyone else, anywhere. He hoped that eventually, machines would also be able to use information on the Web. Ultimately, he thought, this would allow powerful and effective human-computer-human collaboration:
I have always imagined the information space as something to which everyone has immediate and intuitive access, and not just to browse but to create… Machines become capable of analyzing all the data on the Web—the content, links, and transactions between people and computers.
…when [the Semantic Web] does [emerge], the day-to-day mechanisms of trade, bureaucracy, and our daily lives will be handled by machines talking to machines, leaving people to provide the inspiration and intuition. (Berners- Lee 2000)
I find this vision inspiring, and the means to get there intriguing. The Semantic Web has, in a way, become almost a celebrity—Scientific American has even published an article on it (Berners-Lee, Hendler, and Lassila 2001)—although most people don’t know what it is, and although there really isn’t a Semantic Web yet. There are many different ideas of what it is, not just one. In this chapter, we examine a range of ideas about what the Semantic Web should be. Some of them may seem futuristic or impractical, but a great deal of work is going on in all the areas we’ll examine.
1.1 What is the Semantic Web?
The word semantic implies meaning or, as WordNet defines it, “of or relating to the study of meaning and changes of meaning”. For the Semantic Web, semantic indicates that the meaning of data on the Web can be discovered—not just by people, but also by computers. In contrast, most meaning on the Web today is inferred by people who read web pages and the labels of hyperlinks, and by other people who write specialized software to work with the data. The phrase the Semantic Web stands for a vision in which computers—software—as well as people can find, read, understand and use data over the World Wide Web to accomplish useful goals for users.
Of course, we already use software to accomplish things on the Web, but the distinction lies in the words we use. People surf the Web, buy things on web sites, work their way through search pages, read the labels on hyperlinks, and decide which links to follow. It would be much more efficient and less time-consuming if a person could launch a process that would then proceed on its own, perhaps checking with the person from time to time as the work progressed. The business of the Semantic Web is to bring such capabilities into widespread use.
In brief, the Semantic Web is supposed to make data located anywhere on the Web accessible and understandable, both to people and to machines. This is more a vision than a technology. In this book, we’ll explore the technologies that will play roles in bringing the vision to life.
As you might expect, there are many different ideas about what this general vision encompasses. An almost overwhelming number of different ideas exists about the supposed nature of the Semantic Web, and that’s the first lesson to learn: The Semantic Web is a fluid, evolving, informally defined concept rather than an integrated, working system. To give you a feel for this range of ideas, here are some representative quotations about the nature of the Semantic Web:
- The machine-readable-data view — “The Semantic Web is a vision: the idea of having data on the Web defined and linked in a way that it can be used by machines not just for display purposes, but for automation, integration and reuse of data across various applications.” (W3C 2003)
- The intelligent agents view — “The aim of the Semantic Web is to make the present Web more machine-readable, in order to allow intelligent agents to retrieve and manipulate pertinent information.” (Cost et al 2001)
- The distributed database view — “The Semantic Web concept is to do for data what HTML did for textual information systems: to provide sufficient flexibility to be able to represent all databases and logic rules to link them together to great added value.” (W3C 2000) “A simple description of the Semantic Web is that it is an attempt to do for machine processable data what the World Wide Web did for human readable documents. Namely, to transform information processing by providing a common way that data can be accessed, linked together and understood. To turn the Web from a large hyperlinked book into a large interlinked database.” (SWAD-E)
- The automated infrastructure view — “In his recent Scientific American article, Berners-Lee argues that the Semantic Web is infrastructure and not an application. We couldn’t agree more.” (Tuttle et al 2001) “Therefore, the real problem is the lack of an easy automation framework in the current Web…” (Garcia and Delgado 2001)
- The servant-of-humanity view — “The vision of the Semantic Web is to let computer software relieve us of much of the burden of locating resources on the Web that are relevant to our needs and extracting, integrating, and indexing the information contained within.” (Cranefield 2001) “The Semantic Web is a vision of the next-generation web, which enables web applications to automatically collect web documents from diverse sources, integrate and process information, and interoperate with other applications in order to execute sophisticated tasks for humans.” (Anutariya et al 2001)
- The better-annotation view — “The idea of a ‘Semantic Web’ [Berners-Lee 2001] supplies the (informal) web, as we know it, with annotations expressed in a machine-processable form and linked together.” (Euzenat 2001)
- The improved-searching view — “Soon it will be possible to access Web resources by content rather than just by keywords.” (Anutariya et al 2001) “The main goal [of the technology described in the paper] is to build a structured index of the Web site.” (Desmontils and Jacquin 2001)
- The web services view — “Increasingly, the Semantic Web will be called upon to provide access not just to static documents that collect useful information, but also to services that provide useful behavior.” (Klein and Bernstein 2001)
“The Semantic Web promises to expand the services for the existing web by enabling software agents to automate procedures currently performed manually and by introducing new applications that are infeasible today.” (Tallis, Goldman, and Balzer 2001)
It’s clear that this notion of the Semantic Web covers a lot of ground, and perhaps no two people have quite the same idea about it. Still, several themes are expressed time and again:
- Indexing and retrieving information
- Meta data
- Annotation
- The Web as a large, interoperable database
- Machine retrieval of data
- Web-based services
- Discovery of services
- Intelligent software agents
Let’s look more closely at these themes.
1.1.1 Indexing and retrieving information
Everyone wrestles with how to find information. Libraries have card catalogs, and now many have electronic indexes. Search engines are vital components of the Web. Yet at some point, everyone has been frustrated and annoyed by how hard it is to locate things, especially when you aren’t sure what to ask for. To find information, a Semantic Web approach would expect to go beyond keyword and alphabetical indexes to let users search by concepts and categories.
The Web part brings in a persistent theme, in which information is distributed— spread throughout the Web—rather than concentrated in a few repositories. Most systems that use concept identification to retrieve information maintain their own concept hierarchies and attempt to identify those concepts in the documents they index. Sometimes, concepts in a document collection are identified automatically, with varying success. To go further requires that documents be able to declare their own vocabularies and sets of concepts and to identify where they’re used.
1.1.2 Meta data
Card catalogs and electronic indexes contain data about the works that are cataloged and indexed. Data about other data is often called meta data. For example, the ISBN number and the author’s name are meta data about a novel. The data types describing the data in a database also fall into the category of meta data. It’s even possible to have meta meta data (a statement about the origin of a piece of meta data could be considered to be meta data about meta data, or meta meta data).
In one sense, meta data is still data; the distinction lies in the intended use of the data and in the subject of the meta data. It’s meta data that will be used for searches and for discovery of information. Annotation can also be thought of as meta data.
1.1.3 Annotation
In the world of physical documents (such as books), people write margin notes and comments, they underline and highlight passages, they staple new items to reports, and they add thoughts and ideas to those of the original authors. Markup languages like XML should, you’d think, be able to add such annotations; but today, it’s hard to do this in a simple way that lets other people share your annotations and lets you move your annotations to other applications and computers. Wiki-style web sites attempt to let many people comment on and modify web pages, but this process covers only a little of what people would like to do.
Because annotations should be shareable, and because the meaning of different types of annotations should be widely understood, support for extensive annotation capabilities is often seen as part of the Semantic Web.
1.1.4 A huge interoperable database
Today, it’s common to get data from a database over the Web. These databases are generally separate and not easily used as merged data sources, and a great deal of data exists outside of databases. This part of the Semantic Web vision sees ways to unify the description and retrieval of stored data, allowing much of the Web to be considered part of a large virtual database.
Consider a sports researcher looking for baseball data. There are various online baseball databases: The Major League Baseball web site is but one of many. But if our researcher wants to find performance statistics for Stan Musial, whose career lasted from the 1940s to the 1960s, she can’t get data for the whole period in a mutually compatible format. At least for baseball statistics, there is some common agreement on the definitions of the most important statistics, so that a batting average is always computed the same way—this is more than can be said for most separate collections of data.
If the Web functioned as an interoperable database, the researcher could get the data from all the important sites, and the researcher’s software would be able to either display all the data together or automatically combine data from, say, the Major League Baseball site and the Baseball Almanac.
1.1.5 Machine retrieval of data
This part of the vision focuses on automatic acquisition of data. This means that, a piece of software, in pursuit of its assignment, determines what data it needs and where and how to get it, and then goes out and gets the data. Using the baseball example from the previous section, suppose our researcher has to find the right web pages, load them, and then figure out a way to get the data and organize it. This is hard to do and often takes a lot of time. Under the Semantic Web, the data format and its manner of access would be described in a way that would allow the researcher’s computer to get and use the data automatically.
1.1.6 Services
A service is a behavior that provides a benefit. Examples include making reservations, arranging schedules, providing prices, placing orders, and so forth. Think of ordering, say, a perishable item like flowers or food. Once you’ve selected a product to buy, you have to make sure that its delivery will fit into your schedule. The price, buying conditions, delivery options, and your schedule can all be thought of as services that must be activated and coordinated. In the “Semantic Web as web services” view, all these services would publish machine-readable data that would allow a computer to do all the activation and coordination for you.
1.1.7 Discovery
To use services, you (and especially your software) must be able to find them, discover what they do, and learn how to invoke them. This is the realm of discovery of services. The most obvious approach would be to create directories of services with standard access methods. The services would be described in standard terms, and information about how to access them and the available information would be encoded in standard ways.
Consider an analogy with a physical library. Most libraries in the United States use either the Dewey Decimal System or the Library of Congress method to catalog their books. After using the card catalog or its electronic version, a person becomes familiar with the classifications and learns how to find books on the shelves. Here, the standard access methods are the familiar classification system and the physical arrangement of books in the library.
A more advanced approach would be to send out discovery requests based on the services required, and for candidate services to describe their capabilities in such a way that the would-be user could deduce their capabilities and instigate a conversation to find any missing or uncertain information. Returning to the library example, this would be like getting an experienced research librarian to tell you which reference books to look at and how to understand the information in them.
1.1.8 Intelligent agents
An agent is someone or something that acts on your behalf. A software agent would act in a somewhat autonomous way, communicating with other software agents (which might be specialized) to discover services, products or information for you. For instance, one of those specialized agents might know how to purchase airline tickets and make reservations. Another agent might perform the required services, passing the results back to your own agent, which would notify you of the outcome. It’s clear that a network of interacting agents would have to be able to describe its goals using established vocabularies, to discover services and information resources, and to use many of the capabilities described in the previous sections.
1.2 Two Semantic Web scenarios
To give you a feel for the way these areas might interact and how the Semantic Web could provide great value, here are two scenarios that were developed during the workshop “Research Challenges and Perspectives of the Semantic Web”.1 Both scenarios illustrate what might be called personal services. Of course, similar scenarios could be constructed for many other areas, such as business-to-business transactions. Note that the language is taken directly from the report without corrections for grammatical and spelling errors.
Scenario 1: A research assistant
During her stay at Honolulu, Clara ran into several interesting people with whom she exchanged vCards. When time to rest came in the evening, she had a look at her digital assistant summarizing the events of the day and recalling the events to come (and especially her keynote talk of the next day). The assistant popped up a note with a link to a vCard that reads: “This guy’s profile seems to match the position advertisement that Bill put on our intranet. Can I notify Bill’s assistant?”
Clara hit the “explain!” button. “I used his company directory for finding his DAML2 enhanced vita: he’s got the required skills as a statistician who led the data mining group of the database department at Montana U. for the requirement of a researcher who worked on machine learning.” Clara hit then the “evidence!” button. The assistant started displaying “I checked his affiliation with University of Montana, he is cited several times in their web pages: reasonably trusted; I checked his publication records from publishers’ DAML sources and asked bill assistant a rating of the journals: highly trusted. More details?”
Clara had enough and let her assistant inform Bill’s.
1 This workshop was organized by the European Consortium in Informatics and Mathematics (ERCIM) for the European Union Future Emergent Technology program (EU-FET) and the US National Science Foundation (NSF). It was held in Sophia-Antipolis, France, in October 2001.
2 DARPA Agent Markup Language; see chapter 7.
Scenario 2: Negotiating a date
Bill’s and Peter’s assistants arranged a meeting in Paris, just before ISWC3 in Sardinia. Thanks to Peter’s assistant knowing he was vegetarian, they avoided a faux pas. Bill was surprised that Peter was able to cope with French (his assistant was not authorized to unveil that he married a woman from Québec). Bill and Peter had a fruitful meeting and Bill will certainly be able to send Peter an offer before he came back to the US.
Before dinner, Peter investigated a point that bothered him: Bill used the term “Service” in an unusual way. He wrote: “Acme computing will run the trust rating service for semanticweb.org” (a sentence from Bill). His assistant found no problem, so he hit: “service”, the assistant displayed “service in {database} equivalent To: infrastructure”. Peter asked for “metainfo”, which raised “Updated today by negotiating with Bill’s assistant”.
Peter again asked for “Arguments!”: “Service in {database} conflicts with service in {web}”. “Explain!” “In operating system and database, the term services covers features like fault-tolerance, cache, security, that we are used to putting in the infrastructure. More evidence?” Peter was glad he had not to search the whole Web for an explanation of this. The two assistants detected the issue and negotiated silently a solution to this problem. He had some time left before getting to the théatre de la ville. His assistant made the miracle to book him a place for a rare show of Anne-Theresa De Keermaeker’s troupe in Paris. It had to resort to a particular web service that it found through a dance-related common interest pool of assistants.
3 Presumably the International Semantic Web Conference.
In these scenarios, you can see quite a few Semantic Web areas in operation at the same time. Software agents (the digital assistants) are discovering meta data and information and processing it. Logical reasoning is not only used to make inferences, it’s also explained to the human user. Assessments of trust and reliability are deduced through networks of interacting information. We see the discovery of web services. It all seems so plausible and so useful.
1.2.1 Can the Semantic Web work this way?
What needs to be developed, what needs to be in place, for the Semantic Web to work as envisioned in the previous scenarios? The keys are the widespread interchange of data and ways to mark, indicate, or describe what that data is, how it’s structured, how it can be retrieved, and what it means. Each of these areas is a large undertaking in itself. But the Semantic Web will be a sociological development, too. Companies must cooperate where they might normally compete; academic research must be translated into practical systems; individuals must discover how they can contribute; and issues of for-profit versus free, of closed versus open systems, and of trust need to be worked out.
The task is much bigger than the building of the original World Wide Web. At that time, few people realized how many new capabilities the Web would unleash. Today, some of the basic infrastructure is already in place. There are organizations like the World Wide Web Consortium (W3C), whose purpose includes developing and advancing standards of importance to the Internet as a whole, including the Semantic Web. So the task is bigger, but the starting point is more advanced.
Can the visions be realized? Opinions vary—mine is that many of them will come to pass (some are already beginning to operate) and make a real difference in the lives of people who use the Web.
1.3 The Semantic Web’s foundation
The World Wide Web has certain design features that make it different from earlier hyperlink experiments. These features will play an important role in the design of the Semantic Web. The Web is not the whole Internet, and it would be possible to develop many capabilities of the Semantic Web using other means besides the World Wide Web. But because the Web is so widespread, and because its basic operations are relatively simple, most of the technologies being contemplated for the Semantic Web are based on the current Web, sometimes with extensions. However, web services (chapter  and agents (chapter 9) may step outside the architecture of the current Web, as you’ll see.4
and agents (chapter 9) may step outside the architecture of the current Web, as you’ll see.4
The Web is designed around resources, standardized addressing of those resources (Uniform Resource Locators and Uniform Resource Indicators), and a small, widely understood set of commands. It’s also designed to operate over very large and complex networks in a decentralized way. Let’s look at each of these design features.
4 I’m referring in part to the so-called REST (Representation State Transfer) architecture and the controversy over whether current SOAP-based web services that don’t use this model would be better suited to the Web if they did.
1.3.1 Resources
The Web addresses, retrieves, links to, and modifies resources. A resource is intended to represent any idea that can be referred to. Usually, we think of these resources as being tangible packages of data (documents or pages), but the notion of a resource is more general in two ways. First, a resource can change over time and still be considered the same resource, addressed by the same Uniform Resource Identifier (URI). Thus, a series of drafts of a manuscript could be addressed by the same URI. Alternatively, a URI could denote one specific, unchanging version of the same document. The notion of resource is flexible enough to encompass both varying and fixed resources.
Strictly speaking, a resource itself is not retrieved, but only a representation of the resource. For some protocols, like File Transfer Protocol (FTP), the representation is normally a copy of a file. For others, like HTTP, the representation may or may not be a copy of a file. A resource can even be represented by different forms—a PDF file, an HTML page, a voice recording, and so on.
Second, and perhaps harder to grasp, a resource can be something that doesn’t yet exist, and that may never exist. A resource can be a concept or a reference to a real or fictitious person—something that can’t be addressed and transferred over a network, but that can be talked about, thought about. For the purposes of the Semantic Web, such a resource can be referred to or identified by a URI.5
5 For example, RFC 1737, “Functional Requirements for Uniform Resource Names” (a subset of URIs), says, “The purpose or function of a URN is to provide a globally unique, persistent identifier used for recognition, for access to characteristics of the resource or for access to the resource itself.” (Emphasis added.)
1.3.2 Standardized addressing
All resources on the Web are referred to by URIs. The most familiar URIs are those that address resources that can be addressed and retrieved; these are called URLs, for Uniform Resource Locators. These URIs have a uniform structure that can refer to the use of other protocols besides HTTP (like FTP), and they are easy to type and copy. They can be inserted into hyperlinks so that any addressable information can be easily linked.
1.3.3 Small set of commands
The HTTP protocol (the protocol used to send messages back and forth over the Web) uses a small set of commands. These commands are universally understood by web servers, clients (like browsers), and intermediate components like caches-which can reduce network traffic by storing copies of documents that were previously sent. With this limited set of commands, there is no question about what is being requested of the server and network, and no visibility into how the server may choose to carry out the requests. This model doesn’t provide security or personal privacy for the information being sent or requested; but, since it is simple and well understood, the model lends itself to the provision of additional layers of security.6
However, some architectures use complex messages or need to restrict the visibility of message contents, and they use an approach that’s more involved than basic HTTP. Other Internet protocols can be used, and additional messaging layers can be carried over HTTP as well (such as SOAP, whose name no longer stands for anything). There is some controversy over what methods should be used for the Web—as distinct from the Internet, which includes much more than the World Wide Web—and whether the Semantic Web architecture should restrict itself to the simpler architecture of the current Web.
6 There is some controversy over whether the web model supports security provisions better than other network architectures such as Remote Procedure Call (RPC) systems.
1.3.4 Scalability and large networks
The Web has to operate over a very large network with an enormous number of web sites and to continue to work as the network’s size increases. It accomplishes this, thanks to two main design features. First, the Web is decentralized. If you have a computer on the network, you can put a web server on it; and if you have a server, you can add resources to it without registering them anywhere else.
Second, each transaction on the Web (that is, a request and the subsequent response) contains all the information needed to handle the request. No data needs to be stored by the server from one request to another. However, many practical uses of the Web do require that some data be saved for a period of time. If you reserve a ticket and then order it on another web page, the system must store your ticket reservation and be able to connect it to your request to purchase. Since any web transaction is separate from all others, it’s harder to arrange to maintain data across a connected series of transactions. Independent interactions make possible a large, decentralized system where responses can be cached to allow faster responses and reduce network traffic.
Data that maintains some history of transactions is sometimes called state, as in “the state of the system”. Web transactions are stateless.7 If there is a business need to store information across several interactions, the server must provide special arrangements to make it happen.
7 When a cookie is stored on your computer, the cookie stores some state information. Unfortunately, this state doesn’t fit the web model well, so it can sometimes cause confusion between browser, server, and user.
1.3.5 Openness, completeness, and consistency
The Web is open, meaning that web sites and web resources can be added freely and without central controls. The assignment of domain names to servers does need some central authority to avoid duplicate names,8 but this in no way restricts your ability to establish web servers and the information they provide.
The Web is incomplete, meaning there can be no guarantee that every link will work or that all possible information will be available. It can be inconsistent: anyone can say anything on a web page, so different web pages can easily contradict each other. Information on the Web will never be fully consistent, and it also changes constantly. Just think of all the web pages you’ve returned to that changed since you last visited them, or that don’t even exist anymore. Software that wishes to draw logical conclusions from data on the Web must work with reasonable reliability in the face of all this change, potential inconsistency, and incompleteness.
8 The domain name is the general part of the server’s name—usually, many servers share a domain name. For example, in the URL www.cnn.com, the domain name is cnn.com.
1.3.6 The Web and the Semantic Web
For the Semantic Web to follow the current web model, it should use key aspects of the current World Wide Web:
- Use URI-style addressing
- Have notions of addressable and non-addressable resources (a non-addressable resource is something that can be talked about—like a car or a concept— but can’t be retrieved over a communications network)
- Use protocols with a small and universally understood set of commands (likely to include extensions to the current command set)
- Maintain little or, preferably, no state information
- Be as decentralized as possible
- Function on a large scale
- Allow local caching of information to speed access and reduce network loads
- Be able to operate with missing links and with incomplete and inconsistent information.
It’s an open question whether services and agents will be designed to—or will be able to—follow these prescriptions.
1.4 The Semantic Web layer cake
The W3C has been a leader in developing technologies for the Web. The organization is headed by Tim Berners-Lee, who, not resting on his earlier accomplishments in relation to the Web, has also been promoting the development of the Semantic Web. Many of the apparently foundational technologies, such as XML and RDF, have been developed by the W3C. So the W3C approach to the evolution of the Semantic Web is worth looking at.
The W3C web pages on the Semantic Web include a diagram labeled Architecture. This diagram, sometimes called the “Semantic Web layer cake”, has been reproduced often, and our own version of it is depicted in figure 1.1. Descriptions of the layers are as follows:
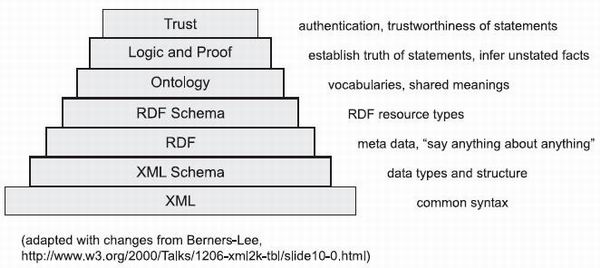
Figure 1.1 The layered technologies of the Semantic Web, according to Tim Berners-Lee and the W3C. Each layer is seen as building on—and requiring—the ones below it. The W3C has developed, or is in the process of developing, standards and recommendations for all but the top two layers, and the W3C recommendations for digital signatures and managing encryption keys will also play roles in the Trust layer.
- XML—Extensible Markup Language. The language framework that, since 1998, has been used to define nearly all new languages that are used to interchange data over the Web.
- XML Schema — A language used to define the structure of specific XML languages.
- RDF—Resource Description Framework. A flexible language capable of describing all sorts of information and meta data. RDF is covered in chapter 2. Topic maps, a non-W3C alternative standard, are discussed in chapter 3.
- RDF Schema — A framework that provides a means to specify basic vocabularies for specific RDF application languages to use. RDF Schema is covered in chapter 7.
- Ontology — Languages used to define vocabularies and establish the usage of words and terms in the context of a specific vocabulary. RDF Schema is a framework for constructing ontologies and is used by many more advanced ontology frameworks. OWL is an ontology language designed for the Semantic Web. Chapter 7 discusses ontologies, including OWL.
- Logic and Proof — Logical reasoning is used to establish the consistency and correctness of data sets and to infer conclusions that aren’t explicitly stated but are required by or consistent with a known set of data. Proofs trace or explain the steps of logical reasoning. Chapter 6 covers some issues relating to logic in the Semantic Web.
- Trust — A means of providing authentication of identity and evidence of the trustworthiness of data, services, and agents. Chapter 10 covers issues of trust with regards to the Semantic Web.
Each layer is seen as building on the layer below. At the base, most data is expected to be created in XML formats. Each layer is progressively more specialized and also tends to be more complex than the layers below it. A lower layer doesn’t depend on any higher layers. Thus, the layers can be developed and made operational relatively independently. XML is in place now, and XML Schema has recently become standardized. RDF has been released as a W3C Recommendation,9 (and has just been re-released with changes). The other layers are under development, and their form and direction are progressively uncertain according to their altitude in the layer cake.
You should realize that this diagram represents the W3C view, and most of the technologies depicted in the diagram are W3C developed or endorsed. There are potential alternatives for some of the layers. Among others, alternative schemas exist for XML documents, and there are quite a few alternative efforts to develop ontology systems.
If you noticed that there is no layer labeled Web Services, it’s true that services don’t fit neatly into this layer cake. Such technologies make use of several layers, such as XML and XML Schemas—and perhaps, in the future, RDF and Ontology. This book also discusses other technologies and subjects that don’t appear in the layer-cake diagram.
9 The W3C publishes technology standards like HTML, the common Hypertext Markup Language. It calls them Recommendations, even though many people informally call them standards or specifications. In the W3C process, a document proceeds through a series of draft stages, moving from Working Draft through Candidate Recommendation before it gets released as an approved Recommendation.
1.4.1 The base
The Web holds an enormous amount of information, and most of it is in HTML format—the language used to describe the content of ordinary web pages. This works because HTML is so widely understood (by browsers) and also because HTML is simple for page creators to understand. HTML does describe the information it contains, but it does so in terms of generic units that apply to most ordinary documents—paragraphs, headings, images, tables, and so on. An HTML page can’t label a chunk of the page to say, “This is employee information from database ‘X’;”, it can only say (in terms that a computer can use), “This is a table, and here are its rows and columns”.
The HTML for a page describes these generic document units and their order, and it’s the browser’s job to decide how to display them. You can give browsers suggestions, which they will normally try to honor as best as they can. This approach has been wildly successful when the information is intended for people to read.
With XML, you can describe the structure of the information in other ways, not just in terms of generic document units. You can choose the kind of structure that’s most suitable for the particular information and anticipated use. Thus, XML is seen as the foundation layer of the Semantic Web.
The XML Schema layer provides the ability to specify structures and data types to be used by a particular XML document. The XML and XML Schema layers aren’t covered in this book, because they’re general-purpose technologies that aren’t specially related to the Semantic Web.
1.4.2 Properties and relationships
To a browser, the “meaning” of an HTML page lies in the widely shared understanding of how to display the different kinds of generic units that appear on a web page. For a general-purpose structure, there likewise needs to be a means of indicating the meaning of the different structural units, and this should also be widely shared. This is the role of RDF. However, the idea of meaning is complicated and has many levels, and RDF deals with only two of them: assigning properties to things and relating one thing to another.
The RDF Schema layer describes those properties—what they are, which resources they can be assigned to, and so on. The Ontology layer takes this a step further: not only does it describe the properties and terms that can be used, but it also can describe relationships between them.
These layers are used to describe, or represent, knowledge. Although the W3C version of the layer cake shows only RDF and RDF Schema, this book also discusses another candidate for representing knowledge: topic maps.
1.4.3 Analysis, verification, and trust
Once the relationships between resources, terms, and properties have been established, the statements that RDF expresses can be analyzed for consistency and inferences can be made. By this means, facts that aren’t explicitly stated can be discovered, and inconsistent facts can (sometimes) be reconciled. The Logic and Proof layer provides these capabilities.
When I purchase a book and give my credit card number, the bookseller wants to know if the card is mine. If I’m there in person, I can show my driver’s license to give a kind of credence to my claim of identity. In essence, I’m saying, “If you don’t believe me, then trust the licensing authority”. This is acceptable as long as the seller believes that the identity card is not counterfeit. The seller might assess the validity of the card by its visual appearance, the match between the picture and my face, the degree of agreement between the age on the card and my apparent age, and any number of other clues. Here, you see several principles in play: an appeal to authority, the trustworthiness of that authority, an inference of validity based on a set of facts, and beliefs about those facts.
When I buy the same book online, the seller likewise needs to have some assurance that the credit card is valid and that I’m authorized to use it. I need assurance that the web page really belongs to the bookseller and not to a criminal who wants to get access to my card. When software programs work with data they get over the Web, they face the same problems. The Trust layer will attempt to handle these issues. You can see how it will use all the other layers. The Trust machinery has to call on the Logic and Proof layer to analyze claims, make inferences, and draw conclusions. The Logic and Proof layer needs to know how the terms and properties relate to each other and whether they’re used correctly, which is the business of the Ontology layer. The Ontology layer needs to use the data structures defined and created by the RDF and XML Schema layers. These dependencies can also be viewed in the other direction: the RDF layer uses RDF Schema and Ontology as it assigns its properties, and the XML layer provides transportable data structures for the RDF information.
This layer cake structure sounds complicated, and it is. But it doesn’t all have to be in place before anything can be done. The important thing is to get widespread acceptance of relevant bits. That’s how the Web spread in the first place.
1.5 Summary
The Semantic Web is not a cut-and-dried, integrated technology. It’s a concept of how computers, people, and the Web can work together more effectively than is possible now. Because it’s visionary, it has no one definition. In fact, you saw a staggering array of notions earlier in this chapter, such as the machine-readable- data view, the intelligent agents view, and many more. However, these overlapping views have some aspects in common, and this book deals with these commonalities.
Basically, all the views assume that computers will be able to read and use data that today is mainly accessible to people. All views see computers as being able to use this data to perform tasks that help people. Within this broad range, certain themes show up repeatedly, as we’ve discussed in this chapter. The rest of this book covers each of these themes as they relate to the Semantic Web.
The current Web is the one success story we have of a very large, distributed, loosely connected, inconsistent system. It seems reasonable, therefore, that the Semantic Web should use the strengths of the current Web, especially key design patterns that have made it a success. In fact, it should be an extension of the current Web.
This member has not yet provided a Biography. Assume it’s interesting and varied, and probably something to do with programming.
|
|
|
So he went down to the agora, or marketplace, where there were a lot of unemployed philosophers—which means philosophers which were not thinking at that time.
Thought—in other words, philosophers can tell you millions of things that thought isn’t, and they can’t tell you what it is—and this bugs them!
—Severn Darden, Lecture on Metaphysics
In the beginning, there was no Web. The Web began as a concept of Tim Berners-Lee, who worked for CERN, the European organization for physics research. CERN’s technical staff urgently needed to share documents located on their many computers. Berners-Lee had previously built several systems to do that, and with this background, he conceived the World Wide Web. The design had a relatively simple technical basis, which helped the technology take hold and gain critical mass.
Berners-Lee wanted anyone to be able to put information on a computer and make that information accessible to anyone else, anywhere. He hoped that eventually, machines would also be able to use information on the Web. Ultimately, he thought, this would allow powerful and effective human-computer-human collaboration:
I have always imagined the information space as something to which everyone has immediate and intuitive access, and not just to browse but to create… Machines become capable of analyzing all the data on the Web—the content, links, and transactions between people and computers.
…when [the Semantic Web] does [emerge], the day-to-day mechanisms of trade, bureaucracy, and our daily lives will be handled by machines talking to machines, leaving people to provide the inspiration and intuition. (Berners- Lee 2000)
I find this vision inspiring, and the means to get there intriguing. The Semantic Web has, in a way, become almost a celebrity—Scientific American has even published an article on it (Berners-Lee, Hendler, and Lassila 2001)—although most people don’t know what it is, and although there really isn’t a Semantic Web yet. There are many different ideas of what it is, not just one. In this chapter, we examine a range of ideas about what the Semantic Web should be. Some of them may seem futuristic or impractical, but a great deal of work is going on in all the areas we’ll examine.
1.1 What is the Semantic Web?
The word semantic implies meaning or, as WordNet defines it, “of or relating to the study of meaning and changes of meaning”. For the Semantic Web, semantic indicates that the meaning of data on the Web can be discovered—not just by people, but also by computers. In contrast, most meaning on the Web today is inferred by people who read web pages and the labels of hyperlinks, and by other people who write specialized software to work with the data. The phrase the Semantic Web stands for a vision in which computers—software—as well as people can find, read, understand and use data over the World Wide Web to accomplish useful goals for users.
Of course, we already use software to accomplish things on the Web, but the distinction lies in the words we use. People surf the Web, buy things on web sites, work their way through search pages, read the labels on hyperlinks, and decide which links to follow. It would be much more efficient and less time-consuming if a person could launch a process that would then proceed on its own, perhaps checking with the person from time to time as the work progressed. The business of the Semantic Web is to bring such capabilities into widespread use.
In brief, the Semantic Web is supposed to make data located anywhere on the Web accessible and understandable, both to people and to machines. This is more a vision than a technology. In this book, we’ll explore the technologies that will play roles in bringing the vision to life.
As you might expect, there are many different ideas about what this general vision encompasses. An almost overwhelming number of different ideas exists about the supposed nature of the Semantic Web, and that’s the first lesson to learn: The Semantic Web is a fluid, evolving, informally defined concept rather than an integrated, working system. To give you a feel for this range of ideas, here are some representative quotations about the nature of the Semantic Web:
- The machine-readable-data view — “The Semantic Web is a vision: the idea of having data on the Web defined and linked in a way that it can be used by machines not just for display purposes, but for automation, integration and reuse of data across various applications.” (W3C 2003)
- The intelligent agents view — “The aim of the Semantic Web is to make the present Web more machine-readable, in order to allow intelligent agents to retrieve and manipulate pertinent information.” (Cost et al 2001)
- The distributed database view — “The Semantic Web concept is to do for data what HTML did for textual information systems: to provide sufficient flexibility to be able to represent all databases and logic rules to link them together to great added value.” (W3C 2000) “A simple description of the Semantic Web is that it is an attempt to do for machine processable data what the World Wide Web did for human readable documents. Namely, to transform information processing by providing a common way that data can be accessed, linked together and understood. To turn the Web from a large hyperlinked book into a large interlinked database.” (SWAD-E)
- The automated infrastructure view — “In his recent Scientific American article, Berners-Lee argues that the Semantic Web is infrastructure and not an application. We couldn’t agree more.” (Tuttle et al 2001) “Therefore, the real problem is the lack of an easy automation framework in the current Web…” (Garcia and Delgado 2001)
- The servant-of-humanity view — “The vision of the Semantic Web is to let computer software relieve us of much of the burden of locating resources on the Web that are relevant to our needs and extracting, integrating, and indexing the information contained within.” (Cranefield 2001) “The Semantic Web is a vision of the next-generation web, which enables web applications to automatically collect web documents from diverse sources, integrate and process information, and interoperate with other applications in order to execute sophisticated tasks for humans.” (Anutariya et al 2001)
- The better-annotation view — “The idea of a ‘Semantic Web’ [Berners-Lee 2001] supplies the (informal) web, as we know it, with annotations expressed in a machine-processable form and linked together.” (Euzenat 2001)
- The improved-searching view — “Soon it will be possible to access Web resources by content rather than just by keywords.” (Anutariya et al 2001) “The main goal [of the technology described in the paper] is to build a structured index of the Web site.” (Desmontils and Jacquin 2001)
- The web services view — “Increasingly, the Semantic Web will be called upon to provide access not just to static documents that collect useful information, but also to services that provide useful behavior.” (Klein and Bernstein 2001)
“The Semantic Web promises to expand the services for the existing web by enabling software agents to automate procedures currently performed manually and by introducing new applications that are infeasible today.” (Tallis, Goldman, and Balzer 2001)
It’s clear that this notion of the Semantic Web covers a lot of ground, and perhaps no two people have quite the same idea about it. Still, several themes are expressed time and again:
- Indexing and retrieving information
- Meta data
- Annotation
- The Web as a large, interoperable database
- Machine retrieval of data
- Web-based services
- Discovery of services
- Intelligent software agents
Let’s look more closely at these themes.
1.1.1 Indexing and retrieving information
Everyone wrestles with how to find information. Libraries have card catalogs, and now many have electronic indexes. Search engines are vital components of the Web. Yet at some point, everyone has been frustrated and annoyed by how hard it is to locate things, especially when you aren’t sure what to ask for. To find information, a Semantic Web approach would expect to go beyond keyword and alphabetical indexes to let users search by concepts and categories.
The Web part brings in a persistent theme, in which information is distributed— spread throughout the Web—rather than concentrated in a few repositories. Most systems that use concept identification to retrieve information maintain their own concept hierarchies and attempt to identify those concepts in the documents they index. Sometimes, concepts in a document collection are identified automatically, with varying success. To go further requires that documents be able to declare their own vocabularies and sets of concepts and to identify where they’re used.
1.1.2 Meta data
Card catalogs and electronic indexes contain data about the works that are cataloged and indexed. Data about other data is often called meta data. For example, the ISBN number and the author’s name are meta data about a novel. The data types describing the data in a database also fall into the category of meta data. It’s even possible to have meta meta data (a statement about the origin of a piece of meta data could be considered to be meta data about meta data, or meta meta data).
In one sense, meta data is still data; the distinction lies in the intended use of the data and in the subject of the meta data. It’s meta data that will be used for searches and for discovery of information. Annotation can also be thought of as meta data.
1.1.3 Annotation
In the world of physical documents (such as books), people write margin notes and comments, they underline and highlight passages, they staple new items to reports, and they add thoughts and ideas to those of the original authors. Markup languages like XML should, you’d think, be able to add such annotations; but today, it’s hard to do this in a simple way that lets other people share your annotations and lets you move your annotations to other applications and computers. Wiki-style web sites attempt to let many people comment on and modify web pages, but this process covers only a little of what people would like to do.
Because annotations should be shareable, and because the meaning of different types of annotations should be widely understood, support for extensive annotation capabilities is often seen as part of the Semantic Web.
1.1.4 A huge interoperable database
Today, it’s common to get data from a database over the Web. These databases are generally separate and not easily used as merged data sources, and a great deal of data exists outside of databases. This part of the Semantic Web vision sees ways to unify the description and retrieval of stored data, allowing much of the Web to be considered part of a large virtual database.
Consider a sports researcher looking for baseball data. There are various online baseball databases: The Major League Baseball web site is but one of many. But if our researcher wants to find performance statistics for Stan Musial, whose career lasted from the 1940s to the 1960s, she can’t get data for the whole period in a mutually compatible format. At least for baseball statistics, there is some common agreement on the definitions of the most important statistics, so that a batting average is always computed the same way—this is more than can be said for most separate collections of data.
If the Web functioned as an interoperable database, the researcher could get the data from all the important sites, and the researcher’s software would be able to either display all the data together or automatically combine data from, say, the Major League Baseball site and the Baseball Almanac.
1.1.5 Machine retrieval of data
This part of the vision focuses on automatic acquisition of data. This means that, a piece of software, in pursuit of its assignment, determines what data it needs and where and how to get it, and then goes out and gets the data. Using the baseball example from the previous section, suppose our researcher has to find the right web pages, load them, and then figure out a way to get the data and organize it. This is hard to do and often takes a lot of time. Under the Semantic Web, the data format and its manner of access would be described in a way that would allow the researcher’s computer to get and use the data automatically.
1.1.6 Services
A service is a behavior that provides a benefit. Examples include making reservations, arranging schedules, providing prices, placing orders, and so forth. Think of ordering, say, a perishable item like flowers or food. Once you’ve selected a product to buy, you have to make sure that its delivery will fit into your schedule. The price, buying conditions, delivery options, and your schedule can all be thought of as services that must be activated and coordinated. In the “Semantic Web as web services” view, all these services would publish machine-readable data that would allow a computer to do all the activation and coordination for you.
1.1.7 Discovery
To use services, you (and especially your software) must be able to find them, discover what they do, and learn how to invoke them. This is the realm of discovery of services. The most obvious approach would be to create directories of services with standard access methods. The services would be described in standard terms, and information about how to access them and the available information would be encoded in standard ways.
Consider an analogy with a physical library. Most libraries in the United States use either the Dewey Decimal System or the Library of Congress method to catalog their books. After using the card catalog or its electronic version, a person becomes familiar with the classifications and learns how to find books on the shelves. Here, the standard access methods are the familiar classification system and the physical arrangement of books in the library.
A more advanced approach would be to send out discovery requests based on the services required, and for candidate services to describe their capabilities in such a way that the would-be user could deduce their capabilities and instigate a conversation to find any missing or uncertain information. Returning to the library example, this would be like getting an experienced research librarian to tell you which reference books to look at and how to understand the information in them.
1.1.8 Intelligent agents
An agent is someone or something that acts on your behalf. A software agent would act in a somewhat autonomous way, communicating with other software agents (which might be specialized) to discover services, products or information for you. For instance, one of those specialized agents might know how to purchase airline tickets and make reservations. Another agent might perform the required services, passing the results back to your own agent, which would notify you of the outcome. It’s clear that a network of interacting agents would have to be able to describe its goals using established vocabularies, to discover services and information resources, and to use many of the capabilities described in the previous sections.
1.2 Two Semantic Web scenarios
To give you a feel for the way these areas might interact and how the Semantic Web could provide great value, here are two scenarios that were developed during the workshop “Research Challenges and Perspectives of the Semantic Web”.1 Both scenarios illustrate what might be called personal services. Of course, similar scenarios could be constructed for many other areas, such as business-to-business transactions. Note that the language is taken directly from the report without corrections for grammatical and spelling errors.
Scenario 1: A research assistant
During her stay at Honolulu, Clara ran into several interesting people with whom she exchanged vCards. When time to rest came in the evening, she had a look at her digital assistant summarizing the events of the day and recalling the events to come (and especially her keynote talk of the next day). The assistant popped up a note with a link to a vCard that reads: “This guy’s profile seems to match the position advertisement that Bill put on our intranet. Can I notify Bill’s assistant?”
Clara hit the “explain!” button. “I used his company directory for finding his DAML2 enhanced vita: he’s got the required skills as a statistician who led the data mining group of the database department at Montana U. for the requirement of a researcher who worked on machine learning.” Clara hit then the “evidence!” button. The assistant started displaying “I checked his affiliation with University of Montana, he is cited several times in their web pages: reasonably trusted; I checked his publication records from publishers’ DAML sources and asked bill assistant a rating of the journals: highly trusted. More details?”
Clara had enough and let her assistant inform Bill’s.
1 This workshop was organized by the European Consortium in Informatics and Mathematics (ERCIM) for the European Union Future Emergent Technology program (EU-FET) and the US National Science Foundation (NSF). It was held in Sophia-Antipolis, France, in October 2001.
2 DARPA Agent Markup Language; see chapter 7.
Scenario 2: Negotiating a date
Bill’s and Peter’s assistants arranged a meeting in Paris, just before ISWC3 in Sardinia. Thanks to Peter’s assistant knowing he was vegetarian, they avoided a faux pas. Bill was surprised that Peter was able to cope with French (his assistant was not authorized to unveil that he married a woman from Québec). Bill and Peter had a fruitful meeting and Bill will certainly be able to send Peter an offer before he came back to the US.
Before dinner, Peter investigated a point that bothered him: Bill used the term “Service” in an unusual way. He wrote: “Acme computing will run the trust rating service for semanticweb.org” (a sentence from Bill). His assistant found no problem, so he hit: “service”, the assistant displayed “service in {database} equivalent To: infrastructure”. Peter asked for “metainfo”, which raised “Updated today by negotiating with Bill’s assistant”.
Peter again asked for “Arguments!”: “Service in {database} conflicts with service in {web}”. “Explain!” “In operating system and database, the term services covers features like fault-tolerance, cache, security, that we are used to putting in the infrastructure. More evidence?” Peter was glad he had not to search the whole Web for an explanation of this. The two assistants detected the issue and negotiated silently a solution to this problem. He had some time left before getting to the théatre de la ville. His assistant made the miracle to book him a place for a rare show of Anne-Theresa De Keermaeker’s troupe in Paris. It had to resort to a particular web service that it found through a dance-related common interest pool of assistants.
3 Presumably the International Semantic Web Conference.
In these scenarios, you can see quite a few Semantic Web areas in operation at the same time. Software agents (the digital assistants) are discovering meta data and information and processing it. Logical reasoning is not only used to make inferences, it’s also explained to the human user. Assessments of trust and reliability are deduced through networks of interacting information. We see the discovery of web services. It all seems so plausible and so useful.
1.2.1 Can the Semantic Web work this way?
What needs to be developed, what needs to be in place, for the Semantic Web to work as envisioned in the previous scenarios? The keys are the widespread interchange of data and ways to mark, indicate, or describe what that data is, how it’s structured, how it can be retrieved, and what it means. Each of these areas is a large undertaking in itself. But the Semantic Web will be a sociological development, too. Companies must cooperate where they might normally compete; academic research must be translated into practical systems; individuals must discover how they can contribute; and issues of for-profit versus free, of closed versus open systems, and of trust need to be worked out.
The task is much bigger than the building of the original World Wide Web. At that time, few people realized how many new capabilities the Web would unleash. Today, some of the basic infrastructure is already in place. There are organizations like the World Wide Web Consortium (W3C), whose purpose includes developing and advancing standards of importance to the Internet as a whole, including the Semantic Web. So the task is bigger, but the starting point is more advanced.
Can the visions be realized? Opinions vary—mine is that many of them will come to pass (some are already beginning to operate) and make a real difference in the lives of people who use the Web.
1.3 The Semantic Web’s foundation
The World Wide Web has certain design features that make it different from earlier hyperlink experiments. These features will play an important role in the design of the Semantic Web. The Web is not the whole Internet, and it would be possible to develop many capabilities of the Semantic Web using other means besides the World Wide Web. But because the Web is so widespread, and because its basic operations are relatively simple, most of the technologies being contemplated for the Semantic Web are based on the current Web, sometimes with extensions. However, web services (chapter and agents (chapter 9) may step outside the architecture of the current Web, as you’ll see.4
The Web is designed around resources, standardized addressing of those resources (Uniform Resource Locators and Uniform Resource Indicators), and a small, widely understood set of commands. It’s also designed to operate over very large and complex networks in a decentralized way. Let’s look at each of these design features.
4 I’m referring in part to the so-called REST (Representation State Transfer) architecture and the controversy over whether current SOAP-based web services that don’t use this model would be better suited to the Web if they did.
1.3.1 Resources
The Web addresses, retrieves, links to, and modifies resources. A resource is intended to represent any idea that can be referred to. Usually, we think of these resources as being tangible packages of data (documents or pages), but the notion of a resource is more general in two ways. First, a resource can change over time and still be considered the same resource, addressed by the same Uniform Resource Identifier (URI). Thus, a series of drafts of a manuscript could be addressed by the same URI. Alternatively, a URI could denote one specific, unchanging version of the same document. The notion of resource is flexible enough to encompass both varying and fixed resources.
Strictly speaking, a resource itself is not retrieved, but only a representation of the resource. For some protocols, like File Transfer Protocol (FTP), the representation is normally a copy of a file. For others, like HTTP, the representation may or may not be a copy of a file. A resource can even be represented by different forms—a PDF file, an HTML page, a voice recording, and so on.
Second, and perhaps harder to grasp, a resource can be something that doesn’t yet exist, and that may never exist. A resource can be a concept or a reference to a real or fictitious person—something that can’t be addressed and transferred over a network, but that can be talked about, thought about. For the purposes of the Semantic Web, such a resource can be referred to or identified by a URI.5
5 For example, RFC 1737, “Functional Requirements for Uniform Resource Names” (a subset of URIs), says, “The purpose or function of a URN is to provide a globally unique, persistent identifier used for recognition, for access to characteristics of the resource or for access to the resource itself.” (Emphasis added.)
1.3.2 Standardized addressing
All resources on the Web are referred to by URIs. The most familiar URIs are those that address resources that can be addressed and retrieved; these are called URLs, for Uniform Resource Locators. These URIs have a uniform structure that can refer to the use of other protocols besides HTTP (like FTP), and they are easy to type and copy. They can be inserted into hyperlinks so that any addressable information can be easily linked.
1.3.3 Small set of commands
The HTTP protocol (the protocol used to send messages back and forth over the Web) uses a small set of commands. These commands are universally understood by web servers, clients (like browsers), and intermediate components like caches-which can reduce network traffic by storing copies of documents that were previously sent. With this limited set of commands, there is no question about what is being requested of the server and network, and no visibility into how the server may choose to carry out the requests. This model doesn’t provide security or personal privacy for the information being sent or requested; but, since it is simple and well understood, the model lends itself to the provision of additional layers of security.6
However, some architectures use complex messages or need to restrict the visibility of message contents, and they use an approach that’s more involved than basic HTTP. Other Internet protocols can be used, and additional messaging layers can be carried over HTTP as well (such as SOAP, whose name no longer stands for anything). There is some controversy over what methods should be used for the Web—as distinct from the Internet, which includes much more than the World Wide Web—and whether the Semantic Web architecture should restrict itself to the simpler architecture of the current Web.
6 There is some controversy over whether the web model supports security provisions better than other network architectures such as Remote Procedure Call (RPC) systems.
1.3.4 Scalability and large networks
The Web has to operate over a very large network with an enormous number of web sites and to continue to work as the network’s size increases. It accomplishes this, thanks to two main design features. First, the Web is decentralized. If you have a computer on the network, you can put a web server on it; and if you have a server, you can add resources to it without registering them anywhere else.
Second, each transaction on the Web (that is, a request and the subsequent response) contains all the information needed to handle the request. No data needs to be stored by the server from one request to another. However, many practical uses of the Web do require that some data be saved for a period of time. If you reserve a ticket and then order it on another web page, the system must store your ticket reservation and be able to connect it to your request to purchase. Since any web transaction is separate from all others, it’s harder to arrange to maintain data across a connected series of transactions. Independent interactions make possible a large, decentralized system where responses can be cached to allow faster responses and reduce network traffic.
Data that maintains some history of transactions is sometimes called state, as in “the state of the system”. Web transactions are stateless.7 If there is a business need to store information across several interactions, the server must provide special arrangements to make it happen.
7 When a cookie is stored on your computer, the cookie stores some state information. Unfortunately, this state doesn’t fit the web model well, so it can sometimes cause confusion between browser, server, and user.
1.3.5 Openness, completeness, and consistency
The Web is open, meaning that web sites and web resources can be added freely and without central controls. The assignment of domain names to servers does need some central authority to avoid duplicate names,8 but this in no way restricts your ability to establish web servers and the information they provide.
The Web is incomplete, meaning there can be no guarantee that every link will work or that all possible information will be available. It can be inconsistent: anyone can say anything on a web page, so different web pages can easily contradict each other. Information on the Web will never be fully consistent, and it also changes constantly. Just think of all the web pages you’ve returned to that changed since you last visited them, or that don’t even exist anymore. Software that wishes to draw logical conclusions from data on the Web must work with reasonable reliability in the face of all this change, potential inconsistency, and incompleteness.
8 The domain name is the general part of the server’s name—usually, many servers share a domain name. For example, in the URL www.cnn.com, the domain name is cnn.com.
1.3.6 The Web and the Semantic Web
For the Semantic Web to follow the current web model, it should use key aspects of the current World Wide Web:
- Use URI-style addressing
- Have notions of addressable and non-addressable resources (a non-addressable resource is something that can be talked about—like a car or a concept— but can’t be retrieved over a communications network)
- Use protocols with a small and universally understood set of commands (likely to include extensions to the current command set)
- Maintain little or, preferably, no state information
- Be as decentralized as possible
- Function on a large scale
- Allow local caching of information to speed access and reduce network loads
- Be able to operate with missing links and with incomplete and inconsistent information.
It’s an open question whether services and agents will be designed to—or will be able to—follow these prescriptions.
1.4 The Semantic Web layer cake
The W3C has been a leader in developing technologies for the Web. The organization is headed by Tim Berners-Lee, who, not resting on his earlier accomplishments in relation to the Web, has also been promoting the development of the Semantic Web. Many of the apparently foundational technologies, such as XML and RDF, have been developed by the W3C. So the W3C approach to the evolution of the Semantic Web is worth looking at.
The W3C web pages on the Semantic Web include a diagram labeled Architecture. This diagram, sometimes called the “Semantic Web layer cake”, has been reproduced often, and our own version of it is depicted in figure 1.1. Descriptions of the layers are as follows:
Figure 1.1 The layered technologies of the Semantic Web, according to Tim Berners-Lee and the W3C. Each layer is seen as building on—and requiring—the ones below it. The W3C has developed, or is in the process of developing, standards and recommendations for all but the top two layers, and the W3C recommendations for digital signatures and managing encryption keys will also play roles in the Trust layer.
- XML—Extensible Markup Language. The language framework that, since 1998, has been used to define nearly all new languages that are used to interchange data over the Web.
- XML Schema — A language used to define the structure of specific XML languages.
- RDF—Resource Description Framework. A flexible language capable of describing all sorts of information and meta data. RDF is covered in chapter 2. Topic maps, a non-W3C alternative standard, are discussed in chapter 3.
- RDF Schema — A framework that provides a means to specify basic vocabularies for specific RDF application languages to use. RDF Schema is covered in chapter 7.
- Ontology — Languages used to define vocabularies and establish the usage of words and terms in the context of a specific vocabulary. RDF Schema is a framework for constructing ontologies and is used by many more advanced ontology frameworks. OWL is an ontology language designed for the Semantic Web. Chapter 7 discusses ontologies, including OWL.
- Logic and Proof — Logical reasoning is used to establish the consistency and correctness of data sets and to infer conclusions that aren’t explicitly stated but are required by or consistent with a known set of data. Proofs trace or explain the steps of logical reasoning. Chapter 6 covers some issues relating to logic in the Semantic Web.
- Trust — A means of providing authentication of identity and evidence of the trustworthiness of data, services, and agents. Chapter 10 covers issues of trust with regards to the Semantic Web.
Each layer is seen as building on the layer below. At the base, most data is expected to be created in XML formats. Each layer is progressively more specialized and also tends to be more complex than the layers below it. A lower layer doesn’t depend on any higher layers. Thus, the layers can be developed and made operational relatively independently. XML is in place now, and XML Schema has recently become standardized. RDF has been released as a W3C Recommendation,9 (and has just been re-released with changes). The other layers are under development, and their form and direction are progressively uncertain according to their altitude in the layer cake.
You should realize that this diagram represents the W3C view, and most of the technologies depicted in the diagram are W3C developed or endorsed. There are potential alternatives for some of the layers. Among others, alternative schemas exist for XML documents, and there are quite a few alternative efforts to develop ontology systems.
If you noticed that there is no layer labeled Web Services, it’s true that services don’t fit neatly into this layer cake. Such technologies make use of several layers, such as XML and XML Schemas—and perhaps, in the future, RDF and Ontology. This book also discusses other technologies and subjects that don’t appear in the layer-cake diagram.
9 The W3C publishes technology standards like HTML, the common Hypertext Markup Language. It calls them Recommendations, even though many people informally call them standards or specifications. In the W3C process, a document proceeds through a series of draft stages, moving from Working Draft through Candidate Recommendation before it gets released as an approved Recommendation.
1.4.1 The base
The Web holds an enormous amount of information, and most of it is in HTML format—the language used to describe the content of ordinary web pages. This works because HTML is so widely understood (by browsers) and also because HTML is simple for page creators to understand. HTML does describe the information it contains, but it does so in terms of generic units that apply to most ordinary documents—paragraphs, headings, images, tables, and so on. An HTML page can’t label a chunk of the page to say, “This is employee information from database ‘X’;”, it can only say (in terms that a computer can use), “This is a table, and here are its rows and columns”.
The HTML for a page describes these generic document units and their order, and it’s the browser’s job to decide how to display them. You can give browsers suggestions, which they will normally try to honor as best as they can. This approach has been wildly successful when the information is intended for people to read.
With XML, you can describe the structure of the information in other ways, not just in terms of generic document units. You can choose the kind of structure that’s most suitable for the particular information and anticipated use. Thus, XML is seen as the foundation layer of the Semantic Web.
The XML Schema layer provides the ability to specify structures and data types to be used by a particular XML document. The XML and XML Schema layers aren’t covered in this book, because they’re general-purpose technologies that aren’t specially related to the Semantic Web.
1.4.2 Properties and relationships
To a browser, the “meaning” of an HTML page lies in the widely shared understanding of how to display the different kinds of generic units that appear on a web page. For a general-purpose structure, there likewise needs to be a means of indicating the meaning of the different structural units, and this should also be widely shared. This is the role of RDF. However, the idea of meaning is complicated and has many levels, and RDF deals with only two of them: assigning properties to things and relating one thing to another.
The RDF Schema layer describes those properties—what they are, which resources they can be assigned to, and so on. The Ontology layer takes this a step further: not only does it describe the properties and terms that can be used, but it also can describe relationships between them.
These layers are used to describe, or represent, knowledge. Although the W3C version of the layer cake shows only RDF and RDF Schema, this book also discusses another candidate for representing knowledge: topic maps.
1.4.3 Analysis, verification, and trust
Once the relationships between resources, terms, and properties have been established, the statements that RDF expresses can be analyzed for consistency and inferences can be made. By this means, facts that aren’t explicitly stated can be discovered, and inconsistent facts can (sometimes) be reconciled. The Logic and Proof layer provides these capabilities.
When I purchase a book and give my credit card number, the bookseller wants to know if the card is mine. If I’m there in person, I can show my driver’s license to give a kind of credence to my claim of identity. In essence, I’m saying, “If you don’t believe me, then trust the licensing authority”. This is acceptable as long as the seller believes that the identity card is not counterfeit. The seller might assess the validity of the card by its visual appearance, the match between the picture and my face, the degree of agreement between the age on the card and my apparent age, and any number of other clues. Here, you see several principles in play: an appeal to authority, the trustworthiness of that authority, an inference of validity based on a set of facts, and beliefs about those facts.
When I buy the same book online, the seller likewise needs to have some assurance that the credit card is valid and that I’m authorized to use it. I need assurance that the web page really belongs to the bookseller and not to a criminal who wants to get access to my card. When software programs work with data they get over the Web, they face the same problems. The Trust layer will attempt to handle these issues. You can see how it will use all the other layers. The Trust machinery has to call on the Logic and Proof layer to analyze claims, make inferences, and draw conclusions. The Logic and Proof layer needs to know how the terms and properties relate to each other and whether they’re used correctly, which is the business of the Ontology layer. The Ontology layer needs to use the data structures defined and created by the RDF and XML Schema layers. These dependencies can also be viewed in the other direction: the RDF layer uses RDF Schema and Ontology as it assigns its properties, and the XML layer provides transportable data structures for the RDF information.
This layer cake structure sounds complicated, and it is. But it doesn’t all have to be in place before anything can be done. The important thing is to get widespread acceptance of relevant bits. That’s how the Web spread in the first place.
1.5 Summary
The Semantic Web is not a cut-and-dried, integrated technology. It’s a concept of how computers, people, and the Web can work together more effectively than is possible now. Because it’s visionary, it has no one definition. In fact, you saw a staggering array of notions earlier in this chapter, such as the machine-readable- data view, the intelligent agents view, and many more. However, these overlapping views have some aspects in common, and this book deals with these commonalities.
Basically, all the views assume that computers will be able to read and use data that today is mainly accessible to people. All views see computers as being able to use this data to perform tasks that help people. Within this broad range, certain themes show up repeatedly, as we’ve discussed in this chapter. The rest of this book covers each of these themes as they relate to the Semantic Web.
The current Web is the one success story we have of a very large, distributed, loosely connected, inconsistent system. It seems reasonable, therefore, that the Semantic Web should use the strengths of the current Web, especially key design patterns that have made it a success. In fact, it should be an extension of the current Web.
This member has not yet provided a Biography. Assume it’s interesting and varied, and probably something to do with programming.
Практическое занятие
Решение задач с использованием семантической сети
Цель занятия:
— учить составлять сети;
— учить определять характеристические данные по сетям;
— учить строить семантические сети.
Пояснения к работе
Семантическая сеть — информационная модель предметной области, имеющая вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Объектами могут быть понятия, события, свойства, процессы. Таким образом, семантическая сеть является одним из способов представления знаний.
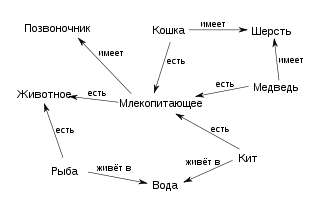
В качестве понятий (вершин) обычно выступают абстрактные или конкретные объекты (огурец, машина, любовь, Маша). В качестве отношений (дуг) наиболее часто используются следующие (смысловая классификация).
— таксономические («класс – подкласс – экземпляр», «множество – подмножество – элемент» и т.п.);
— структурные («часть – целое»);
— родовые («предок» — «потомок»);
— производственные («начальник» — «подчиненный»);
— функциональные (определяемые обычно глаголами «производит», «влияет» и т.п.);
— количественные (больше, меньше, равно и т.п.);
— пространственные (далеко от, близко от, за, под, над и т.п.);
— временные (раньше, позже, в течение и т.п.);
— атрибутивные (иметь свойство, иметь значение);
— логические (И, ИЛИ, НЕ);
— казуальные (причинно-следственные).
Примеры простых семантических сетей изображены на рисунке:
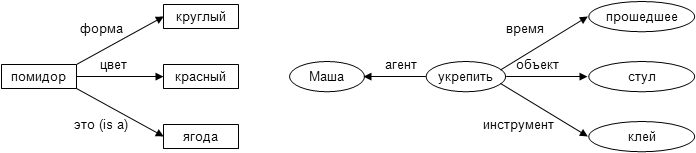
В разных вариациях семантических сетей для отображения понятий используются различные геометрические примитивы: прямоугольники, овалы, прямоугольники со скругленными углами и т.п.
Проблема поиска решения в семантической сети сводится к задаче поиска фрагмента сети, соответствующего поставленному запросу. Например, вопрос «Какого цвета помидор?» можно графически представить в виде подсети.
![]()
Рис. Представление вопроса в виде подсети
Наложение подсети вопроса на сеть, описывающую предметную область, дает ответ – «красный».
Семантические сети широко используются в экспертных системах в качестве языка представления знаний (например, в экспертной системе PROSPECTOR), в системах распознавания речи и понимания естественного языка. Непосредственное отношение к сетевым моделям имеют исследования по реляционным, сетевым и иерархическим БД.
Классифицировать семантические сети можно по следующим признакам:
1. по количеству типов отношений:
— однородные (с единственным типом отношений);
— неоднородные (с различными типами отношений);
2. по назначению:
— классифицирующие — позволяют описывать различные иерархические отношения между понятиями;
— функциональные — вычислительные модели, позволяющие описывать процедуры вычислений одних информационных единиц через другие;
— сценарии — используются для описания каузальных отношений (причинно-следственных или устанавливающих влияние одних явлений или фактов на другие), а также отношений типа «средство — результат», «орудие — действие» и т.п.;
— другие
Достоинства семантических сетей:
— универсальность, достигаемая за счет выбора соответствующего набора отношений. В принципе с помощью семантической сети можно описать сколь угодно сложную ситуацию, факт или предметную область;
— наглядность системы знаний, представленной графически;
— близость структуры сети, представляющей систему знаний, семантической структуре фраз на естественном языке;
— соответствие современным представлениям об организации долговременной памяти человека.
Недостатки семантических сетей:
— сетевая модель не дает (точнее, не содержит) ясного представления о структуре предметной области, поэтому формирование и модификация такой модели затруднительны;
— проблема поиска решения в семантической сети сводится к задаче поиска фрагмента сети, соответствующего подсети, отражающей поставленный запрос. Это, в свою очередь, обуславливает сложность поиска решения в семантических сетях;
— представление, использование и модификация знаний при описании систем реального уровня сложности оказывается трудоемкой процедурой, особенно при наличии множественных отношений между ее понятиями.
Задание
-
Изучить самостоятельно методические рекомендации по проведению практической работы №17.
-
Составить семантическую сеть для запутанной ситуации и ответить на вопрос из задания 1.
-
В задании 2 ответить на вопрос, исследуя семантическую сеть.
-
В задании 3 построить семантическую сеть.
-
Выполнить задание 4 на применение взвешенного графа.
-
Выполнить дополнительное задание.
-
Ответить на контрольные вопросы
Задание 1
Для 1 и 4 вариантов
Боксёры с твёрдою походкой
Не моют пол зубною щёткой.
Кто моет пол зубною щёткой,
Тот наделён душою кроткой.

Для 2 и 6 вариантов
Собаки с рыжими хвостами
Себе овсянку варят сами.
Тем, чьи хвосты стального цвета,
Не позволяют делать это.
Кто варит себе овсянку,
Гулять выходит спозаранку.
Все, кто гулять выходит рано,
Не терпят фальши и обмана.
Вид добродушный у Барбоса,
Но на сорок он смотрит косо..
Он видит: норовят сороки
У воробьёв списать уроки!
Скажите – проще нет вопроса!
Какого цвета хвост Барбоса?
Кто пол мыть щёткой не желает,
Суровым нравом обладает.
Суровый нрав у тех бывает,
Кто книжек вовсе не читает.
Фосс враг и книжек и газет,
Ответь, боксёр он или нет?
Для 3 и 5 вариантов
Широкоплечие мужчины
Поют, садясь за руль машины.
Мужчины с узкими плечами,
Садясь за руль молчат как камень.
Те, кто за руль садятся с пеньем,
Не отличаются терпеньем.
Те кто в машине молчаливы,
Бывают очень терпеливы.
Терпенье тем дано с избытком.
Кто чинит домики улиткам.
Чтоб домик починить улитке,
Клей варят на электроплитке.
Фосс не выносит запах клея,
Он сразу падает, бледнея.
Прошу ответить на вопрос:
Широкоплеч ли мистер Фосс?
Задание 2. По семантической сети определить:
Для 1 варианта: Как связаны между собой Орёл и Самолет?
Для 2 варианта: В какой форме и какой высоты должен быть Блок, находящийся ниже другого блока в Башне1?
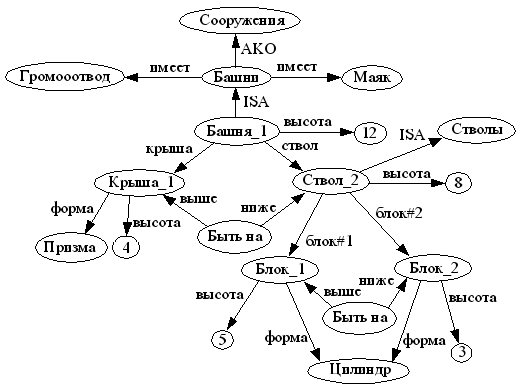
Для 3 варианта: Добавить вершину сети так, чтобы была ещё одна связь между Сергеем и Андреем.

Для 4 варианта: Как может крестьянин разбогатеть, что ему для этого надо сделать?
Для 5 варианта: Чем схожи и чем отличаются серверы Файловый и Коммуникационный?
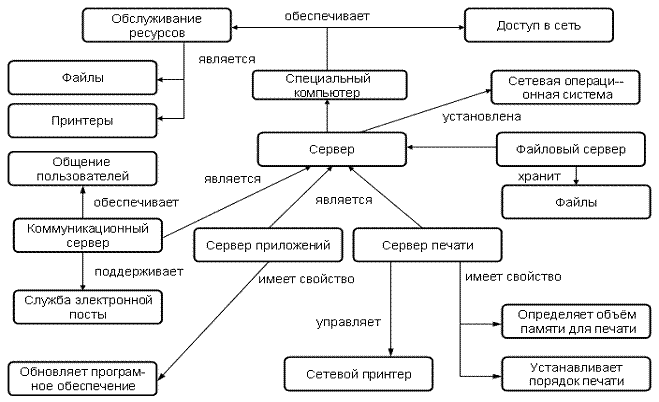
Для 6 варианта: Какими родственными узами связаны Анна и Николай?
Задание 3.
Для 1 варианта:
п
Для 2 варианта:

Для 3 варианта:

Для 4 варианта:

Для 5 варианта:

Для 6 варианта:

Задание 4.
Составить сценарий и по нему построить сетевой граф, иллюстрирующий порядок выполнения операций, для того чтобы:
Для варианта 1: выпустить газету;
Для варианта 2: провести шахматный турнир на первенство колледжа;
Для варианта 3: подготовить и провести в колледже КВН;
Для варианта 4: посадить и вырастить картофель;
Для варианта 5: организовать работу торговой точки;
Для варианта 6: изготовить табурет.
Дополнительное задание.

Контрольные вопросы.
-
Что такое сеть?
-
Где в жизни можно встретиться с сетью?
-
Какая сеть называется семантической?
-
Какую информацию могут носить вершина и дуга семантической сети?