Задача тестировщиков программного обеспечения — изучить работу ПО и выявить несоответствия между ожидаемым поведением, которое указано в требованиях, и реальным поведением ПО в каждом из сценариев использования. В случае если тестировщик находит ошибку в работе в ПО, он пишет специальный отчет об ошибке, чтобы рассказать о нем коллегам, — баг-репорт. Когда коллеги или другие заинтересованные лица изучат баг-репорт, они поймут, в чем дело. Баг-репорт оформляется в специальной системе для отслеживания ошибок — баг-трекере. Каждая команда или компания сама решает, каким именно баг-трекером пользоваться. Теперь перейдем к собственно сути баг-репорта, его составляющих и правилах оформления.
Баг-репорт включает обязательные и необязательные элементы.
Обязательные поля:
- ID — идентификационный номер баг-репорта, должен быть уникальным. Помогает быстро найти нужный баг-репорт.
- Заголовок — передает суть ошибки; помогает быстро понять, в чем дело.
- Шаги воспроизведения — пошаговая инструкция о том, как воспроизвести ошибку.
- Результаты — описание фактического результата и ожидаемого результата.
- Окружение — операционная система, браузер, устройство (в случае мобильного приложения), версия приложения.
- Приоритет — показывает степень критичность ошибки и срочность ее исправления.
Необязательные поля:
- Предусловие — описывает, как систему нужно подготовить перед тестированием (в случае необходимости).
- Постусловие — указывает, как систему нужно вернуть в прежний вид после тестирования (в случае необходимости).
- Описание — прописывают, если в заголовке передано недостаточно информации об ошибке.
- Дополнительные материалы — прикладываются в случае необходимости и помогают проиллюстрировать ошибку (скриншот, скринкаст).
Пример правильно составленного баг-репорта:

Теперь давайте поговорим о каждом пункте немного детальнее.
Заголовок баг-репорта
Задача заголовка — в достаточной мере описать суть проблемы. Грамотно написанный заголовок помогает коллегами сразу понять суть, не тратя время на прочтение всего баг-репорта целиком. Заголовок должен отвечать на три вопроса: «Что? Где? Когда?», при этом не должен быть слишком длинным. Заголовок должен отражать реальный результат.
Примеры удачных заголовков:
- Клик по слову «Регистрация» на странице подписки приводит к ошибке 400.
- При переходе по ссылке «Заказ» на главной странице экрана открывается страница Контакты вместо страницы Мои заказы.
Шаги
В этом пункте прописывается алгоритм действий, которые должны привести к описываемой ошибке. Действия должны быть описаны достаточно полно, но емко, и быть понятными для любого человека вне зависимости от технической подготовки, который попытается воспроизвести ошибку. После написания шагов хорошей практикой будет еще раз пройтись по этому алгоритму, чтобы убедиться, что алгоритм понятен и что ошибка по нему воспроизводится.
Приоритет и серьезность
Приоритет (priority) отражает степень важности проблемы и срочность выполнения задачи, включает 3 уровня:
- Высокий (high) — необходимо исправить в первую очередь, так как с данной ошибкой продукт не выполняет свой бизнес-задачи: например, не работает кнопка заказа в интернет-магазине.
- Средний (medium) — ошибка менее критичная, пользователь может достигнуть цели, однако ПО работает не так, как от него ожидается. Например, в корзине интернет-магазина не отображается блок сопутствующих товаров.
- Низкий (low) — не мешает пользователю достигнуть цели, можно починить после критических ошибок. Например, опечатки в тексте.
Серьезность (severity) показывает степень влияния на работу системы.
- Блокирующий (blocker) — программа не работает. Например, сайт выдает ошибку 500.
- Критический (critical) — не работает важная часть системы, приложение не выполняет своей функции. Например, невозможно добавить товар в корзину незарегистрированному пользователю.
- Серьезный (major) — приложение работает, функциональность не пострадала, однако работает некорректно. Например, не позволяет пользователю выбрать марку авто в приложении по заказу такси.
- Незначительный (minor) — приложение работает правильно, но вызывает какие-либо неудобства. Сюда можно отнести ошибки навигации и другие ошибки UX-характера.
- Тривиальный (trivial) — ошибка, которая не оказывает никакого влияния на работу приложения. Например, опечатки в тексте.
Окружение
В этом пункте описывается среда, в которой произошла ошибка. Операционная система и ее версия, браузер и его версия, версия приложения, размер экрана (если необходимо). Если ошибка произошла на мобильном устройстве, также указывается тип устройства и его модель.
Вложения (вспомогательные материалы)
Помогают дополнить информацию о проблеме, визуализируют ошибку. К баг-репорту можно прикрепить:
- Скриншоты и скринкасты
- Логи, дампы
- Переписки
- Документацию

Не забывайте давать вложениям понятные названия. Можно использовать маску {ID баг-репорта}_{суть ошибки}.
Чтобы прокачаться в тестировании и научиться находить самые каверзные баги, приходите учиться в OTUS.
- Краткое описание проблемы
- Продукт
- Платформа
- Статус
- Приоритет
- Серьезность
- Предусловия
- Шаги воспроизведения
- Фактический результат
- Ожидаемый результат
- Прикрепленные файлы
Среди всех вещей, связанных с тестированием, есть кое-что, с чем тестировщик сталкивается ежедневно. Это баг-репорт: документ, описывающий баг, его серьезность и приоритет, а также шаги, позволяющие его воспроизвести. Опираясь на баг-репорты, разработчики могут быстро определить, какая часть кода работает неправильно, и исправить ее.
Хорошо написанный баг-репорт гарантирует эффективное сотрудничество между командами разработчиков и тестировщиков. Поэтому умение писать баг-репорты — один из самых важных навыков тестировщика.
Как же писать баг-репорты, чтобы разработчики были ими довольны? В этой статье вы найдете несколько советов.
Как написать хороший баг-репорт
Когда дело касается написания документации, есть одно универсальное правило: пишите попроще. Чем проще, тем лучше.
Но «попроще» не значит «покороче». Баг-репорты должны содержать подробности, позволяющие читателю понять природу бага. То есть в них должно быть достаточно сведений, чтобы понять, почему описываемое поведение — баг, и как его воспроизвести. Вместе с тем нужно стараться не включать в баг-репорт лишнего и не повторяться.
Что же мы подразумеваем под «хорошим» баг-репортом? Мы можем сказать, что баг-репорт эффективен, если:
- багу присвоен уникальный номер
- баг можно воспроизвести, это не единичная случайность
- описание бага конкретное и касается только одной проблемы.
Не пытайтесь использовать баг-репорт как доказательство того, что кто-то совершил ошибку. Указывайте только значимую информацию и придерживайтесь нейтрального тона. Всегда перечитывайте то, что написали, прежде чем отправить.
Непременно воспроизведите баг два-три раза, прежде чем начать его документировать. Не включайте в репорт больше одного дефекта. Наконец, прежде чем написать репорт о новом баге, убедитесь, что его нет в списке уже известных багов (чтобы избежать дублирования).
Структура баг-репорта
1. Краткое описание
В идеале, описание бага должно раскрывать ответы на три вопроса: что, где и когда. Например: «(что?) Появляется Console Error (где?) во вкладке Статистика (когда?) после того, как пользователь нажимает на кнопку Скачать». Иногда часть «где» можно опустить. Например: «Приложение падает после того, как пользователь нажимает на кнопку Войти». Можно указать страницу, на которой это происходит. Но если у вас есть единственное место, где пользователь может найти эту форму, то и так очевидно, где он нажимает на кнопку.
2. Продукт
В этой части обычно пишется версия сборки, которая тестируется. Тестировщик указывает эту информацию, чтобы разработчик мог сравнить последнюю, тестируемую версию продукта с предыдущей и посмотреть, что изменилось. Благодаря этому куда легче найти причину поломки.
3. Платформа
Тестировщик должен указать, на какой платформе проявляется баг. Для десктопных проектов укажите операционную систему. Для веб-проектов — самые важные сведения о браузере. Что касается мобильных проектов, для них нужно указать модель девайса и его операционную систему.
4. Статус
Указание статуса бага помогает держать всю команду в курсе процесса исправления. Статус может сообщать о том, что разработчик принял баг в работу, вернул на повторное тестирование, исправил и закрыл и т. п. Количество возможных статусов зависит от принятого в команде рабочего процесса.
5. Приоритет
Приоритет бага показывает, насколько критичен дефект для бизнеса, и определяет очередность исправления. Обычно приоритет устанавливают менеджер продукта, собственник продукта или тимлид.
6. Серьезность
В отличие от приоритета, серьезность определяется тестировщиком. Устанавливая уровень серьезности, он исходит из того, насколько опасен баг для всей системы, в какой степени он затрагивает самый важный функционал и т. п.О серьезности и приоритетности багов можно почитать в статье «Серьезность и приоритет багов — в чем разница?»
7. Предусловия
В предусловиях описываются действия, которые нужно выполнить, и параметры, которые нужно применить перед выполнением шагов, позволяющих воспроизвести баг. Это описание не имеет какого-то четкого формата, просто придерживайтесь логического порядка.
8. Шаги воспроизведения
Наилучший способ описать эти шаги — составить пронумерованный список с последовательностью действий пользователя, приводящих к проявлению бага. Используйте простые предложения.
Например:
- Пользователь открывает вкладку Статистика.
- Нажимает на кнопку Сохранить.
- Обновляет страницу.
- и т. д.
9. Фактический результат
Фактический результат — это проблема, появляющаяся, когда пользователь выполняет шаги, указанные выше.
Опишите результат, придерживаясь того же правила, что и для краткого описания бага. Обозначьте, что происходит, где и когда. Это поможет разработчику понять, в чем проблема. Лаконичное и четкое описание пригодится и QA-команде в будущем.
10. Ожидаемый результат
В этом разделе опишите ожидаемый результат шагов, описанных в п.8. То есть изложите, как приложение должно было бы себя вести.
Ошибка тоже может быть ожидаемым результатом — если тестировщик проверяет негативный сценарий. Например, если пользователь вводит неправильные учетные данные, он не должен войти в систему, вместо этого он должен увидеть сообщение об ошибке.
11. Прикрепленные файлы
Это дополнительные материалы, которые можно добавить к баг-репорту. Часто с визуальными руководствами бывает проще воспроизвести баг. Особенно, если баг сложно описать словами.
Добавление скриншотов или коротких видео поможет избежать недопонимания. Только не забывайте, что визуальные материалы должны быть релевантными и понятными.
Итоги
Документацию нужно создавать так, чтобы она была легкой в использовании и понятной другим членам команды. Такая документация сэкономит вам много времени в будущем, когда проект разрастется, а в команде появятся новички.
Теперь вы знаете, как написать баг-репорт. Более того: вы знаете, как написать его так, чтобы разработчики были довольны. Сохраните себе этот план и пользуйтесь им в работе!
О чем эта статья
Эта статья продолжает цикл «Первые шаги в разработке на 1С». Прочитав ее, вы узнаете:
- Куда обращаться в случае подозрения на ошибку платформы, 1C.EDT и PostgreSQL 1C?
- Что и как писать в вашем обращении?
- Где и как посмотреть существующие ошибки?
Применимость
В статье рассматривается порядок регистрации ошибок платформы «1С:Предприятие» 8, 1C.EDT и PostgreSQL 1C. Информация актуальна для текущих релизов указанных продуктов.
Как в 1С регистрировать ошибки
Сегодня речь пойдет об ошибках. Но не о тех, которые допускают программисты в коде, а об ошибках самой платформы, среды разработки 1C.EDT и отдельной сборки PostgreSQL 1C.
К сожалению, сталкиваясь с ошибками в указанных продуктах, большинство программистов не обращают на них внимания. Они вспоминают 1С недобрым словом, и с мыслями «да они уже в курсе, в следующей версии поправят» продолжают работать. Надеемся, после прочтения статьи таких программистов станет меньше.
В этой статье мы рассмотрим несколько реальных ошибок, примеры обращений в фирму 1С, а также то, как можно отслеживать исправление ошибки.
Примеры будут рассмотрены для мобильной платформы. Впрочем, порядок регистрации для настольной платформы практически не отличается.
Для регистрации ошибок существует три адреса:
- v8@1c.ru
- testplatform@1c.ru
- betaplatform@1c.ru
Первый адрес – v8@1c.ru. Это первая линия поддержки и консультаций по продуктам. Также используется для вопросов по типовым решениям, лицензированию и т.п. Важно отметить, что все продукты, по которым принимаются обращения на этот адрес, должны иметь статус финальных. Кроме того, перед обращением следует проверить, не была ли зарегистрирована данная ошибка ранее.
При расследовании проблемы, в случае если на демо-базе не удастся воспроизвести ваш проблемный кейс, на данный адрес могут попросить прислать выгрузку базы, на которой наблюдается проблема. Если у вас нет возможности предоставить базу, на которой воспроизводится проблема (не разрешает заказчик, нет доступа к конфигуратору, нет прав, у базы слишком большой размер и т.д.), то максимально подробно смоделируйте вашу ситуацию на демо-базе. Рекомендуем написать очень подробный текстовый сценарий воспроизведения вашей проблемной ситуации со скриншотами. Если есть возможность записать все в формате видео, то запишите – лишним точно не будет!
Учитывая то, сколько обращений поступает в фирму 1С за один день, скорость ответа может быть не мгновенной, т.к. ваше обращение некоторое время будет находиться в очереди, после которого вам должно прийти сообщение о том, что письмо принято и переадресовано разработчикам, а сам ответ от разработчиков поступит позже.
Для отправки писем на этот адрес нужно иметь действующую подписку ИТС.
Второй адрес – testplatform@1c.ru. Представляет куда больший интерес. Он предназначен только для регистрации обращений, связанный с тестовыми версиями платформы (ошибки в финальных версиях, не воспроизводящиеся в крайних тестовых версиях также не регистрируются).
Скорость ответа через данный канал на порядок выше – на письмо, отправленное в будний день, в течение часа приходит ответ и регистрируется ошибка.
Также не требуется подписка ИТС, поэтому Вы можете свободно регистрировать ошибки, обладая учебной версией платформы. Единственное условие – платформа должна быть тестовой.
Следует отметить, что в отличие от v8@1c.ru, по данному адресу не предоставляются никакие консультации, а также не принимаются ошибки типовых конфигурации, если они не являются ошибками платформы.
Для обращения по этому адресу нужно выполнить следующие действия:
- Указать версию тестовой платформы. Понять, тестовая версия или нет, можно, просто заглянув на releases.1c.ru и убедившись, что данная версия находится в статусе как версия для ознакомления.
- Максимально подробно по шагам описать сценарий воспроизведения ошибки. Идеально, если вы запишите это в формате видео. Здесь рекомендуется описывать воспроизведение ошибки так, чтобы человек, который будет пытаться её повторить, сделал бы это без уточняющих вопросов. Если вы работаете в коллективе, попробуйте ваше описание отдать коллеге и понаблюдать, сможет ли он воспроизвести ошибку по вашему сценарию без обращения к вам. Если да – работа сделана! Если нет, то нужно попытаться более качественно подготовить информацию об ошибке. И не забываем, что если в вашем сценарии платформа сваливается в дамп, обязательно отправляйте и его тоже.
- Указать сведения о рабочем окружении, на котором воспроизводится ошибка: вариант развертывания базы (файловый/клиент-серверный), тип клиента, версию ОС, СУБД, если ошибка по мобильному клиенту/платформе, то название устройства, и т.д.
Третий адрес, betaplatform@1c.ru, следует использовать при обнаружении ошибки в предварительной бета-версии продукта, до выпуска тестового релиза. Как правило, этот адрес используется для конструктивной обратной связи по новому функционалу бета-продукта.
Правила обращения на указанный адрес аналогичны обращениям на testplatform@1c.ru с возможным указанием каких-то неудобств в продукте, отсутствующей на ваш взгляд функциональности, сценариев работы и т.д.
Также отметим, что при регистрации ошибок через любой из этих трех каналов важно соблюдать принцип: «одна ошибка – одно обращение». Не следует в одном письме описывать сразу несколько ошибок, на такое обращение Вы получите отказ.
Кроме того, выше речь шла о платформе, но ровно то же самое справедливо и для 1С:EDT и PostgreSQL 1C. Обращения по указанным каналам регистрируются по тем же самым правилам.
Нам кажется, что будет уместно дать еще один небольшой совет по этой теме в ключе планирования перехода с одной версии платформы на другую.
Допустим, ваш продуктовый контур работает на платформе 8.3.14, а вы планируете в недалеком будущем поднять версию платформы до актуальной. На момент написания этой статьи финальная версия платформы 8.3.16, а версия для ознакомления (тестовая) 8.3.17. На какой версии тестировать переход? На финальной 8.3.16 или на ознакомительной 8.3.17?
Правильнее, с нашей точки зрения, для тестирования перехода использовать именно ознакомительный старший тестовый релиз 8.3.17 и вот почему. Ваше тестирование на реальных данных, на реальных рабочих кейсах, возможно, выявит какие-то проблемные кейсы, о которых вы хотели бы сообщить отделу разработки. В этом случае, как описано выше, вы отправляете обращение на testplatform@1c.ru. Если проблема подтвердится, то с большой долей вероятности можно утверждать, что в финальной версии 8.3.17, она уже будет исправлена.
Если же вы будете тестировать переход на финальной 8.3.16, то эти же самые действия вы будете делать позже, при переходе на финальную 8.3.17, но время реакции на ваше обращение, скорее всего, будет выше, т.к. зарегистрировать обращение через testplatform@1c.ru уже не получится и вы будете ждать вашей очереди на v8@1c.ru, оставаясь при этом на версии 8.3.16.
Примеры обращений в тех. поддержку 1C
Рассмотрим несколько примеров обращений в тех. поддержку.
Пример 1. В управляемых формах есть возможность группировать элементы на разных страницах. На мобильной платформе это работает в точности, как и на настольной:
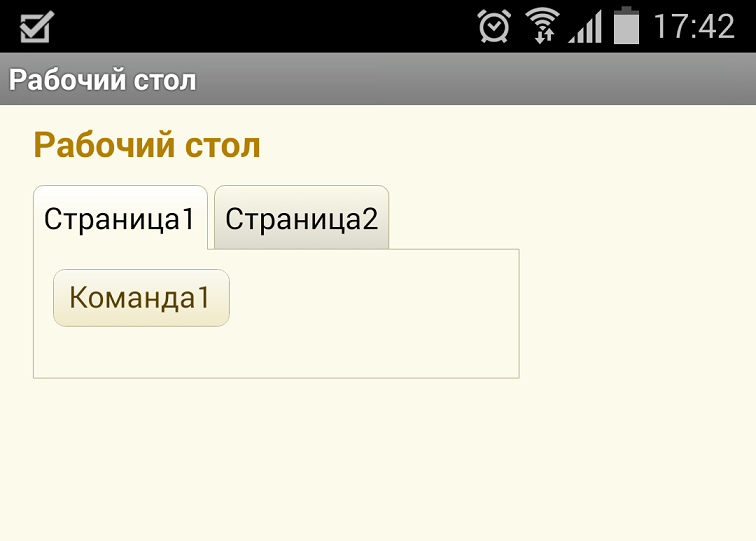
На скриншоте заголовки страниц размещены сверху. Однако если разместить их, например, слева, то начинаются проблемы.
Вот, как это выглядит на настольной платформе:

А так – на мобильной:
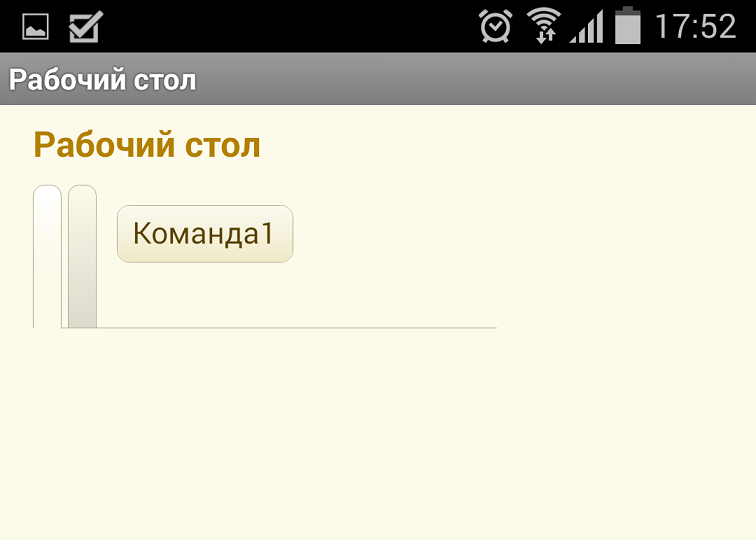
Думаю, ошибка очевидна.
Начнем с подготовки базы. Делается это для того, чтобы не вынуждать сотрудников 1С самих создавать базу и воспроизводить указанную ошибку. Ведь нужно учитывать, что Вы далеко не единственный разработчик, который к ним обращается.
Создаем пустую базу, создаем форму в Общих формах. На форме рисуем простейший пример – 2 страницы с одной кнопкой на каждой из них.
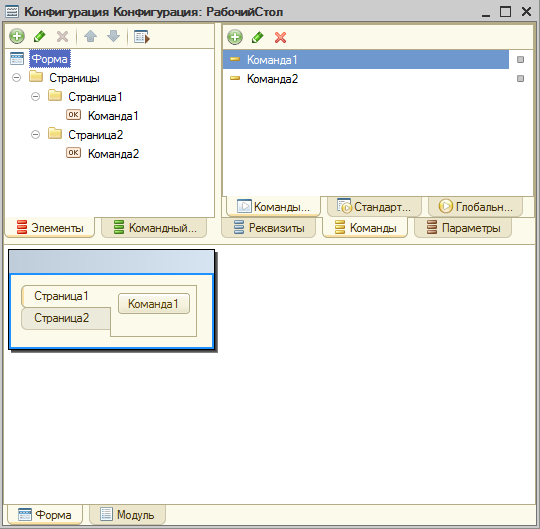
Запускаем базу на мобильном устройстве, делаем скриншоты. Выгружаем базу в dt.
Теперь перейдем к написанию письма. Вот пример моего обращения:
Тема: Мобильная платформа: неверное отображение вкладок
Текст письма:
Добрый день!
Мобильная платформа: 8.3.5.52
В мобильной платформе не корректно отображаются страницы с вариантом отображения «Закладки слева». Воспроизводится на Samsung Galaxy S2 и S4.
Во вложении – пример базы, в которой возникает ошибка.
—
С уважением, Вадим Невзоров
Вложения:
Страницы.dt
Скриншот страниц.jpg
Не забудьте в письме указать версию мобильной платформы. Также не лишним будет указать устройство, на котором воспроизводится ошибка.
Спустя полчаса получаем ответ:
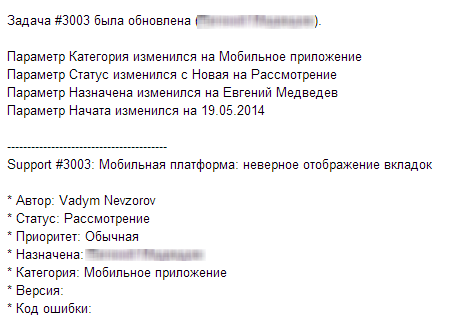
Это означает, что письмо было принято, и сейчас ошибка рассматривается. Спустя 10 минут приходит еще одно сообщение:
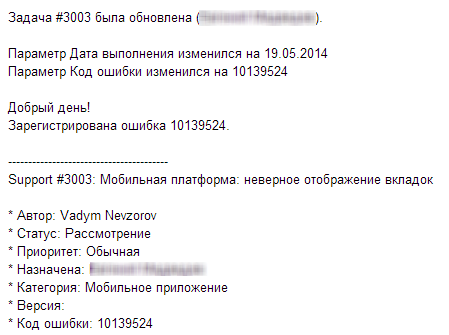
Отлично, ошибка зарегистрирована! Более того, у нас есть ее номер. Что с ним делать дальше?
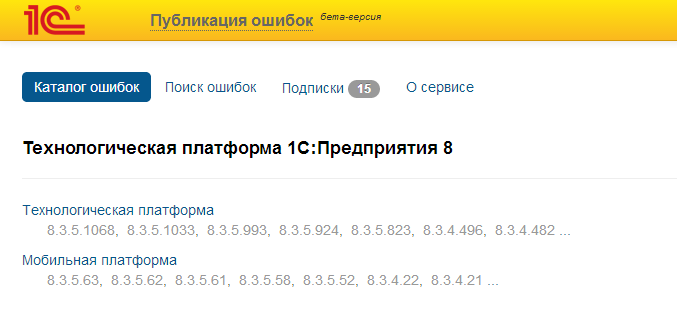
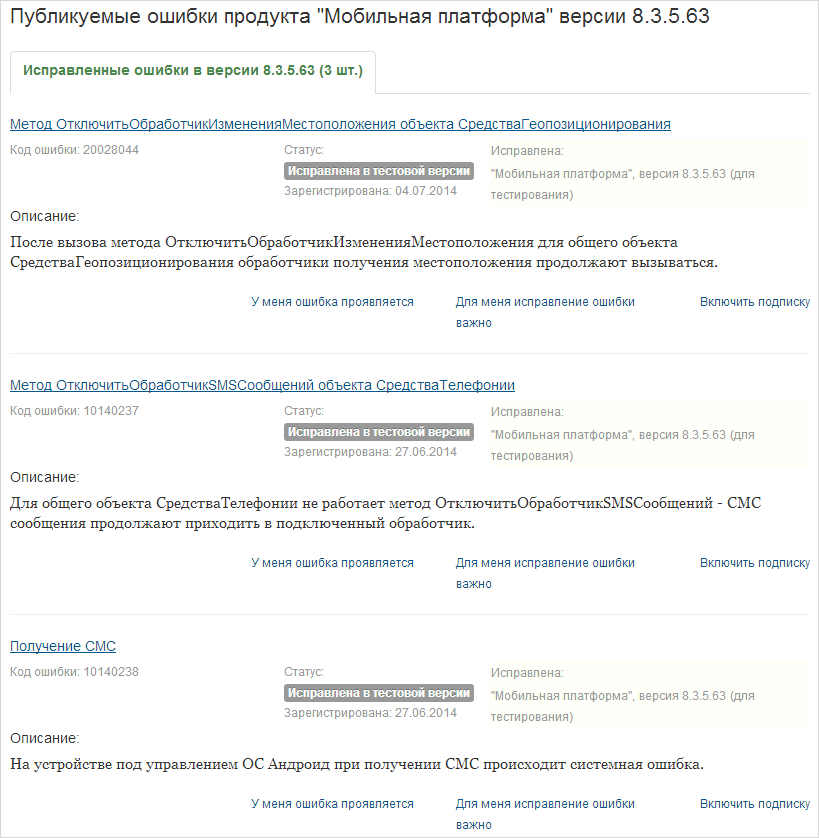
На сайте 1С есть специальный раздел «Публикация ошибок» – https://bugboard.v8.1c.ru/ (доступен только тем, у кого есть подписка ИТС). В этом разделе можно отслеживать исправленные и неисправленные ошибки для разных версий настольной и мобильной платформы.
Страница «Поиск ошибок» предназначения для удобного поиска нужной ошибки. Ошибки можно искать по коду, номеру обращения (если обращение было через адрес v8@1c.ru) и по словесному описанию.
Например, в предыдущих версиях мобильной платформы на моем телефоне Samsung Galaxy S4 была неприятная ошибка – при попытке сделать фото с помощью метода СредстВамультимедиа.СделатьФотоснимок(), устройство полностью уходило в перезагрузку.
Попробуем найти ошибку по строке «Galaxy S4».
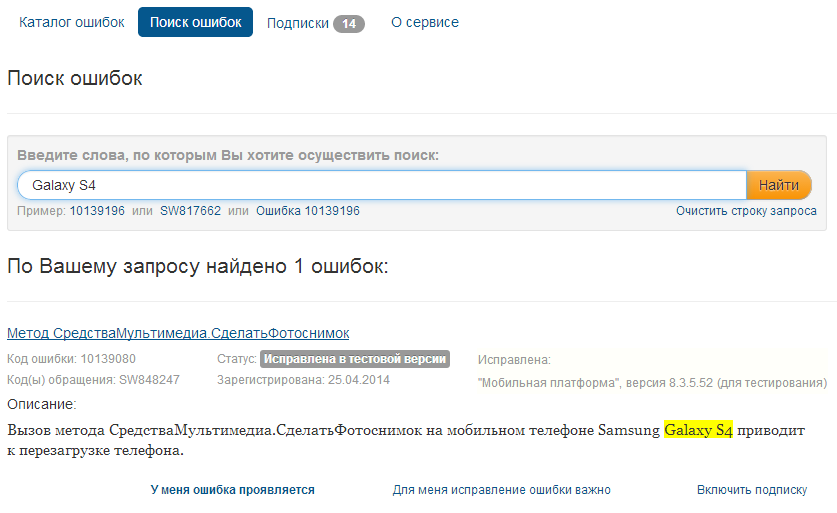
Как видим, такая ошибка уже зарегистрирована, и была исправлена в тестовой версии платформы. Помните, прежде чем регистрировать ошибку, сначала попробуйте найти ее в этом разделе – возможно, ее регистрировали ранее.
Обратите внимание на ссылки внизу. Первые две предназначены для определения приоритетов – чем больше человек сообщит о важности ее исправления, тем быстрее (теоретически) она будет исправлена.
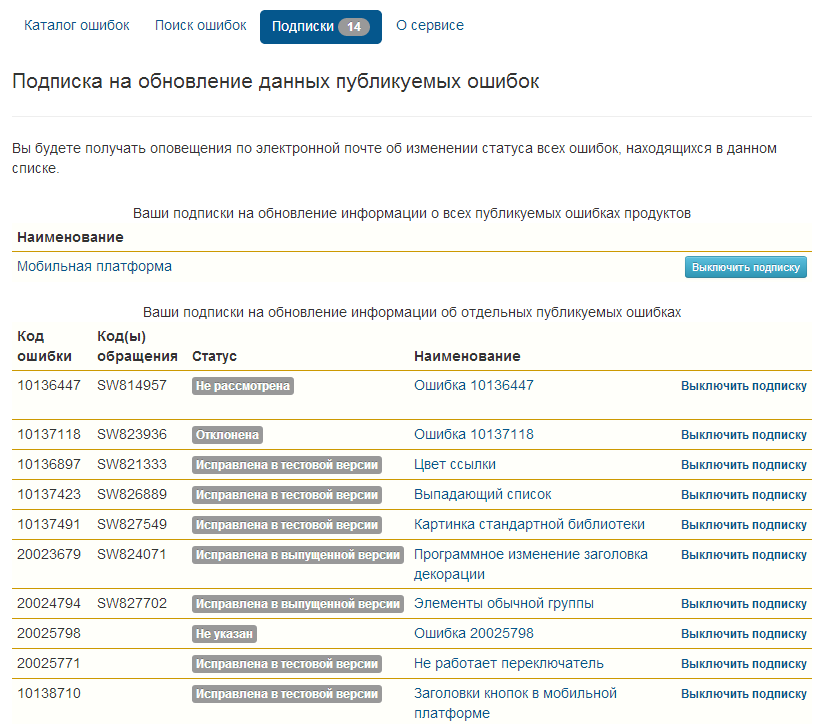
Ссылка «Включить подписку» нужна для удобного отслеживания ошибки.
Чтобы каждый раз не искать по словам, можно «подписаться» на ошибку, после чего она будет отображаться в разделе «Подписки».
Так этот раздел выглядит в нашем случае:
Вернемся к нашей зарегистрированной ошибке. Попробуем найти ее по коду из письма:
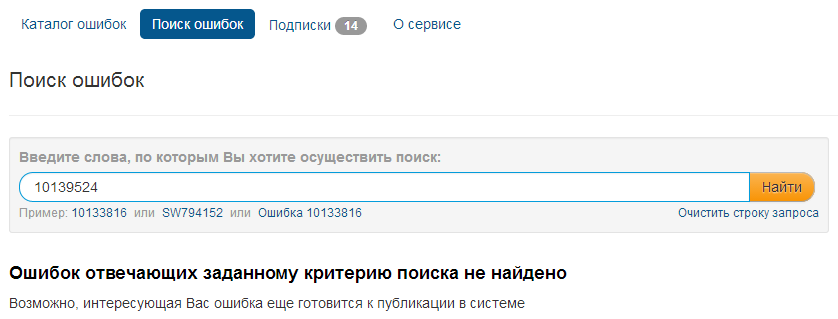
Видим, что ошибка с таким номером не найдена. Такое бывает, так как информация об ошибках появляется не сразу.
Причем в некоторых случаях процесс может очень затянуться – приведенная в данном примере ошибка была зарегистрирована 19 мая, однако до сих пор (на момент написания статьи – 10 июля) не выложена на сайт.
Но это просто неудачный пример. В любом случае, рано или поздно ошибка будет опубликована и исправлена.
Рассмотрим еще один пример обращения.
Пример 2. Как известно, в мобильной платформе 8.3.5 добавили средства работы с SMS-сообщениями.
Можно отправлять и получать сообщения, смотреть содержимое, прикрепленные файлы (для MMS) и т.п.
При этом нельзя читать сообщения, хранящиеся в памяти телефона – можно только подписаться на появление новых сообщений, пока работает 1С.
Делается это так:
ПолучательСообщений = Новый ОписаниеОповещения(«ПолучениеСообщения», ЭтотОбъект);
СредстваТелефонии.ПодключитьОбработчикSMSСообщений(ПолучательСообщений);
Метод ПодключитьОбработчикSMSСообщений подключает обработчик ожидания, который срабатывает в момент прихода нового сообщения.
Есть и другой метод – ОтключитьОбработчикSMSСообщений, который выполняет обратное действие.
Проблема только в том, что он не работает – после вызова этого метода, обработчик всё равно продолжает вызываться при получении сообщений.
Создаем простейший пример – форму с двумя кнопками подключения и отключения обработчика SMS-сообщения.
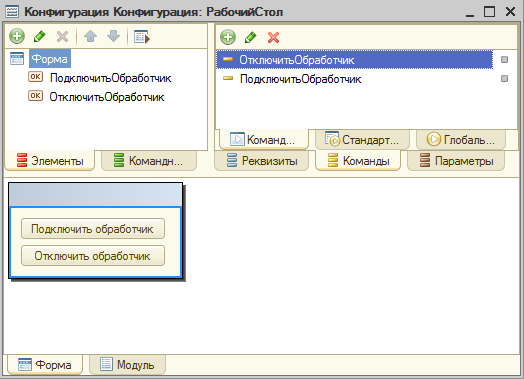
Исходный код модуля:
&НаКлиенте
Процедура ПодключитьОбработчик(Команда)
ОП = Новый ОписаниеОповещения(“ПолученоСообщение”, ЭтаФорма);
СредстваТелефонии.ПодключитьОбработчикSMSСообщений(ОП);
КонецПроцедуры
&НаКлиенте
Процедура ОтключитьОбработчик(Команда)
ОП = Новый ОписаниеОповещения(“ПолученоСообщение”, ЭтаФорма);
СредстваТелефонии.ОтключитьОбработчикSMSСообщений(ОП);
КонецПроцедуры
&НаКлиенте
Процедура ПолученоСообщение(Сообщение, Параметры) Экспорт
Предупреждение(Сообщение.Текст);
КонецПроцедуры
Пишем письмо:
Тема: Мобильная платформа: не работает отключение обработчика получения сообщений
Текст письма:
Добрый день!
Мобильная платформа: 8.3.5.58
Платформа игнорирует отключения обработчика ожидания для получения смс сообщений. После отключения, при приходе смс обработчик продолжает Вызываться.
Во вложении – пример мобильной БД, в которой возникает ошибка. Воспроизводится на Samsung Galaxy S2 и S4.
—
С уважением, Вадим Невзоров
Вложения: СМС сообщения – отключение обработчика.dt
Получаем ответ:
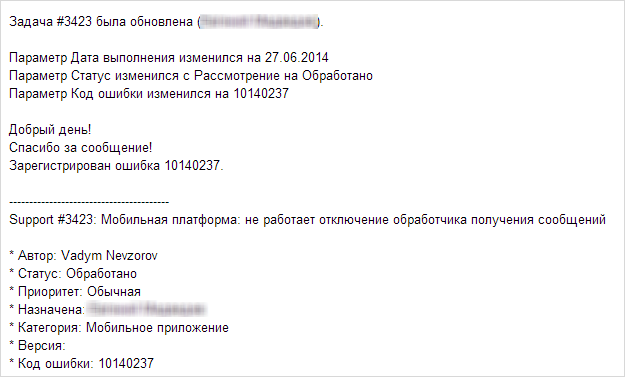
Идем на сервис публикации ошибок, ищем нашу ошибку:
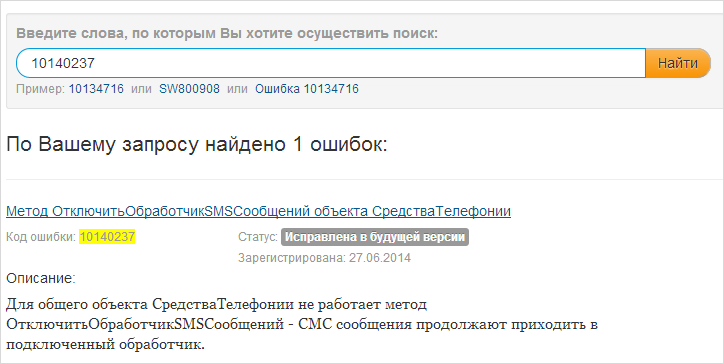
Теперь ошибка есть на сайте, и мы можем отслеживать ее статус. В дальнейшем, при выходе следующих версий мобильной платформы, мы сможем отследить, в какой из версий он была исправлена.
Возможно, после прочтения статьи у Вас возникнет вопрос – зачем это все? Ведь у фирмы 1С есть свой отдел тестировщиков, и рано или поздно ошибку выявят и исправят.
Однако, согласитесь, нет ничего сложного в том, чтобы потратить 15 минут на составление письма, которое поможет 1С быстрее исправить недочеты в продукте. И вместе с тем хочется, чтобы данный продукт становился все лучше и лучше.
За день до написания этой статьи вышла новая версия мобильной платформы – и вот результат:
В заключение отметим, что существует официальная партнерская конференция, в которую имеют доступ сотрудники фирм франчайзи и другие специалисты. Часто начинающие разработчики и их старшие коллеги пытаются зарегистрировать ошибку, создавая пост в данной конференции. Но по правилам данный форум не является ресурсом для разбора и регистрации ошибок. Поэтому для детального расследования ошибки, как мы и писали ранее, свое сообщение следует отправлять в службу технической поддержки пользователей на электронную почту v8@1c.ru. Только в этом случае вам:
- Гарантированно ответят специалисты фирмы «1С»
- Совместно с вами подготовят всю нужную информацию для прояснения и диагностирования ситуации
- В случае признания ошибки направят ваше обращение разработчикам для исправления ошибки.
Иногда специалисты фирмы 1С могут зарегистрировать ошибку на основе обсуждений темы в форуме. Но данная регистрация, во-первых, не гарантирована и нигде не регламентирована, во-вторых, если такая ошибка и будет зарегистрирована, то она считается внутренней и не будет опубликована на соответствующем баг-трекере и вы не сможете отслеживать по ней информацию. Поэтому для расследования ошибки свое сообщение лучше и правильнее отправлять на v8@1c.ru.
Скорее всего, у вас уже возник вопрос, для чего же тогда вообще нужен партнерский форум, раз там нельзя официально регистрировать сообщения об ошибках? В первую очередь он нужен для обмена опытом, идеями и мнениями между специалистами в области поддержки и разработки на платформе «1С:Предприятие 8».
То есть если вам хочется обсудить какой-то вопрос, с которым вы столкнулись на практике, или поделиться своим опытом или мнением, или найти путь решения проблемы, через обсуждение с коллегами, то форум – это правильное место, где все это можно сделать, т.к. вопросы адресуются ко всем его активным участникам. Именно поэтому такой формат и не предполагает никаких регламентных ответов и регламентной процедуры регистрации ошибок.
Поэтому призываем относиться с пониманием к просьбе сотрудников фирмы «1С» регистрировать сообщения об ошибках не через форум, а через названные выше каналы регистрации. Ну и, конечно, поменьше вам ошибок!
Но никакие ошибки не смогут помешать нам продолжать знакомство с возможностями платформы «1С:Предприятие 8», и в следующей статье мы вернемся к изучению управляемых форм. 
Вадим Невзоров,
г. Одесса
PDF-версия статьи для участников группы ВКонтакте
Мы ведем группу ВКонтакте – http://vk.com/kursypo1c.
Если Вы еще не вступили в группу – сделайте это сейчас и в блоке ниже (на этой странице) появятся ссылка на скачивание материалов.

Ссылка доступна для зарегистрированных пользователей)
Ссылка доступна для зарегистрированных пользователей)
Ссылка доступна для зарегистрированных пользователей)
Если Вы уже участник группы – нужно просто повторно авторизоваться в ВКонтакте, чтобы скрипт Вас узнал. В случае проблем решение стандартное: очистить кеш браузера или подписаться через другой браузер.
Автор: Ольга Киселева, тренер курса Онлайн-интенсив для начинающих тестировщиков
У тестировщика миллион способов завести баг так, чтобы разработчики на него забили. Учитесь ставить такие задачи, которые будут исправлять.
1. Выберите тип
Разработчики не боги, они не могут делать все и сразу. Им нужно понимать, с чего начинать. Они сортируют задачи по типу — сначала новые функции, потом ошибки, потом все остальное.
Какие бывают типы задач:
- Баг — ошибка в программе.
- Улучшение — все ок, но хотим с перламутровыми пуговицами.
- Новая разработка — такой возможности нет, а очень хочется.
Допустим, заказчик захотел новую возможность, а вы завели ее не как новую возможность, а как баг. Разработчики весь месяц делали другие новые функции, и до вашей не добрались. Заказчик в ярости: вы же обещали… А виноват постановщик задачи — умей выбирать тип!
|
Баг |
Улучшение |
Новая разработка |
|
Ошибка 500 при загрузке xlxs файла |
Загружать файлы драг-н-дропом |
Возможность грузить сразу несколько файлов |
|
Город “Москва” исправляется на “Масква” |
Выводить код ФИАС в результатах разбора адреса |
Обработка иностранных адресов |
|
Нет подсказок по букве «Б» на английской раскладке |
Распознавать не переключенную раскладку в подсказках для email |
Транслитерация в подсказках |
|
При загрузке файла большого размера сообщение об ошибке “некорректный тип” |
Увеличить ограничение на размер загружаемого файла до 30Мб |
Загрузка файлов формата .djvu |
Осторожнее с ошибками. Разработчик не любит слышать, что в его детище что-то не так. Он будет топать ногами и кричать “Это не баг и исправлять его не надо”.
Финт ушами — ставьте улучшения вместо некритичных ошибок.

Системный архитектор реагирует на появление ошибки
2. Локализуйте проблему
Локализация — это поиск первопричины.
Не торопитесь заводить конкретную проблему, это ниточка. Потяните за нее и распутайте весь клубок. Если этого не сделать, разработчики исправят последствия, а исходная проблема останется.
Когда мы тестировали систему Дадата, обнаружили, что “Гунько Александр” женского рода. Первая реакция — бегом ставить баг! Хотя нет, постойте…
В чем тут проблема?
Система всех “Гунько” считает женщинами?
Или “Гунько Марина” тоже сменит пол?
А “Иванов Петр” — мужчина?

Младший разработчик локализует свой первый баг
3. Придумайте короткий и емкий заголовок
Упоротый менеджер в 12 ночи просматривает баг-трекер, и он должен по заголовку понять, насколько критично исправить проблему.
Если он пропустит серьезную ошибку из-за непонятного названия, утром полетят головы. Если он поднимет панику из-за несерьезной задачи, он выставит себя дураком. И сильно обидится на того, кто ставил задачу. Если он не поймет из названия, в чем проблема, задачу закроют, даже если там реальный косяк.
Соизмеряйте важность проблемы и название задачи.
|
Нет |
Да |
|
ААААААА, КОШМАР, ВСЕ ПРОПАЛО, НИЧЕГО НЕ РАБОТАЕТ! |
Авторизация через твиттер падает с HTTP 500 |
|
В исследуемой системе при вводе в поле “Имя” символов русского алфавита, английского алфавита, спецсимволов и символов в неправильной кодировке поведение программы неверное |
Падает отправка письма в кодировке UTF-08 |
|
Двойные имена |
Нет подсказок по двойным именам в ФИО |
Если в заголовке появились слова «Ошибка», «Неправильный», «Некорректный», «Неверно» — перепишите заголовок. Вы заводите задачу с типом «Ошибка» — уже понятно, что что-то работает не так. Объясните проблему: “Можно зарегистрироваться с именем Ктулху”.
Но если вы заводите улучшение, заголовок должен предлагать, а не ставить перед фактом: “Запретить регистрацию с именем Ктулху”
|
Баг |
Улучшение |
|
Можно зарегистрироваться с именем Ктулху |
Запретить регистрацию с именем Ктулху |
|
Сообщение об ошибке указывает на неверный пароль при вводе недопустимого имени |
Выводить в сообщение об ошибке детальную информацию по причине |
|
Нет подсказок по двойным именам в ФИО |
Выводить подсказки по двойным именам в ФИО |
|
Можно зарегистрироваться с паролем 123 |
При регистрации добавить проверку небезопасных распространенных паролей |
|
Нельзя загружать несколько файлов сразу |
Обрабатывать загрузку нескольких файло |
3. Приложите скриншот
Первое, что цепляет взгляд — это картинка.
Иногда разработчику достаточно названия и картинки, чтобы понять, где проблема.
Когда ставишь задачу, скриншот делать лень. Кажется, что и без него все понятно. Но баги не всегда исправляются сразу. Спустя месяц изменится интерфейс и без скриншота будет непонятно, о чем речь в задаче. Картинка поможет тестировщику увидеть “как было до”, чтобы сопоставить с настоящим.
На картинке не должно быть ничего лишнего. Если нужна только маленькая часть экрана — прикладывайте ее, а не весь рабочий стол. Если скриншот получается большим, выделите в нем область, на которую надо смотреть, например, нарисуйте стрелочку.

↓

4. Опишите шаги воспроизведения и результат
Если названия и скриншота недостаточно, разработчик читает шаги воспроизведения. Что ему нужно сделать, чтобы увидеть проблему?
Шаги — короткие, емкие и последовательные. Разработчик должен выполнить их, а не задумываться над тем, что и в каком порядке ему делать.
Если шаги непонятные, разработчик не станет в них разбираться. Ему это не нужно. он закроет задачу: “не воспроизводится”. Увы, на баг забили!
Все знают, что шаги должны быть короткими и емкими. На практике мои студенты ударяются в 2 крайности — слишком кратко или слишком длинно.
Слишком кратко → когда нужно тратить время, чтобы понять, о чем речь. Студенты думают, что у разработчика уже открыт сайт на нужной странице, поэтому пишут просто “Сделай так!”. Но разработчик может вести сразу несколько проектов и такие шаги ставят в ступор. Где сделай? Что за проект? В каком месте системы этот раздел находится? Где ссылки, в конце то концов??
Слишком длинно → когда поленились локализовать. Бродишь по сайту, отчаявшись найти проблему, и вдруг… ОШИБКА! Первое стремление — скорее, скорее ее завести. Кажется, что все действия крайне важны. Даже если они не имеют реального отношения к проблеме. Ведь так воспроизводится? Заводим!
|
НЕТ |
ДА |
|
Загрузить файл с опечатками в email-ах |
|
|
|

Как для разработчика выглядят шаги воспроизведения бага
5. Обоснуйте ожидаемый результат
Раз вы ставите баг → вы считаете, что в системе есть проблема. Но почему это проблема? И для кого? Насколько она реальна?
Недостаточно сказать “поле email должно быть 23 символа” — а с чего вы взяли? Вспомните, что такое баг и обоснуйте свои ожидания.
У разработчика и тестировщика разные взгляды на проблемы. То, что мешает тестировщику, разработчик считает нормальным поведением. И если его просто ставить перед фактом: “Это баг, исправляй!”, пощады не ждите. Разработчик не станет бегать за автором с вопросом “А почему это проблема? Объясни, пожалуйста”. Он просто закроет баг.
Опишите сценарий использования, в котором возникает ошибка. Покажите, что в другом похожем месте система ведет себя по-другому (неединообрзно → плохо!). Дайте пруфлинки.
|
НЕТ |
ДА |
|
Увеличить поле “Имя” до 30 символов. |
Увеличить поле “Имя” до 50 символов, так как туда часто вводят ФИО целиком и оно обрезается. |
|
Исправлять непереключенную раскладку в подсказках по ФИО |
Исправлять непереключенную раскладку в подсказках по ФИО, как это уже сделано в подсказках по адресам и организациям. Сейчас система работает неединообразно |
|
Адрес “Россия, Москва, Большая Пироговская улица, 37-43кб” разбирается корректно. |
Адрес “Россия, Москва, Большая Пироговская улица, 37-43кб” разбирается корректно, потому что такой вариант записи диапазонных домов нормален. И этот адрес существует, см http://maps.yandex.ru/-/CVGIMR3g |
———————————————————————————————
Тотальная паранойя — друг тестировщика!
Конечно, даже идеально поставленную задачу не всегда исправят. Но лучше поставить задачу, чем не ставить. Пусть хранится для истории.
Позвольте рассказать историю, после которой я записываю все баги, даже те, которые мне приснились.
На прошлом месте работы я успешно справлялась с тестированием своего проекта и подключилась на самый большой проект в компании. Проект я еще не знала, поэтому с вопросами сначала шла к аналитикам — баг это или не баг? Или к разработчикам, если вопрос касался технической стороны.
Как-то раз нашла я проблему и пришла к главному разработчику — баг? Он отмахался от меня: «Нет нет, все ок, это не баг. Так и должно работать». А через две недели прибежал к тестировщикам с выпученными глазами и начал кричать «Тестировщики лентяи, такую багу пропустили!!!». Пропущенным багом оказалась… Та самая проблема.
— Погоди, я же тебе ее уже показывала, ты сам сказал, что это не баг.
— Не было такого! Вы лентяи, такую бажину пропустили!
И не докажешь уже, что не индюк, не записано
PS — статья написана в помощь студентам моего курса для начинающих тестировщиков.
To follow on from the car analogy, I’ve used the following in other contexts:
Say you took your car into the mechanic and said the battery keeps dying. He runs thorough tests on the battery and the electrical system and finds nothing wrong. The mechanic asks you how to reproduce the problem and you get annoyed at the question and say it just happens randomly for no reason. The mechanic digs deeper and eventually discovers you’ve been frequently leaving your headlights on all night, which as a brand new car owner, you didn’t realize would drain the battery.
Now you might say that the car should prevent the battery from dying if you leave the lights on. That’s a reasonable claim, and many modern cars do just that. However, it was still impossible to make the diagnosis without knowing the steps to reproduce the problem. And at least in this case, they mentioned the battery. Some bug reports are like, «my car is broken sometimes but it’s fine now» and they don’t know why you want more detail. Also, the best mechanics will have the conversation first and not even charge you.
It’s not a perfect analogy, because in a computer application, «leaving the lights on» might not have been a user error, but an unintended side effect of another feature, or subtle interaction between two features. You also can add preventative measures and logging even if you don’t precisely know what the cause is. And I would consider a mechanic very poor if they just returned your car without at least having a discussion about possible root causes.
answered Jun 17, 2021 at 13:40
![]()
Karl BielefeldtKarl Bielefeldt
146k38 gold badges280 silver badges475 bronze badges
7
True story: A family has a problem with their new car. Every sunday the whole large family meets for lunch, then someone drives to the ice cream parlor and buys ice cream for everyone. And then a strange thing happens: Whenever they buy vanilla ice cream, the car’s engine won’t start. If they buy any other ice cream, the car’s engine starts. Mechanics couldn’t find a fault.
Finally, the family invited someone quite higher up from the manufacturer for sunday lunch. And the guy drove with them to the ice cream parlor, vanilla ice cream was ordered, and the engine wouldn’t start. This guy would have made an excellent software tester: He checked out the ice cream parlor. It turned out that they had a huge tub of vanilla ice cream that could be served quite quickly, while any other ice cream took longer. The fault had nothing to do with the ice cream flavour, but with how long the engine was turned off. Once they could reproduce the problem, the fix was easy.
But in the end, a bug that appears always and under all conditions is easily fixed. These bugs are most likely already gone before a tester ever sees the software. What is hard is problems that only happen under certain circumstances, and that will not appear 99% of the time. In that case, your bug report is not helping at all if you can’t describe how you got the 1% case.
Good tools would also allow you to specify how reproducible a bug is. You may have a bug that even with your best efforts can only be reproduced 10% of the time. What does that mean? It means the developer won’t give up if he tried it out three times and the bug didn’t appear if he knows it is rare.
And when you write down steps to reproduce a bug: Consider that a developer cannot read your mind. If you don’t write it down, he doesn’t know about it. If you are not precise, he doesn’t know what you are doing. If you are inaccurate, the bug may not be reproducible at all with your description.
PS. I’ve had bugs that would only happen to testers or even specific testers. For example: Tester does step 1, checks the screen, compares it to what his script says, does step 2, checks the screen etc. And there’s a bug that only happens when you do step 1, 2, 3 and 4 several seconds apart, by the exact right amount. A second tester writes down the results, therefore takes longer, bug disappears. The developer knows all the steps, does them quickly in a row, bug disappears. Developer and Tester 2 go to Tester 1’s desk and see him reproduce the problem. They ask him to do it slower, problem goes away. They ask him to do it faster, problem goes away. He does it at his own speed, bug comes up. This does happen.
answered Jun 17, 2021 at 14:18
![]()
gnasher729gnasher729
39.8k4 gold badges55 silver badges108 bronze badges
6
Complexity and discoverability.
The mechanic fixes dozens of cars which are basically the same every single day. He has a list of tests, which is reasonably fast to check and covers detecting all expected and most unexpected defects.
Still, if the right back side flutters a bit beyond 50 mph, that’s unlikely to be covered unless the driver highlights it. Actually, unless it is for the mandatory regular general inspections, not trying to describe your concerns to make sure they are addressed is at best odd, at worst irresponsible.
The software engineer has a far more amorphous test-target. First, it is one-of-a-kind. Yes, there is probably an automatic test-harness which is applied, but that that mostly covers the nuts and bolts, not the user-interaction, and it cannot be exhaustive. At least those will all work properly when released, so won’t be reported by the user (anymore). All the inputs, all the dependencies, all the system-configurations, and myriad other outside influences, and on top of that it is hard to anticipate all possible interactions.
The coup de grace is that you cannot look at it, and say you have thoroughly tested everything, as even delineating parts of the application to check is non-trivial, and making sure you hit everything in that part is just about impossible. Try checking the border of an invisible shape for some kind of interaction. Better if that changes dynamically, best if the way you want to interact depends on that dynamic change. Try testing an ai, or anything else with mostly hidden highly dynamic state.
And that left out all the cases where the behavior is as designed and seems reasonable, but actually isn’t, or at least doesn’t help some group of users.
If the user says «Your software has a bug», the only thing the developer can say for moderately complex software is «probably. Where does it hurt, so I can look there.»
And until that information is present, that’s «no repro / cannot fix».
answered Jun 17, 2021 at 12:20
![]()
DeduplicatorDeduplicator
8,4185 gold badges31 silver badges50 bronze badges
5
You can’t fix a problem you can’t see most of the time. It depends in the context of your company BUT the developer will need to reproduce the error so it can be investigated/fixed .
An example:
Reported Bug : The xml response gives the wrong dates for departure times
Reality: The xml response gives the wrong dates for departure times , when the train is from a certain company at a specific station .
If the developer cannot see the specifics of this bug(train company, station) , how is she gonna pin point the error and proceed with appropriate actions ? Imagine there are thousands of trains and stations responses all working properly.
answered Jun 17, 2021 at 13:50
![]()
Lets take your literal question aside for a moment. Your description gives me the impression the core problem is not the bug reports themselves, but the disconnection between the people who notice the bug, and the ones who have to fix them.
Ideally, a user may notice a behaviour of a program which looks like a bug to them, calls the support team, and they use some screen sharing tool, or screenshots, and real data to reproduce the issue, so the support team member can either help the user directly, or come to the conclusion they need to get a dev involved.
But if they cannot reproduce the issue together, the support team member can already close the ticket as «cannot reproduce». If they can, the support team member now can call a dev and do the same with them: show them what works wrong — for this, the support team member needs to make sure they can demonstrate the problem, for example, within their test environment. If they now cannot reproduce the issue again, the support team member can either speak to the user again, ask for more information, or close the issue themselves.
But you wrote:
sometimes the support team submit reports without and become frustrated when dev close them as «cannot reproduce / cannot fix»
That gives me the impression the support team member just try to write down their bug reports in words (not necessarily by reproducing the issue together with a user first), they don’t try to reproduce issues in their environment and don’t use screen sharing tools to explain the issue to the devs. And that’s the real problem here — the communication workflow isn’t ideal, there is too much «one way» communication, too much risk for «chinese whisper».
Interestingly, the answer given by @gnat in 2012 was pretty much going into the same direction: there needs to be a good bidirectional communication channel between users, support staff and devs. Of course, as that older other answer points out, such a channel can be established by using written text. Today screen sharing has become standard, it has made support communication a lot simpler. It is not a replacement for written tickets, but has proved itself as terribly useful.
Of course, reproducability is not only important for this communication chain, it is also important for the dev to be able to verify a bug fix works, but you asked for the non-dev perspective.
answered Jun 17, 2021 at 13:42
![]()
Doc BrownDoc Brown
192k33 gold badges354 silver badges541 bronze badges
3
To look at this a slightly different way:
When a tester fills out a bug report, they typically can’t write down exactly what the problem is. They write their interpretation of the problem. When a developer starts working on that ticket, they base their work on their interpretation of what the tester wrote. At each step, there’s lots of room for error due to poor communication, faulty assumptions about how the program works, or mistaken observations. Reproduction steps describe the problem in an objective way that retains its accuracy, even through multiple layers of non-technical middlemen that may not all be fluent in the same language.
The other aspect is that reproduction steps provide a «definition of done». If I follow the steps and no longer see the problem, then I’ve fixed the issue. Without reproduction steps the situation is ambiguous. Did I fix it? Or am I just not doing the right thing to trigger the problem? It’s hard to say. Situations like this are where you see bugs go through multiple cycles of fixed->re-opened before it gets fixed for good. It saves time for the tester and the developer if the tester provides the reproduction steps up front.
answered Jun 17, 2021 at 22:22
![]()
btabta
9655 silver badges12 bronze badges
A few reasons:
- «Trust, but verify»: A large portion of bug reports are not actually bugs but rather mistaken user conceptions of how software should work. Sometimes, the problem is not even in the software they are complaining about: they mixed up the problem in their mind and remembered the flow incorrectly. Software developers know this, and ask for the reproduction steps as a form of verification. The repro steps offer more concrete proof that the issue is real and affects their software.
- Ease of debugging: As a practical matter, it is much easier to resolve an issue if it can be reproduced consistently. You can attach a debugger and step through each line of code, watching the relevant variables change. Without repro steps, if you don’t intimately understand the relevant code, you might not intuitively know where to find the bug. You might then need to add extra logging to all suspect code and wait for another occurrence.
- Self-education: Developers are often tasked with maintaining code they did not write in a system that they do not use. Repro steps help educate the developer on the context of the problem and how the system is actually used. This is invaluable background that can help them understand potential side-effects of any fix they attempt.
- Future regression testing: With good repro steps, a developer or QA engineer can more easily write an automated or manual test that can be added to the system to prevent future regressions of this bug.
I should also add that the car mechanic analogy is flawed because good auto mechanics do, in fact, ask for repro steps for issues that are intermittent or hard to diagnose.
answered Jun 17, 2021 at 21:45
![]()
There are two somewhat related reasons, I think.
First off, the car mechanic analogy is pretty badly flawed. For one thing, cars wear out in ways that software does not. Also, the mechanic is not the guy who designed and built the car. He (or she) is someone whose job it is to diagnose and repair problems. The role is more akin to QA than design.
Another thing to keep in mind that if someone who’s reporting a bug doesn’t think it’s important to describe the bug carefully, or with reproduction steps, it’s probably because they imagine that the bug is so obvious that no one could fail to miss it after even a cursory inspection. We’ll come back to that.
Finally, of course, just about any modern software application is almost infinitely more complicated than a «simple» automobile. It’s going to have gobs of different features and functions and usage patterns. How one user uses it may have almost no resemblance to how another does.
So the first of my reasons is that, like it or not, developers tend to imagine that their code is perfect. They tried hard to make it so, they tested it before they released it, it passed all its unit tests before they released it. And if nothing else, they know that their code works perfectly when it comes to the things they most commonly test it on. So if you hand a developer a bug report about his code, without much description, imagining it’s obvious, the developer may or may not «put the code through its paces», but if he does, it’s going to be with his preferred usage pattern — the one he already knows it will pass handily. So he’s totally predisposed to say, «Cannot reproduce, user error».
And then the other reason is is that users are probably making more heavy use of the older and more established features, while developers are always working with (designing and implementing and testing and using) the brand-new features that Marketing wanted in the new release. So if (as not uncommonly happens) a new feature inadvertently introduces a bug into an old, long-established feature, and a user notices and complains about it, and even if it is a glaring, showstopping bug that would be immediately noticed by any casual user, it’s still not likely to be noticed by a developer, because the developers never use that old feature any more, they may have forgotten it even existed, because they’re all consumed working on the brand-new features.
So, bottom line, careful descriptions and reproduction steps are necessary because the alternative — just saying, «there’s a bug, it’s obvious, you’ll see it right away» — is too likely to be false.
answered Jun 17, 2021 at 20:20
![]()
4
To add to the other answers, sometimes of course you do have to investigate a problem that you don’t know how to reproduce. We had a customer once with a database corruption, with no idea how it occurred; I was supporting the database software and had to work out a possible sequence of events that could have led to the corruption, working backwards from the symptoms. It took a week, and at the end of it, I had a possible explanation, but no evidence that it was the correct explanation. So the real reason developers ask for a repro is because it reduces the effort needed to find an explanation for the problem, and increases the likelihood that the explanation will be correct.
answered Jun 17, 2021 at 23:00
![]()
1
The Software Bug/Defect might not be a bug with the software itself, but a combination of the Software itself with a specific configuration.
Reproducibility steps do help verify that a specific issue is reproducible, and raises flags to the mechanic if, for example, you tell him the car doesn’t have its steering wheel working properly on the road, but it does work in the mechanic’s shop when they test the car there.
This could be thought of as similar to browser compatibility issues with a web based application (i.e. the «It works in newer browsers, but not in the browser the client is using» problem), but we can also see this elsewhere in the software configuration.
In some cases, the way a piece of software operates in production versus a staging server, versus a development server, could be widely variant, in cases where the software team recognizes that we don’t want certain production aspects to be working as production level things, when in dev environments, or staging environments, but do want them working as production in production environments. For example, an E-commerce site doesn’t make actual actionable orders with real money based on developer testing the workflow for adding an item to a shopping cart, or in paying in a shopping cart.
What reproducibility steps help with is determining if the error is in one of those steps. With a car, you might need to add additional details in case it turns out Your car is pulling a Volkswagen style effect in the mechanic’s office and appearing to work properly at achieving their preferred goals.
It’s been dubbed the «diesel dupe». In September [2015], the Environmental Protection Agency (EPA) found that many VW cars being sold in America had a «defeat device» — or software — in diesel engines that could detect when they were being tested, changing the performance accordingly to improve results. The German car giant has since admitted cheating emissions tests in the US.
In this case, you would likely need to tell your mechanic what was going wrong, especially if they’re having issues reproducing it locally — they can’t verify if it was broken before they sent it to the environment where the defect is being found.
Ideally, situations like this are rare in practice, but having steps to reproduce will allow a developer to verify that this is consistent behavior across environments, or whether this behavior comes across as a result of a configuration that they will need to look into why that configuration gives different behavior, especially if that behavior involves a different result than the testing behavior implies it should be.
answered Jun 18, 2021 at 0:11
![]()
Questions
As a thought experiment how many questions does your software ask and answer?
As an approximation search for words like: if, for, while, interface. Sum up their counts. That is a low ball-park figure.
Now when this software executes it plays a choose your own adventure story walking through each question and bouncing to this page or to that page.
A simple program that does 1 thing like copy a file, still has many paths it can take. A Large file vs a small file, from/to a fast/slow drive, across file systems, different filesystem paths.
A complex program has infinite paths, like just about any GUI program. Every user event occurs at different times, in different contexts, producing different layerings of response.
As a very rough thumbnail. Presume your system has roughly operational life time in seconds * factorial(the number of decisions) unique paths. There is a bug in one, or more of those paths. Find it.
If you aren’t quaking about the factorial in that approximation, you really should be. Its get large really fast. The more complicated the program, the even quicker it grows. This is why a large program is guaranteed to have bugs, and why so much effort is put into making programs simpler and smaller.
Bug Reports
This is why it is so essential to describe as much information about the bug as possible.
The basics like:
- What was wrong.
- What it should have been.
- Which screen, report, extract, email.
- When it has occurred
- Who it has occurred to
- Which version
… are important. They help close down a lot of possibilities for where the bug could be lurking.
But in a complex software eco-system its just not enough.
Ideally there would be a testing tool that support have access to that allows them to recreate the situation inside an automated test. Even if the test is slow, and does way more than it really needs to. All of that can be worked on. The important part is that it exactly reproduces the issue.
Short of having that the next best tool is a manual test. Do this, then that, click this, and voila. This is also know as steps to reproduce. The more accurate these steps are, the easier it is going to be to find the bug. If these steps are inaccurate/not there then it is pure luck if the developer spots the bug.
Analogy
Also to the description of a mechanic and a driver, its the wrong analogy. Support are the mechanics. The driver of the vehicle is the client. Developers are the designers working on the car production factory.
Support do need to know what components make up the vehicle, and be able to describe accurately the effects of real world usage on those components. IE. Did you know the computer board A, burns out really quickly for high way driving users? In software speak Did you know that the last day of the month batch process X takes 3 times longer to run, but the input is the same size as every other day that week?
If support just communicates back to the developers. Hey your product is broken. you can expect them to be ignored, because of course its broken. It arrived broken, or it has been misused to the point of breaking. That’s supports problem.
What is not supports problem is a structural defect with the product itself. Not with how it was delivered, or how it was used. They would communicate this exactly like a mechanic would to the car manufacturing company. In circumstance X, Y, Z. Following these normal system usage patterns. Some P% of the time Q happens. Doing F reduces P% or increases P%. If you do M the Q changes to Q2.
answered Jun 18, 2021 at 0:49
![]()
Kain0_0Kain0_0
15.7k16 silver badges36 bronze badges
Simple tell them, «if I can’t reproduce it, I’m unlikely to have the time to find and fix it.»
Testers should always record everything they see (with details about / debug info on what they were doing at the time), even if they can’t reproduce it. Once a bug is found, the test team need to figure out what is causing it or it may be impossible to fix. Having a working atmosphere where programmers come over and chat to testers makes a huge difference here as there’s often a lot of background information from both sides that does not get communicated in a bug report.
Finding and fixing these bugs can be incredibly challenging for both sides. It may end up being a decision for the project lead — ignore it and put it out or devote more resources to finding and fixing it.
answered Jun 18, 2021 at 8:50
![]()
DavidDavid
2711 gold badge2 silver badges11 bronze badges
The fundamental problem with this analogue is that Support aren’t the customer. They work for the «garage». They’re part of the chain of people who are paid to be there in case of «car trouble». If they’re getting paid, this analogue doesn’t work.
Assuming they aren’t rushing to rip up their paycheques, they need to take part in a division of responsibilities to help «fix the car».
Why are they best placed to be the ones to understand and reproduce?
Because they are closer to the customer. They can leverage their closer communication with the customer to figure out how the issue presents and they can use the knowledge they acquire during that process to provide very fast feedback to similar future queries. Passing the buck on this leads to support staff who don’t understand the product, which isn’t good for anyone.
Because doing this isn’t a core competence of software development. Putting developers general work that they have no special ability at is a poor use of an expensive resource. Even if support people weren’t cheaper (and let’s assume they aren’t, because that can come across as offensive), they should be better that this kind of work because it is part of their competence. Good support staff understand the product and how the users use the product. Working together, support and developers can make a better product for everyone by playing to their strengths.
So is it just up to them to change?
No. When Support are in the mode of just forwarding issues, it could be because Developers and Product professionals haven’t provided them with the tools they need to understand the system and reproduce issues. They could be resistant to reproducing issues because of something like that, and I suspect you’d only find out that by talking to them.
answered Jun 18, 2021 at 12:02
![]()
Your own question is basically a bug report in disguise, and it lacks repro steps.
«There is a bug in our support team. They don’t understand the purpose and meaning of repro steps.»
So you say, but you have not given the repro steps by which this hypothesis was formed: what are the exact words that they said, in response to what, in what context?
Maybe they were just complaining about an overly rigid bug reporting style.
Bugs are rarely described without implying some of the repro steps. We have that as a separate field in a bug database to encourage detailed, precise, specific repro steps. This is because the issue may hinge on a key detail which is tangential to what appears to be the overall repro step.
However, some bugs really don’t need elaborate repro steps; they can be inferred from the bug description. Suppose the title of the bug is Device burst into flames on power-up after Firmware C was flashed. All the info you need is contained in the topic; it hardly needs a Description field any more, let alone Repro Steps. That can literally be the entire bug report. (Still, repro steps could reveal some mistake, like that the submitter deviated from the recommended flashing procedure, or referenced the wrong firmware path name or something. But say none of that is the case. The background assumption is that the correct procedure was followed using the correct inputs; that’s the implicitly understood repro step.)
If you have some bug submission validator that won’t let you submit a bug without Repro Steps, that would be annoying if you’re often submitting bugs which don’t require them.
It could also be that the support people are frustrated because they are not getting clear repro steps from the customers, but when they escalate problems to the bug stage, those are required.
The support people may feel that since neither they nor the developers know what the repro steps are, the developers should be the ones to step up to bat and figure out the repro steps, since they know the product internals.
Remember, the support people are handling third parties. So when they talk about taking a car to the mechanic, they may be thinking of taking someone else’s car to the mechanic, without a sufficiently detailed problem indication from the car owner. In that case, the mechanic is in the better position to figure out those details than the person who conveyed the car.
Another possibility is that the support people know the value of repro steps but are looking to engineering to help them explain it to customers, just like you’re doing by going to StackExchange. That is important because if that is so, the explanation has to work for end users. Your support people are not getting repro steps, and would like some better scripts on how to obtain them, especially from certain irate customers who give them flippant mechanic analogies.
The question, «as a customer support agent, how do I handle customers who insist that the repro steps are a puzzle for support to figure out» is subtly different from «as an engineer, how do I convince my customer support people of the value and importance of repro steps?»
It’s hard to believe that you would have people in support roles who are so unqualified that they question the value of repro steps per se. If so, that is a big problem in which the repro steps discussion is just a small part.
answered Jun 18, 2021 at 15:34
![]()
KazKaz
3,5241 gold badge18 silver badges30 bronze badges
To follow on from the car analogy, I’ve used the following in other contexts:
Say you took your car into the mechanic and said the battery keeps dying. He runs thorough tests on the battery and the electrical system and finds nothing wrong. The mechanic asks you how to reproduce the problem and you get annoyed at the question and say it just happens randomly for no reason. The mechanic digs deeper and eventually discovers you’ve been frequently leaving your headlights on all night, which as a brand new car owner, you didn’t realize would drain the battery.
Now you might say that the car should prevent the battery from dying if you leave the lights on. That’s a reasonable claim, and many modern cars do just that. However, it was still impossible to make the diagnosis without knowing the steps to reproduce the problem. And at least in this case, they mentioned the battery. Some bug reports are like, «my car is broken sometimes but it’s fine now» and they don’t know why you want more detail. Also, the best mechanics will have the conversation first and not even charge you.
It’s not a perfect analogy, because in a computer application, «leaving the lights on» might not have been a user error, but an unintended side effect of another feature, or subtle interaction between two features. You also can add preventative measures and logging even if you don’t precisely know what the cause is. And I would consider a mechanic very poor if they just returned your car without at least having a discussion about possible root causes.
answered Jun 17, 2021 at 13:40
![]()
Karl BielefeldtKarl Bielefeldt
146k38 gold badges280 silver badges475 bronze badges
7
True story: A family has a problem with their new car. Every sunday the whole large family meets for lunch, then someone drives to the ice cream parlor and buys ice cream for everyone. And then a strange thing happens: Whenever they buy vanilla ice cream, the car’s engine won’t start. If they buy any other ice cream, the car’s engine starts. Mechanics couldn’t find a fault.
Finally, the family invited someone quite higher up from the manufacturer for sunday lunch. And the guy drove with them to the ice cream parlor, vanilla ice cream was ordered, and the engine wouldn’t start. This guy would have made an excellent software tester: He checked out the ice cream parlor. It turned out that they had a huge tub of vanilla ice cream that could be served quite quickly, while any other ice cream took longer. The fault had nothing to do with the ice cream flavour, but with how long the engine was turned off. Once they could reproduce the problem, the fix was easy.
But in the end, a bug that appears always and under all conditions is easily fixed. These bugs are most likely already gone before a tester ever sees the software. What is hard is problems that only happen under certain circumstances, and that will not appear 99% of the time. In that case, your bug report is not helping at all if you can’t describe how you got the 1% case.
Good tools would also allow you to specify how reproducible a bug is. You may have a bug that even with your best efforts can only be reproduced 10% of the time. What does that mean? It means the developer won’t give up if he tried it out three times and the bug didn’t appear if he knows it is rare.
And when you write down steps to reproduce a bug: Consider that a developer cannot read your mind. If you don’t write it down, he doesn’t know about it. If you are not precise, he doesn’t know what you are doing. If you are inaccurate, the bug may not be reproducible at all with your description.
PS. I’ve had bugs that would only happen to testers or even specific testers. For example: Tester does step 1, checks the screen, compares it to what his script says, does step 2, checks the screen etc. And there’s a bug that only happens when you do step 1, 2, 3 and 4 several seconds apart, by the exact right amount. A second tester writes down the results, therefore takes longer, bug disappears. The developer knows all the steps, does them quickly in a row, bug disappears. Developer and Tester 2 go to Tester 1’s desk and see him reproduce the problem. They ask him to do it slower, problem goes away. They ask him to do it faster, problem goes away. He does it at his own speed, bug comes up. This does happen.
answered Jun 17, 2021 at 14:18
![]()
gnasher729gnasher729
39.8k4 gold badges55 silver badges108 bronze badges
6
Complexity and discoverability.
The mechanic fixes dozens of cars which are basically the same every single day. He has a list of tests, which is reasonably fast to check and covers detecting all expected and most unexpected defects.
Still, if the right back side flutters a bit beyond 50 mph, that’s unlikely to be covered unless the driver highlights it. Actually, unless it is for the mandatory regular general inspections, not trying to describe your concerns to make sure they are addressed is at best odd, at worst irresponsible.
The software engineer has a far more amorphous test-target. First, it is one-of-a-kind. Yes, there is probably an automatic test-harness which is applied, but that that mostly covers the nuts and bolts, not the user-interaction, and it cannot be exhaustive. At least those will all work properly when released, so won’t be reported by the user (anymore). All the inputs, all the dependencies, all the system-configurations, and myriad other outside influences, and on top of that it is hard to anticipate all possible interactions.
The coup de grace is that you cannot look at it, and say you have thoroughly tested everything, as even delineating parts of the application to check is non-trivial, and making sure you hit everything in that part is just about impossible. Try checking the border of an invisible shape for some kind of interaction. Better if that changes dynamically, best if the way you want to interact depends on that dynamic change. Try testing an ai, or anything else with mostly hidden highly dynamic state.
And that left out all the cases where the behavior is as designed and seems reasonable, but actually isn’t, or at least doesn’t help some group of users.
If the user says «Your software has a bug», the only thing the developer can say for moderately complex software is «probably. Where does it hurt, so I can look there.»
And until that information is present, that’s «no repro / cannot fix».
answered Jun 17, 2021 at 12:20
![]()
DeduplicatorDeduplicator
8,4185 gold badges31 silver badges50 bronze badges
5
You can’t fix a problem you can’t see most of the time. It depends in the context of your company BUT the developer will need to reproduce the error so it can be investigated/fixed .
An example:
Reported Bug : The xml response gives the wrong dates for departure times
Reality: The xml response gives the wrong dates for departure times , when the train is from a certain company at a specific station .
If the developer cannot see the specifics of this bug(train company, station) , how is she gonna pin point the error and proceed with appropriate actions ? Imagine there are thousands of trains and stations responses all working properly.
answered Jun 17, 2021 at 13:50
![]()
Lets take your literal question aside for a moment. Your description gives me the impression the core problem is not the bug reports themselves, but the disconnection between the people who notice the bug, and the ones who have to fix them.
Ideally, a user may notice a behaviour of a program which looks like a bug to them, calls the support team, and they use some screen sharing tool, or screenshots, and real data to reproduce the issue, so the support team member can either help the user directly, or come to the conclusion they need to get a dev involved.
But if they cannot reproduce the issue together, the support team member can already close the ticket as «cannot reproduce». If they can, the support team member now can call a dev and do the same with them: show them what works wrong — for this, the support team member needs to make sure they can demonstrate the problem, for example, within their test environment. If they now cannot reproduce the issue again, the support team member can either speak to the user again, ask for more information, or close the issue themselves.
But you wrote:
sometimes the support team submit reports without and become frustrated when dev close them as «cannot reproduce / cannot fix»
That gives me the impression the support team member just try to write down their bug reports in words (not necessarily by reproducing the issue together with a user first), they don’t try to reproduce issues in their environment and don’t use screen sharing tools to explain the issue to the devs. And that’s the real problem here — the communication workflow isn’t ideal, there is too much «one way» communication, too much risk for «chinese whisper».
Interestingly, the answer given by @gnat in 2012 was pretty much going into the same direction: there needs to be a good bidirectional communication channel between users, support staff and devs. Of course, as that older other answer points out, such a channel can be established by using written text. Today screen sharing has become standard, it has made support communication a lot simpler. It is not a replacement for written tickets, but has proved itself as terribly useful.
Of course, reproducability is not only important for this communication chain, it is also important for the dev to be able to verify a bug fix works, but you asked for the non-dev perspective.
answered Jun 17, 2021 at 13:42
![]()
Doc BrownDoc Brown
192k33 gold badges354 silver badges541 bronze badges
3
To look at this a slightly different way:
When a tester fills out a bug report, they typically can’t write down exactly what the problem is. They write their interpretation of the problem. When a developer starts working on that ticket, they base their work on their interpretation of what the tester wrote. At each step, there’s lots of room for error due to poor communication, faulty assumptions about how the program works, or mistaken observations. Reproduction steps describe the problem in an objective way that retains its accuracy, even through multiple layers of non-technical middlemen that may not all be fluent in the same language.
The other aspect is that reproduction steps provide a «definition of done». If I follow the steps and no longer see the problem, then I’ve fixed the issue. Without reproduction steps the situation is ambiguous. Did I fix it? Or am I just not doing the right thing to trigger the problem? It’s hard to say. Situations like this are where you see bugs go through multiple cycles of fixed->re-opened before it gets fixed for good. It saves time for the tester and the developer if the tester provides the reproduction steps up front.
answered Jun 17, 2021 at 22:22
![]()
btabta
9655 silver badges12 bronze badges
A few reasons:
- «Trust, but verify»: A large portion of bug reports are not actually bugs but rather mistaken user conceptions of how software should work. Sometimes, the problem is not even in the software they are complaining about: they mixed up the problem in their mind and remembered the flow incorrectly. Software developers know this, and ask for the reproduction steps as a form of verification. The repro steps offer more concrete proof that the issue is real and affects their software.
- Ease of debugging: As a practical matter, it is much easier to resolve an issue if it can be reproduced consistently. You can attach a debugger and step through each line of code, watching the relevant variables change. Without repro steps, if you don’t intimately understand the relevant code, you might not intuitively know where to find the bug. You might then need to add extra logging to all suspect code and wait for another occurrence.
- Self-education: Developers are often tasked with maintaining code they did not write in a system that they do not use. Repro steps help educate the developer on the context of the problem and how the system is actually used. This is invaluable background that can help them understand potential side-effects of any fix they attempt.
- Future regression testing: With good repro steps, a developer or QA engineer can more easily write an automated or manual test that can be added to the system to prevent future regressions of this bug.
I should also add that the car mechanic analogy is flawed because good auto mechanics do, in fact, ask for repro steps for issues that are intermittent or hard to diagnose.
answered Jun 17, 2021 at 21:45
![]()
There are two somewhat related reasons, I think.
First off, the car mechanic analogy is pretty badly flawed. For one thing, cars wear out in ways that software does not. Also, the mechanic is not the guy who designed and built the car. He (or she) is someone whose job it is to diagnose and repair problems. The role is more akin to QA than design.
Another thing to keep in mind that if someone who’s reporting a bug doesn’t think it’s important to describe the bug carefully, or with reproduction steps, it’s probably because they imagine that the bug is so obvious that no one could fail to miss it after even a cursory inspection. We’ll come back to that.
Finally, of course, just about any modern software application is almost infinitely more complicated than a «simple» automobile. It’s going to have gobs of different features and functions and usage patterns. How one user uses it may have almost no resemblance to how another does.
So the first of my reasons is that, like it or not, developers tend to imagine that their code is perfect. They tried hard to make it so, they tested it before they released it, it passed all its unit tests before they released it. And if nothing else, they know that their code works perfectly when it comes to the things they most commonly test it on. So if you hand a developer a bug report about his code, without much description, imagining it’s obvious, the developer may or may not «put the code through its paces», but if he does, it’s going to be with his preferred usage pattern — the one he already knows it will pass handily. So he’s totally predisposed to say, «Cannot reproduce, user error».
And then the other reason is is that users are probably making more heavy use of the older and more established features, while developers are always working with (designing and implementing and testing and using) the brand-new features that Marketing wanted in the new release. So if (as not uncommonly happens) a new feature inadvertently introduces a bug into an old, long-established feature, and a user notices and complains about it, and even if it is a glaring, showstopping bug that would be immediately noticed by any casual user, it’s still not likely to be noticed by a developer, because the developers never use that old feature any more, they may have forgotten it even existed, because they’re all consumed working on the brand-new features.
So, bottom line, careful descriptions and reproduction steps are necessary because the alternative — just saying, «there’s a bug, it’s obvious, you’ll see it right away» — is too likely to be false.
answered Jun 17, 2021 at 20:20
![]()
4
To add to the other answers, sometimes of course you do have to investigate a problem that you don’t know how to reproduce. We had a customer once with a database corruption, with no idea how it occurred; I was supporting the database software and had to work out a possible sequence of events that could have led to the corruption, working backwards from the symptoms. It took a week, and at the end of it, I had a possible explanation, but no evidence that it was the correct explanation. So the real reason developers ask for a repro is because it reduces the effort needed to find an explanation for the problem, and increases the likelihood that the explanation will be correct.
answered Jun 17, 2021 at 23:00
![]()
1
The Software Bug/Defect might not be a bug with the software itself, but a combination of the Software itself with a specific configuration.
Reproducibility steps do help verify that a specific issue is reproducible, and raises flags to the mechanic if, for example, you tell him the car doesn’t have its steering wheel working properly on the road, but it does work in the mechanic’s shop when they test the car there.
This could be thought of as similar to browser compatibility issues with a web based application (i.e. the «It works in newer browsers, but not in the browser the client is using» problem), but we can also see this elsewhere in the software configuration.
In some cases, the way a piece of software operates in production versus a staging server, versus a development server, could be widely variant, in cases where the software team recognizes that we don’t want certain production aspects to be working as production level things, when in dev environments, or staging environments, but do want them working as production in production environments. For example, an E-commerce site doesn’t make actual actionable orders with real money based on developer testing the workflow for adding an item to a shopping cart, or in paying in a shopping cart.
What reproducibility steps help with is determining if the error is in one of those steps. With a car, you might need to add additional details in case it turns out Your car is pulling a Volkswagen style effect in the mechanic’s office and appearing to work properly at achieving their preferred goals.
It’s been dubbed the «diesel dupe». In September [2015], the Environmental Protection Agency (EPA) found that many VW cars being sold in America had a «defeat device» — or software — in diesel engines that could detect when they were being tested, changing the performance accordingly to improve results. The German car giant has since admitted cheating emissions tests in the US.
In this case, you would likely need to tell your mechanic what was going wrong, especially if they’re having issues reproducing it locally — they can’t verify if it was broken before they sent it to the environment where the defect is being found.
Ideally, situations like this are rare in practice, but having steps to reproduce will allow a developer to verify that this is consistent behavior across environments, or whether this behavior comes across as a result of a configuration that they will need to look into why that configuration gives different behavior, especially if that behavior involves a different result than the testing behavior implies it should be.
answered Jun 18, 2021 at 0:11
![]()
Questions
As a thought experiment how many questions does your software ask and answer?
As an approximation search for words like: if, for, while, interface. Sum up their counts. That is a low ball-park figure.
Now when this software executes it plays a choose your own adventure story walking through each question and bouncing to this page or to that page.
A simple program that does 1 thing like copy a file, still has many paths it can take. A Large file vs a small file, from/to a fast/slow drive, across file systems, different filesystem paths.
A complex program has infinite paths, like just about any GUI program. Every user event occurs at different times, in different contexts, producing different layerings of response.
As a very rough thumbnail. Presume your system has roughly operational life time in seconds * factorial(the number of decisions) unique paths. There is a bug in one, or more of those paths. Find it.
If you aren’t quaking about the factorial in that approximation, you really should be. Its get large really fast. The more complicated the program, the even quicker it grows. This is why a large program is guaranteed to have bugs, and why so much effort is put into making programs simpler and smaller.
Bug Reports
This is why it is so essential to describe as much information about the bug as possible.
The basics like:
- What was wrong.
- What it should have been.
- Which screen, report, extract, email.
- When it has occurred
- Who it has occurred to
- Which version
… are important. They help close down a lot of possibilities for where the bug could be lurking.
But in a complex software eco-system its just not enough.
Ideally there would be a testing tool that support have access to that allows them to recreate the situation inside an automated test. Even if the test is slow, and does way more than it really needs to. All of that can be worked on. The important part is that it exactly reproduces the issue.
Short of having that the next best tool is a manual test. Do this, then that, click this, and voila. This is also know as steps to reproduce. The more accurate these steps are, the easier it is going to be to find the bug. If these steps are inaccurate/not there then it is pure luck if the developer spots the bug.
Analogy
Also to the description of a mechanic and a driver, its the wrong analogy. Support are the mechanics. The driver of the vehicle is the client. Developers are the designers working on the car production factory.
Support do need to know what components make up the vehicle, and be able to describe accurately the effects of real world usage on those components. IE. Did you know the computer board A, burns out really quickly for high way driving users? In software speak Did you know that the last day of the month batch process X takes 3 times longer to run, but the input is the same size as every other day that week?
If support just communicates back to the developers. Hey your product is broken. you can expect them to be ignored, because of course its broken. It arrived broken, or it has been misused to the point of breaking. That’s supports problem.
What is not supports problem is a structural defect with the product itself. Not with how it was delivered, or how it was used. They would communicate this exactly like a mechanic would to the car manufacturing company. In circumstance X, Y, Z. Following these normal system usage patterns. Some P% of the time Q happens. Doing F reduces P% or increases P%. If you do M the Q changes to Q2.
answered Jun 18, 2021 at 0:49
![]()
Kain0_0Kain0_0
15.7k16 silver badges36 bronze badges
Simple tell them, «if I can’t reproduce it, I’m unlikely to have the time to find and fix it.»
Testers should always record everything they see (with details about / debug info on what they were doing at the time), even if they can’t reproduce it. Once a bug is found, the test team need to figure out what is causing it or it may be impossible to fix. Having a working atmosphere where programmers come over and chat to testers makes a huge difference here as there’s often a lot of background information from both sides that does not get communicated in a bug report.
Finding and fixing these bugs can be incredibly challenging for both sides. It may end up being a decision for the project lead — ignore it and put it out or devote more resources to finding and fixing it.
answered Jun 18, 2021 at 8:50
![]()
DavidDavid
2711 gold badge2 silver badges11 bronze badges
The fundamental problem with this analogue is that Support aren’t the customer. They work for the «garage». They’re part of the chain of people who are paid to be there in case of «car trouble». If they’re getting paid, this analogue doesn’t work.
Assuming they aren’t rushing to rip up their paycheques, they need to take part in a division of responsibilities to help «fix the car».
Why are they best placed to be the ones to understand and reproduce?
Because they are closer to the customer. They can leverage their closer communication with the customer to figure out how the issue presents and they can use the knowledge they acquire during that process to provide very fast feedback to similar future queries. Passing the buck on this leads to support staff who don’t understand the product, which isn’t good for anyone.
Because doing this isn’t a core competence of software development. Putting developers general work that they have no special ability at is a poor use of an expensive resource. Even if support people weren’t cheaper (and let’s assume they aren’t, because that can come across as offensive), they should be better that this kind of work because it is part of their competence. Good support staff understand the product and how the users use the product. Working together, support and developers can make a better product for everyone by playing to their strengths.
So is it just up to them to change?
No. When Support are in the mode of just forwarding issues, it could be because Developers and Product professionals haven’t provided them with the tools they need to understand the system and reproduce issues. They could be resistant to reproducing issues because of something like that, and I suspect you’d only find out that by talking to them.
answered Jun 18, 2021 at 12:02
![]()
Your own question is basically a bug report in disguise, and it lacks repro steps.
«There is a bug in our support team. They don’t understand the purpose and meaning of repro steps.»
So you say, but you have not given the repro steps by which this hypothesis was formed: what are the exact words that they said, in response to what, in what context?
Maybe they were just complaining about an overly rigid bug reporting style.
Bugs are rarely described without implying some of the repro steps. We have that as a separate field in a bug database to encourage detailed, precise, specific repro steps. This is because the issue may hinge on a key detail which is tangential to what appears to be the overall repro step.
However, some bugs really don’t need elaborate repro steps; they can be inferred from the bug description. Suppose the title of the bug is Device burst into flames on power-up after Firmware C was flashed. All the info you need is contained in the topic; it hardly needs a Description field any more, let alone Repro Steps. That can literally be the entire bug report. (Still, repro steps could reveal some mistake, like that the submitter deviated from the recommended flashing procedure, or referenced the wrong firmware path name or something. But say none of that is the case. The background assumption is that the correct procedure was followed using the correct inputs; that’s the implicitly understood repro step.)
If you have some bug submission validator that won’t let you submit a bug without Repro Steps, that would be annoying if you’re often submitting bugs which don’t require them.
It could also be that the support people are frustrated because they are not getting clear repro steps from the customers, but when they escalate problems to the bug stage, those are required.
The support people may feel that since neither they nor the developers know what the repro steps are, the developers should be the ones to step up to bat and figure out the repro steps, since they know the product internals.
Remember, the support people are handling third parties. So when they talk about taking a car to the mechanic, they may be thinking of taking someone else’s car to the mechanic, without a sufficiently detailed problem indication from the car owner. In that case, the mechanic is in the better position to figure out those details than the person who conveyed the car.
Another possibility is that the support people know the value of repro steps but are looking to engineering to help them explain it to customers, just like you’re doing by going to StackExchange. That is important because if that is so, the explanation has to work for end users. Your support people are not getting repro steps, and would like some better scripts on how to obtain them, especially from certain irate customers who give them flippant mechanic analogies.
The question, «as a customer support agent, how do I handle customers who insist that the repro steps are a puzzle for support to figure out» is subtly different from «as an engineer, how do I convince my customer support people of the value and importance of repro steps?»
It’s hard to believe that you would have people in support roles who are so unqualified that they question the value of repro steps per se. If so, that is a big problem in which the repro steps discussion is just a small part.
answered Jun 18, 2021 at 15:34
![]()
KazKaz
3,5241 gold badge18 silver badges30 bronze badges
Любая компания по разработке программного обеспечения стремится к тому, чтобы продукт, который она создаёт, был высочайшего качества. Для того, чтобы этого добиться, QA специалисты должны обнаружить все недостатки и недочёты приложения ещё на ранних стадиях жизненного цикла разработки программного обеспечения. А когда ошибка обнаружена, её нужно описать так, чтобы разработчики могли легко понять, в чём заключается проблема, воспроизвести её и оперативно исправить. Именно для этого пишутся баг-репорты.
В этой статье мы обсудим основные компоненты отчёта об ошибке, разберём, на какие моменты стоит обращать внимание при их составлении, а также рассмотрим, какие существуют инструменты для отслеживания багов.
Что такое баг-репорт?
Баг-репорт — это отчёт, который информирует разработчиков об ошибке (баге) в работе приложения. Этот документ должен быть хорошо структурированным и содержать достаточно деталей, чтобы читатель мог легко найти ответы на главные вопросы:
- Где возникла проблема?
- Что именно работает не так, как ожидалось?
- Какие действия нужно выполнить, чтобы воспроизвести ошибку?
Не стоит также забывать о том, что у разработчиков нет времени читать слишком длинные, с множеством несущественных подробностей описания багов. Поэтому отчёты должны быть как можно более краткими.
Как правило, репорт попадает в категорию плохо составленных по одной из двух причин: слишком много ненужных деталей или слишком мало полезной информации. Навык не включать в отчёт ничего лишнего приходит с опытом. А для того, чтобы не пропустить ничего важного, достаточно помнить об основных элементах баг-репорта.
Основные компоненты баг-репорта.
Давайте рассмотрим каждый раздел отчёта об ошибке и поговорим о том, на что стоит обращать внимание при написании.
Заголовок.
Заголовок — это та часть репорта, которую разработчики видят первой. Он должен представлять собой краткое описание бага. Общие заголовки вроде «Поиск не работает» не очень полезны. Что именно не работает? Система выдаёт результаты, не соответствующие запросу? Поиск длится слишком долго? Вариант «При нажатии на кнопку поиска функция не срабатывает» более информативен. Хорошие заголовки снижают вероятность появления дублирующихся репортов, а также позволяют разработчику быстрее найти нужный ему отчёт.
Описание бага.
Раздел с описанием ошибки должен содержать подробную информацию о том, что привело к возникновению проблемы, какой результат ожидали получить тестировщики, а что произошло на самом деле. Он может иметь такую структуру:
- Шаги для воспроизведения бага.
Очень важно предоставить разработчикам чёткие инструкции, как они могут воспроизвести ошибку. В идеале это должен быть пронумерованный список понятных действий:
- Перейти на страницу входа в систему.
- Ввести правильное имя пользователя.
- Ввести неправильный пароль.
Чтобы сделать список короче, можно заранее оговорить некие условия. Например, если что-то не работает на странице редактирования профиля, не обязательно подробно описывать все шаги для входа в систему. Вместо этого можно внести информацию: предварительные условия — зарегистрированный пользователь вошёл в систему.
- Фактические и ожидаемые результаты.
Здесь вы объясняете разницу между ожидаемым и фактическим поведением приложения.
Ожидаемый результат: Не удаётся войти в учётную запись. Появляется сообщение об ошибке «Неверное имя пользователя или пароль».
Фактический результат: Не удаётся войти в учётную запись. Появляется сообщение об ошибке «Неверное имя пользователя”.
При написании каждого из этих подразделов не забывайте о том, что добавить всю полезную информации и исключить все ненужные детали одинаково важно.
Приложения
Скриншоты или видеозапись экрана помогут разработчикам быстрее разобраться в сути проблемы и найти оптимальное решение. Однако это не означает, что можно добавить к отчёту видео и не утруждать себя описанием ошибки. Приложения лишь дополняют, но ни в коем случае не заменяют текстовую информацию.
Критичность и приоритет (Severity, Priority)
Эти разделы подсказывают, насколько серьёзные последствия может вызвать обнаруженная ошибка и как срочно её нужно устранить. Обычно багам присваивается один из 6 уровней критичности: блокирующий, критический, серьёзный, незначительный, тривиальный, предлагаемое улучшение. В зависимости от критичности проблемы ей назначается высокий, средний или низкий уровень приоритета.
Программно-аппаратное окружение (Environment)
На разных устройствах приложения могут вести себя по-разному. Поэтому качественный отчёт об ошибке должен также содержать информацию об операционной системе, версии приложения, браузерах и девайсах, использованных в процессе тестирования.
Подход к составлению отчётов об ошибках может немного отличаться от компании к компании. Это зависит от используемых технологий, типа проекта, принятых рабочих процессов и тестируемых продуктов. Однако понимание основных компонентов баг-репорта и требований к ним поможет вам составлять хорошие отчёты независимо от этих факторов.
Инструменты для отслеживания ошибок или баг-трекеры.
Баг-трекеры — это инструменты, которые позволяют командам эффективнее фиксировать и отслеживать дефекты в приложениях. В их функционал обычно входит следующее:
- Создавать баг-репорты.
- Присваивать ошибкам приоритет.
- Менять статус бага на разных этапах его жизненного цикла (например, новый, открыт, отклонён, исправлен и т.д.).
- Назначать ответственных за выполнение той или иной задачи.
- Искать, фильтровать и сортировать ошибки по различным параметрам: по названию, критичности, идентификационному номеру и т.д.
Вот краткий обзор десяти популярных инструментов для отслеживания ошибок.
JIRA
JIRA — это баг-трекер и инструмент для управления Agile-проектами, который используют многие компании. Её легко подстроить под нужды конкретной команды и интегрировать практически с любым другим инструментом разработки.
Bugzilla
Bugzilla — это популярный баг-трекер с открытым исходным кодом. Он прост в использовании, имеет все необходимые функции и предоставляет расширенные возможности поиска.
Trello
Trello — популярная система управления проектами. Она невероятно гибкая и позволяет наладить эффективный рабочий процесс по отслеживанию ошибок для команд любого размера.
Asana
Asana — ещё один инструмент управления проектами, который широко используется для отслеживания ошибок. В ней даже есть готовый шаблон для таких целей, который можно легко изменить или дополнить, в зависимости от потребностей компании.
Redmine
Redmine — баг-трекер с открытым исходным кодом. Он популярен среди небольших команд, которым нужно простое и гибкое решение для управления различными проектами.
FogBugz
FogBugz — веб-система управления проектами с функциями для отслеживания ошибок, управления задачами и учёта рабочего времени.
YouTrack
YouTrack — это веб-система для отслеживания ошибок и управления проектами, разработанная компанией JetBrains. Она позволяет фиксировать дефекты, планировать спринты, управлять задачами и составлять отчёты о проделанной работе.
Backlog
Backlog — простая, но мощная платформа. Расширенные возможности поиска, полная история обновлений и изменений статусов, вики, иерархия задач, диаграммы Ганта и множество других полезных функций позволяют без труда наладить эффективный процесс отслеживания ошибок.
Zoho Bug Tracking
Zoho Bug Tracking — это онлайн-платформа, с помощью которой можно создавать проекты, отслеживать ошибки, генерировать отчёты или обмениваться документами.
BugHerd
BugHerd — инструмент, который позволяет собирать отчёты о работе сайта прямо на его страницах.
Безусловно, использование подходящих инструментов может облегчить работу по отслеживанию багов. Однако, чтобы наладить действительно эффективный процесс, одних инструментов мало. Нужно ещё, чтобы все члены команды придерживались основных правил по написанию качественных баг-репортов.
О чём стоит помнить при составлении баг-репортов?
Вот несколько принципов, которых стоит придерживаться:
- Один отчет — одна ошибка. Даже если вы обнаружили проблемы в одном и том же месте, создавайте отдельные репорты для каждого бага. Если описывать несколько в одном отчёте, это только запутает читателя и он может упустить какой-то из дефектов. Кроме того, статус такого репорта невозможно будет изменить, пока разработчики не исправят все перечисленные в нём ошибки. И разобраться, как продвигается работа, будет сложнее.
- Избегайте дубликатов. Прежде чем создавать новый баг-репорт, проверьте, если проблема уже не была описана ранее.
- Воспроизведите ошибку несколько раз, чтобы убедиться, что вы не пропустили ни одного важного шага в инструкциях для разработчиков. Если у вас не получается повторить проблему каждый раз, упомяните об этом и укажите коэффициент воспроизводимости (например: 7/10 раз баг воспроизводится).
- Придерживайтесь фактов и не стройте предположений о том, что могло стать причиной дефекта. Это может задать разработчикам неверное направление мысли и отсрочить устранение ошибки.
- Всегда будьте вежливы, не обвиняйте и не критикуйте коллег. Ваша работа как тестировщика заключается в обеспечении высокого качества продукта, а не в оценке чьей-то работы.
- И наконец, перечитайте свой отчёт, прежде чем отправить его. Он должен быть кратким, понятным и содержать всю необходимую информацию.
Создание качественных баг-репортов — ценный навык для любого специалиста по обеспечению качества. Теперь, когда вы получили достаточно теоретической информации, пришло время применить свои знания на практике. Тренируйтесь — и совсем скоро вы будете писать отчёты, которые точно понравятся вашим разработчикам!
Полезные ссылки
https://www.atlassian.com/software/jira
https://www.bugzilla.org/
https://trello.com/en
https://asana.com/
https://www.redmine.org/
https://fogbugz.com/
https://www.jetbrains.com/youtrack/
https://backlog.com/
https://www.zoho.com/bugtracker/
https://bugherd.com/
Запись на курс Manual QA