Jenkins is an open source automation server. It can run any task with sophisticated set of rules regarding source control and/or dependencies between jobs. It is used to automate all sorts of tasks such as building, testing, and deploying software. Jenkins can be installed through native system packages, Docker, or even run standalone by any machine with the Java Runtime Environment installed. In this article I will show how to set up automatic CI/CD pipelines for python applications using Jenkins.
It works on my machine!
How many times did you hear this sentence? Whenever I hear it, it is clear to me, that project has no Continuous Integration implemented. It is built and tested manually (at best) and it is always a bad idea.
Continuous integration is very powerful practice used during software development. And helps save tons of money. Bugs caught early cost ten times less, compared to the bugs spotted at production. Jenkins is considered one of the best DevOps tool, which maximizes chance to produce bug free software, which results in high quality software. It allows to quickly take the code, build it (step omitted in case of python packages, which usually do not require compilation step) on a frequent schedule and deploy into designated, representative environment for testing. Without the ability to automate code deployment, you are left with an enormous piece of manual, repetitive tasks in deployment pipeline:
- Get current software version from source control server
- Create test environment
- Install dependencies
- Test software (unit and integration tests)
- Deploy
This is typical pipeline in most IT projects. Jenkins can help to automate this work. And not only automate, but to establish common baseline for all developers working in the project. What is baseline? It is entire projects configuration and dependencies i.e. third party packages used in computation, environmental variables and other settings characteristic for the project.
Also, Jenkins is free and has over 1000 plugins, created by active community, which extend its functionality in every possible way. Plugins provide tools for many languages and functionalities developers around the world add for few decades now.
Jenkins fresh out of the box is not very appealing. When logged to the server, you should see following picture:
This is very basic view of Jenkins home page, which is crude and very old-school.
True power of Jenkins is within its plugins to support building, deploying and automating any project. Very promising is set of plugins grouped under common name Blue Ocean. It is new opening of the Jenkins UI. It has also lots of extensions integrating it with GitLab, GitHub or BitBucket, including very handy creators.
You can find basic tutorial about Blue Ocean UI functionalities on Jenkins Blue Ocean tutorial.
There are many ways of creating Jenkins pipeline:
- free style jobs combinations (not recommended)
- scripted pipelines
- declarative pipelines
In this post, but I will focus only on the last one, most recent and most feature rich and safest option.
Free style jobs chaining was common practice before. Its advantage was simplicity. Click here and there, add bash command to the form on the project page and voila. But when project reaches several dozens of stages communicating them becomes nightmare.
Much better approach is to move stages and their logic into separate groovy script. In scripted pipelines script is again block of code pasted in the projects form on Jenkins site. Single steps of the pipeline are encoded in Jenkins scripted language resembling groovy, so we have part of the pipeline moved to the cohesive script and use Jenkins internal structures, but it shares same disadvantage as previous solution. It exists only in Jenkins local configuration files. Once your Jenkins installation is gone, so is your pipeline.
The best solution is to keep everything under version control. In special files describing entire pipeline to any Jenkins instance. This is so called declarative pipeline. Let’s create special Jenkinsfile and put there some basic pipeline from the tutorial.
Setting up GitHub project
First we need to create GitHub repository (with LICENSE and .gitignore for example) and add Jenkinsfile to it. For this post I decided to create dummy project deployed to PyPI which will be simple Iris data set classifier. Basic project structure is:
.
├── .behaverc
├── .gitignore
├── irisvmpy
│ ├── __init__.py
│ └── iris.py
├── Jenkinsfile
├── LICENSE
├── Manifest.in
├── README.md
├── setup.cfg
├── setup.py
└── tests/
├── features
│ ├── environment.py
│ ├── iris.feature
│ └── steps
│ └── iris_steps.py
└── test_iris.pyProject pushed to the GitHub repository H E R E. It is a simple Iris classifier using SVM. It contains all files necessary to build decent python project.
Basic pipeline structure, recommended on Jenkins pipeline documentation is as follows:
Jenkinsfile
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building'
}
}
stage('Test') {
steps {
echo 'Testing'
}
}
stage('Deploy') {
steps {
echo 'Deploying'
}
}
}
post {
always {
echo 'This will always run'
}
success {
echo 'This will run only if successful'
}
failure {
echo 'This will run only if failed'
}
unstable {
echo 'This will run only if the run was marked as unstable'
}
changed {
echo 'This will run only if the state of the Pipeline has changed'
echo 'For example, if the Pipeline was previously failing but is now successful'
}
}
}Main block of each declarative pipeline is pipeline{} block. In pipeline one can define stages{}, as group of stage{} elements. Each containing specific steps{}, their order and logic. Beside stages{} one can also set pipelines properties{}, options{} or environment{} blocs. Also, some directives to the source control manager concerning frequency of checking GitHub repository for changes in triggers{} block (it accepts cron syntax). Check Crontab Guru for examples.
Jenkins allows running jobs on multiple machines in various configurations. So user usually can specify agent, which runs specific step or all steps included in the pipeline. Agent may be local jenkins instance, some virtual machine connected to it (and running different OS for example) or docker container run by host machine.
In this pipeline there is also extensive post{} block with some messages displayed on the screen under specific conditions. As their names indicate, some will always be displayed, some upon success or failure. Post part can be used to communicate with developer to send message about project status.
Three of them will be used in almost every project:
-
Always will be displayed every time Jenkins finishes. Useful when we want to archive logs, or clean up after each run.
-
Success only when no errors were noted during pipeline processing. Good to archive successful builds.
-
Failed is an option processed when pipeline failed. This variant of post part is very useful to send feedback to the team, via e-mail or other medium like slack channel, that something went wrong and changes committed lately did not pass regression tests and require urgent attention. When CI is tightly combined with delivery process (i.e. copying web app to the production server), post failure option may be used to roll back to the last successful build.
It is time to connect our project with Jenkins. To do that I will use Blue Ocean creator. First one needs to connect GitHub account with Jenkins user account (add Personal Access Token), then connect GitHub account. More details about pipeline creation and adding GitHub access token from scratch — here. In general process can be summed up in three slides:
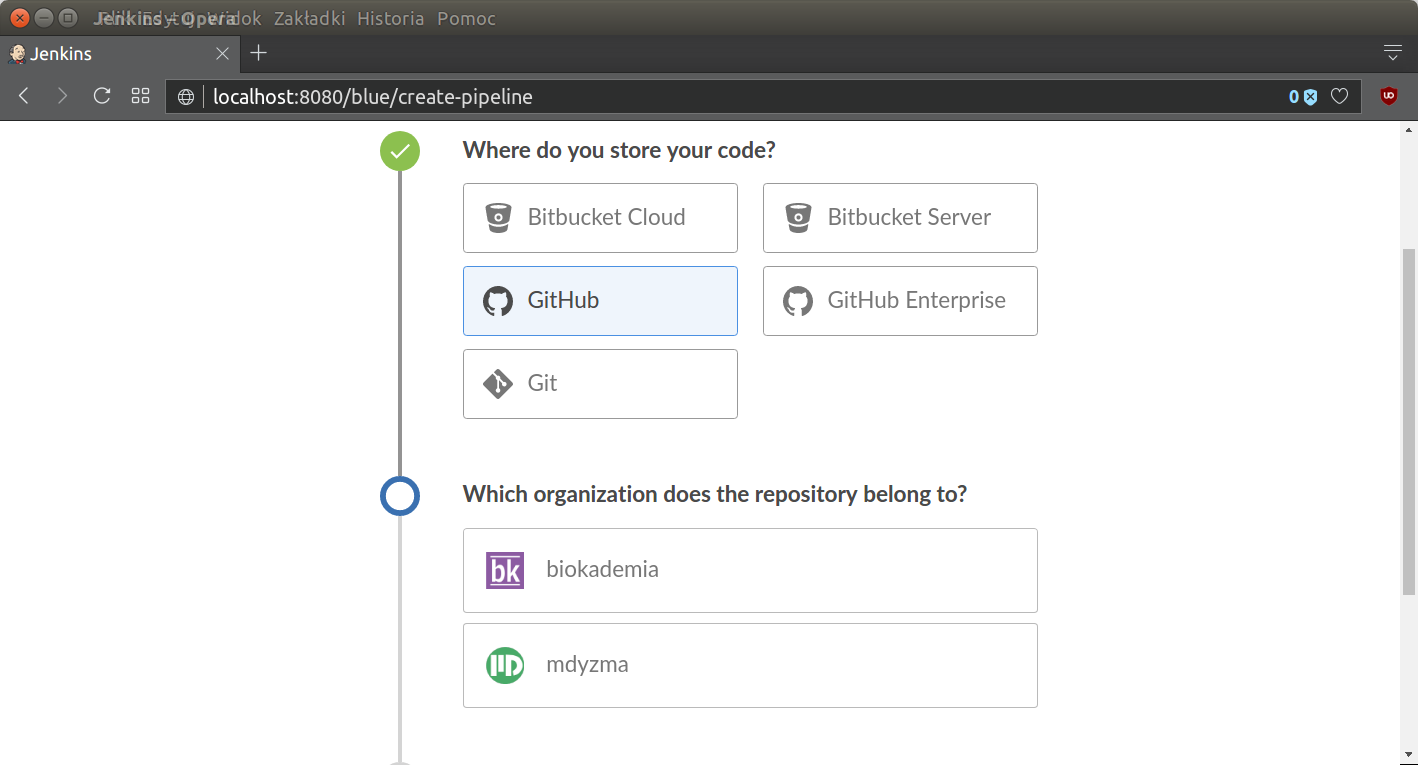
After that creator leads to specific repository:
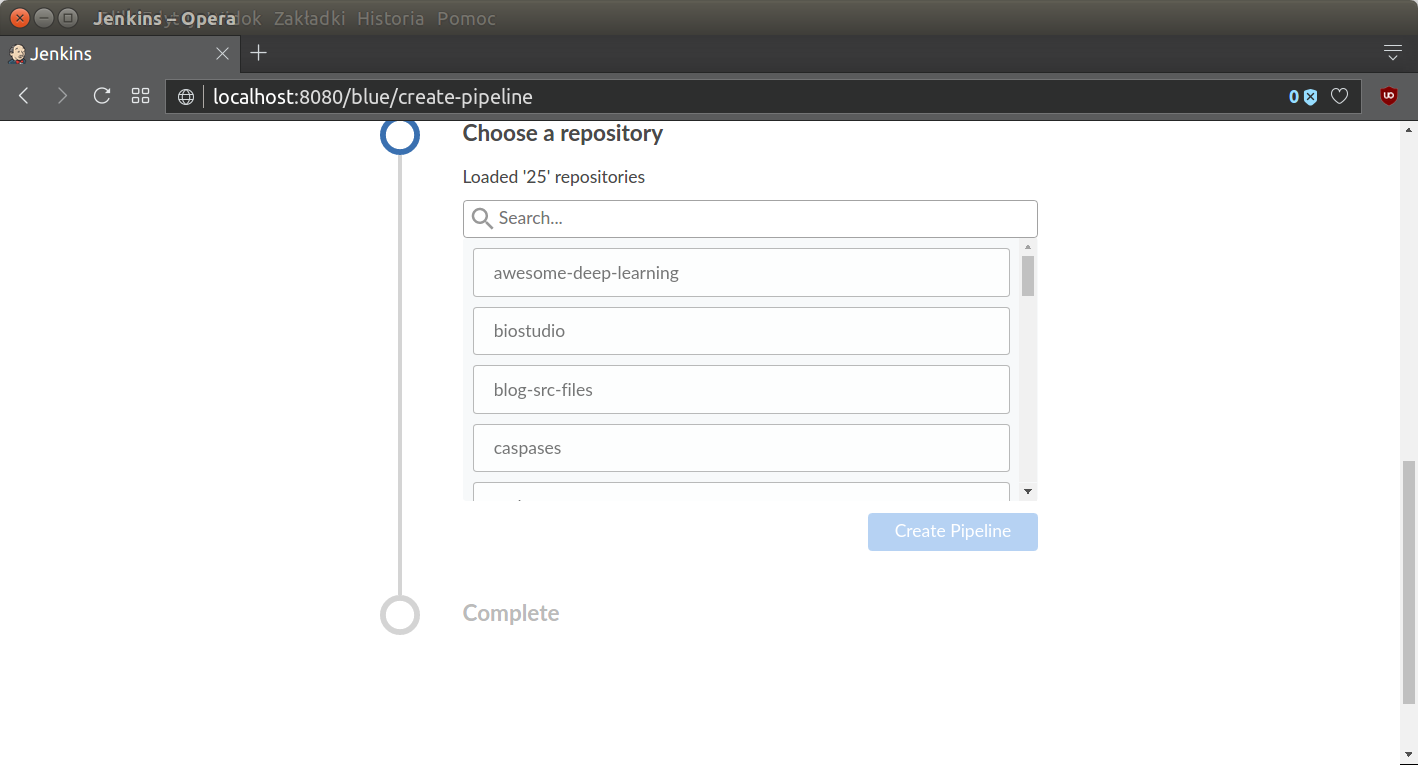
and finally, Jenkins will auto-discover all steps from Jenkinsfile present in the repository. Alternatively one can use Blue Ocean Pipeline Editor and create everything using nice GUI based user interface. Pipeline will be displayed on the screen:
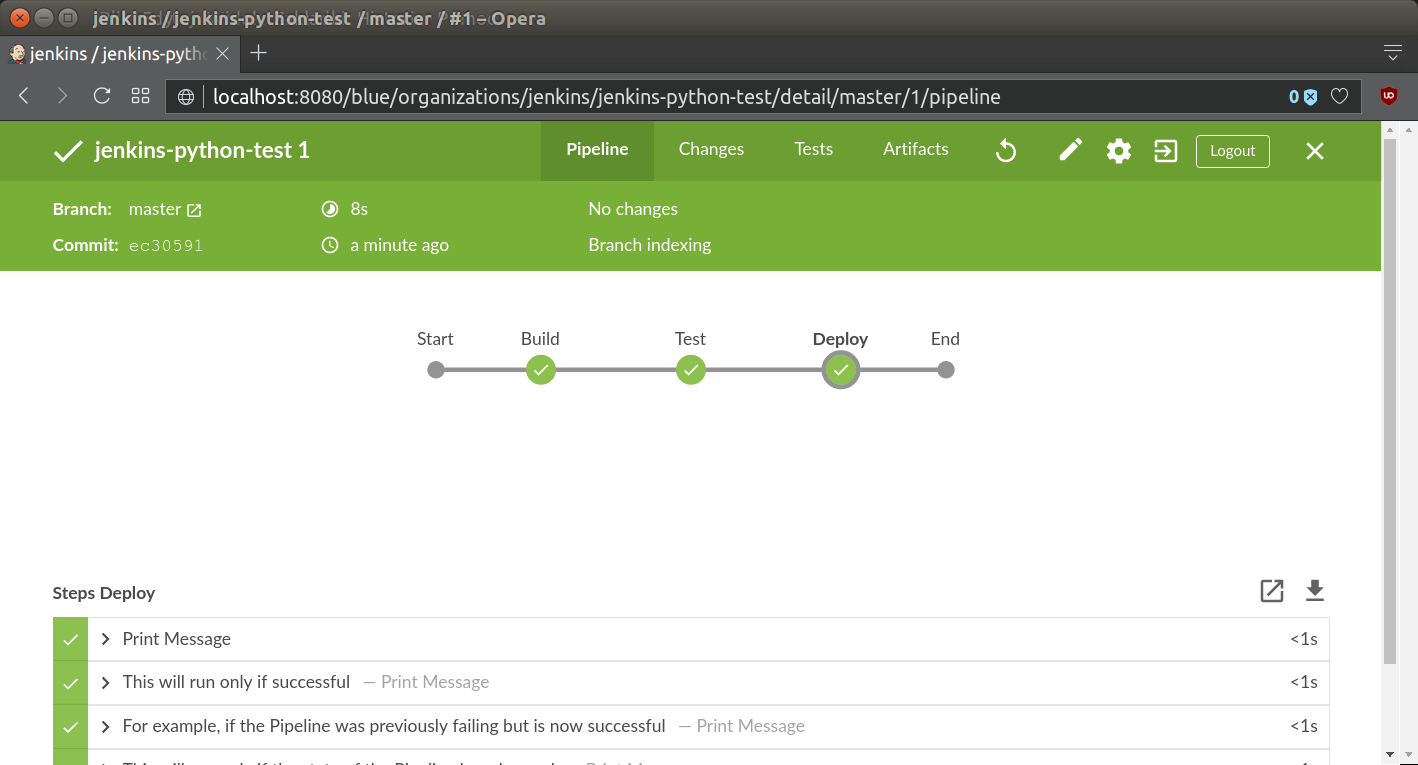
Jenkins will automatically run the pipeline and display all the messages, which apply, from the post section. In this case we will get green status, since Jenkinsfile is comprised just several echo statements.
There is also a page summarizing statuses of all projects under this jenkins server control. General list of all projects on Jenkins server looks like this:
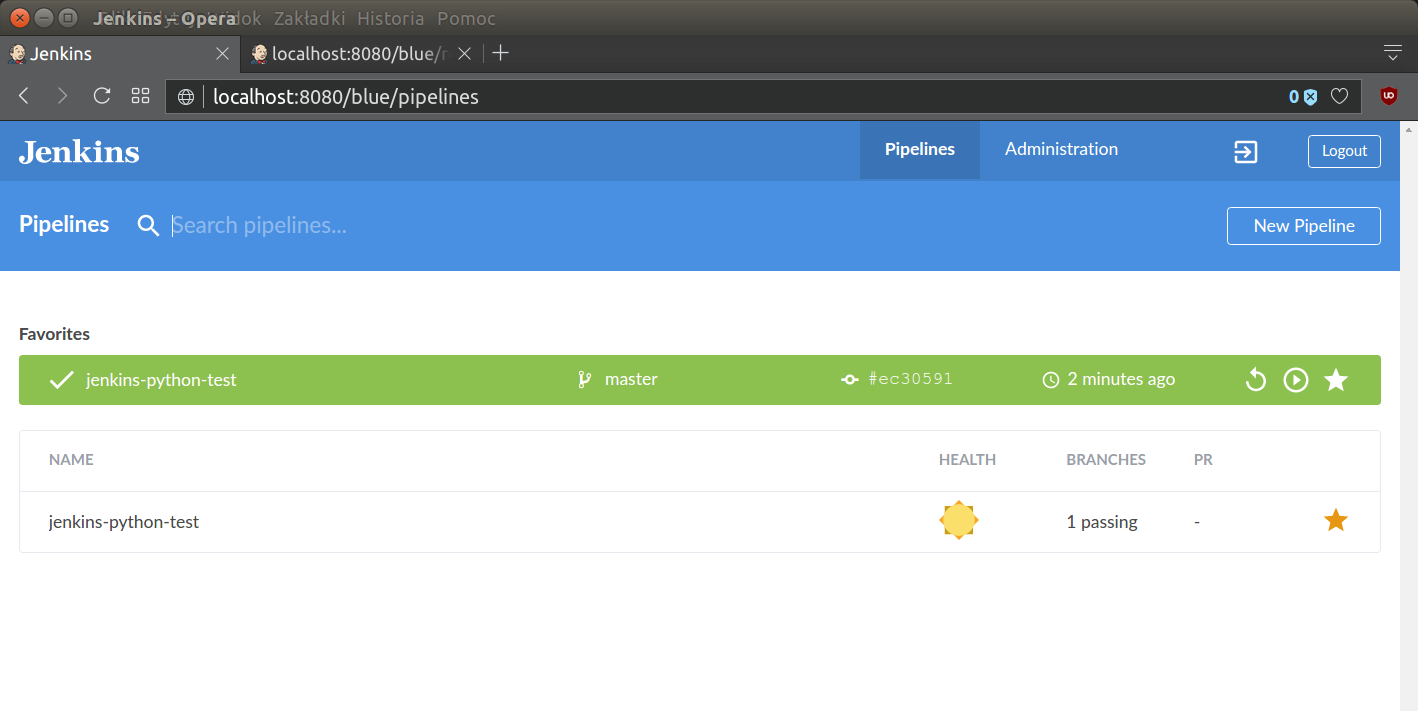
When the project is properly connected to the CI server, we can start extending pipeline to fit our needs.
Project steps
Unlike compiled languages, Python does not need a “build” stage per se, but Python projects can still benefit greatly from using Jenkins for continuous integration and delivery. In Python ecosystem there are tools which can be integrated into Jenkins for testing and reporting (i.e. unit tests runners (pytest, nose) or code metrics reports creators (pylint, Radon).
Traditionally our basic pipeline will comprise of the following elements:
- Creating test environment
- automatic source code pull (from GitHub)
- installing proper python version
- installing dependencies
- Running static code metrics:
- various raw metrics:
- tests coverage
- errors and style check
- Testing pulled source code
- unit tests
- integration tests
- Building proper python distribution package (
.whl) - Deploying to PyPI
It is time to rebuild our Jenkinsfile to reflect steps given above.
Jenkins anatomy
Jenkins uses its user service account to create job folders and files, manage work-space and its plugins. All configuration options are kept in .xml files in specific locations in Jenkins $HOME directory for jenkins user. On debian derived OS it is placed in /var/lib/jenkins/ directory. This is location of our agent, so called service account without interactive properties. It means it does not have designated shell, no /home/jenkins/ folder and one can not login to this account interactively.
In this directory Jenkins server stores information about its activity. Processed jobs in /var/lib/jenkins/jobs/ sub-folder (it contains logs and meta-data in .xml format for all or, specified number of runs, (this option can be set for each project). For example:
[mdyzma@devbox jenkins-python-test]$ tree /var/lib/jenkins/jobs/jenkins-python-test/branches/master
/var/lib/jenkins/jobs/jenkins-python-test/branches/master
├── builds
│ ├── 1
│ │ ├── 1.log
│ │ ├── 2.log
│ │ ├── 3.log
│ │ ├── 4.log
│ │ ├── build.xml
│ │ ├── changelog0.xml
│ │ ├── log
│ │ └── workflow
│ │ ├── 1.xml
│ │ ├── 2.xml
│ │ ├── 3.xml
│ │ └── 4.xml
│ ├── lastFailedBuild -> -1
│ ├── lastStableBuild -> 1
│ ├── lastSuccessfulBuild -> 1
│ └── legacyIds
├── config.xml
├── lastStable -> builds/lastStableBuild
├── lastSuccessful -> builds/lastSuccessfulBuild
├── name-utf8.txt
├── nextBuildNumber
└── scm-revision-hash.xmlMost important is config.xml, which is Jenkinsfile reflection and stores all steps, commands and logic translated to the xml format. Few years ago it was very important file, since it was used to back up all settings for Jenkins job and pipelines created via web UI. In our project all information is stored in Jenkinsfile.
Source code and its processing i.e. testing, is done in workspace sub-folder (/var/lib/jenkins/workspace/). This location is also accessible as a $WORKSPACE internal variable from the pipeline level.
Python environment for Jenkins
There are two bad news about jenkins and python virtual environments:
- Jenkins user by default uses shell (it means no
sourcecommand) - Jenkins user is non-interactive service account. It means it doesn’t run through the same set of scripts that alter the PATH environment variable for logged users. There is no
.bashrcand neither/etc/profilenor/etc/bash.bashrcconfigurations have any effect. As a consequence it usually uses interpreter located in/usr/bin/pythonor something like this (basic default system interpreter). If you have some Anaconda or Miniconda custom python installation in the system, there is a good chance, that jenkins will not see it.
There is also Jenkins special plugin called Shiny Panda, which allows managing python virtual environments in Jenkins, but I do not recommend it. It is easier and safer to configure proper python interpreter and environment using Miniconda and Jenkins settings.
So … Jenkins does not see our nice system Miniconda installation. We will have to make Jenkins use proper python interpreter and create virtual environments accessible in the workspace of the project every time job is run.
The best solution is to install Miniconda and manage environments from the jenkins user level. Miniconda will expose conda package manager, which is also capable to easily manage python virtual environments.
First, lets install Miniconda as jenkins user (all sh or bash command invoked in pipeline are executed as jenkins user), therefore we need to switch to the jenkins user and tell system what shell to use, since jenkins has none assigned by design. This set of commands will install latest miniconda in /var/lib/jenkins/miniconda3/:
[mdyzma@devbox jenkins-python-test]$ sudo su
[sudo] password for mdyzma: # sudo pass
root@devbox:/home/mdyzma/GitHub/jenkins-python-test# su - jenkins
$ cd /var/lib/jenkins # go to jenkins $HOME dir
$ wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
...
71% [====================================================> ] 41.491.372 508KB/s eta 39s
$ bash Miniconda3-latest-Linux-x86_64.sh
Welcome to Miniconda3 4.3.31
In order to continue the installation process, please review the license
agreement.
Please, press ENTER to continue
>>>
Miniconda3 will now be installed into this location:
/var/lib/jenkins/miniconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
...
installation finished.
Do you wish the installer to prepend the Miniconda3 install location
to PATH in your /var/lib/jenkins/.bashrc ? [yes|no]
[no] >>> #say no
Modifying .bashrc of environment processing element was pointless. As I mentioned, Jenkins usually connects to the service via non-interactive shell, so neither /etc/profile nor /etc/bash.bashrc configurations would have any effect. To make it work two things need to be done:
- change main Jenkins shell to bash (this will activate
sourcecommand) - make conda binaries to be visible for jenkins user shell from the pipeline
To activate source command we need to switch to Bourne-again shell (bash) as default shell. Go to Manage Jenkins -> Configure System -> Shell -> Shell executable (or http://localhost:8080/configure), and input /bin/bash into the form. Save changes.
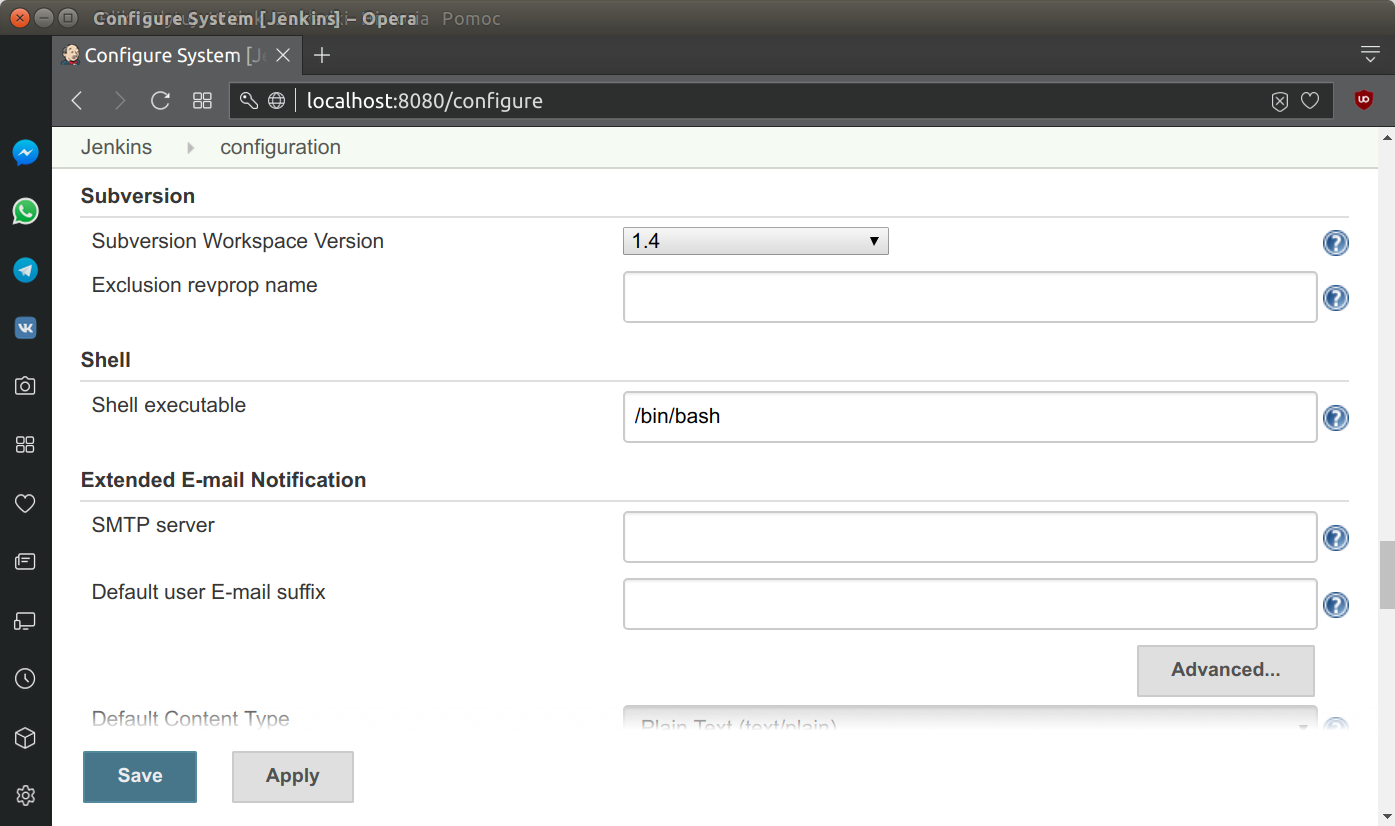
Still, we have to expose miniconda binaries to the non-login Jenkins profile. Declarative Pipelines support an environment directive, which allows defining environmental variables. Environment directive used in the top-level pipeline block will apply to all steps within the Pipeline (see: Jenkins documentation). We will use it to modify PATH variable.
Now we can easily create and destroy python virtual environment within jenkins pipeline. We can also install all dependencies locally. The post block of the script will remove this environment when pipeline finishes.
Sadly, every time we call the sh command, jenkins will create new temporary shell. This means that if we use source activate in a sh it will be only sources in that shell session. Therefore, we have to activate env in each stage or new sh command we invoke. Let me show you how it looks like:
Jenkinsfile
pipeline {
agent any
triggers {
pollSCM('*/5 * * * 1-5')
}
options {
skipDefaultCheckout(true)
// Keep the 10 most recent builds
buildDiscarder(logRotator(numToKeepStr: '10'))
timestamps()
}
environment {
PATH="/var/lib/jenkins/miniconda3/bin:$PATH"
}
stages {
stage ("Code pull"){
steps{
checkout scm
}
}
stage('Build environment') {
steps {
sh '''conda create --yes -n ${BUILD_TAG} python
source activate ${BUILD_TAG}
pip install -r requirements.txt
'''
}
}
stage('Test environment') {
steps {
sh '''source activate ${BUILD_TAG}
pip list
which pip
which python
'''
}
}
}
post {
always {
sh 'conda remove --yes -n ${BUILD_TAG} --all'
}
filure {
echo "Send e-mail, when failed"
}
}
}Basic frames for pipeline was enclosed in the listing above. GitHub is checked with */5 * * * 1-5 frequency (at every 5th minute on every day-of-week from Monday through Friday). Default code checkout was suppressed in pipeline options. In options, we have also established rules regarding keeping old builds (Round Robin rotation of last 10 builds) and we also established, that each log entry will be timestamped. During first stage we create conda environment and install all project dependencies. During second stage we check interpreter localization. There is also possibility to create separate environment for different python versions (i.e. 2.7 branch). All is needed is python version in create command i.e.: conda create --yes -n env_name python=2.
${BUILD_TAG} is a string created by Jenkins from combination of jenkins-${JOB_NAME}-${BUILD_NUMBER} variables. Convenient to put into a resource file or for easier identification of virtual environment.
Last, but not least is post block for entire pipeline. Always when pipeline finishes (regardless the status), conda environment will be purged from the disk.
Quick peek at conda envs list shows, that system works (38 jobs ran and there is only one — root environment):
[jenkins@devbox ~]$ conda env list
# conda environments:
#
root * /var/lib/jenkins/miniconda3
Static code metrics
In this part we will configure static code analysis tools to determine complexity and non-standard practices in the code base. In attempt to provide top quality of the code, we can automate following checks to be done each time we commit changes:
- Raw code metrics:
- SLOC, comment lines, blank lines, &c. (
clockorsloccount) - Cyclomatic Complexity (i.e. McCabe’s Complexity)
- the Maintainability Index (a Visual Studio metric)
- SLOC, comment lines, blank lines, &c. (
- Code coverage reports (
coverage,pytest-cov) - PEP8 check (
pylint)
There is large diversity of formats among tools. They can produce reports as JSON, HTML and sometimes XML.
Coverage and pytest-cov produce XML outputs in JUnit format. Very good option to quickly obtain test coverage report and progress graph using basic jenkins plugins. .xml files very easily integrate with Jenkins toolkit. To process this reports we will use JUnit Plugin.
Pylint can generate its own output files, which can be read by Violation Columns Plugin.
Radon generates JSON outputs, which are the most problematic, since Jenkins does not have specific plugin for this tool. One possible option is to use allure tool to convert them to nice HTML reports and serve using general purpose HTML Publisher Plugin.
Let’s start with code raw metrics.
Raw code metrics
We will use Radon package to produce data in json format. Then json and report will be archived (moved to the build/ folder).
...
stage('Static code metrics') {
steps {
echo "Raw metrics"
sh ''' source activate ${BUILD_TAG}
radon raw --json irisvmpy/ > raw_report.json
radon cc --json irisvmpy/ > cc_report.json
radon mi --json irisvmpy/ > mi_report.json
//TODO: add conversion and HTML publisher step
'''
}
}
...Code coverage report
Jenkins has very powerful CoberturaPublisher Plugin. We will create proper .xml report with code coverage using coverage package and publish it to HTML using post section of this step. It will always grab info located in /reports/coverage.xml and transform it to the HTML report visible in the side menu of the Jenkins project.
...
stage('Static code metrics') {
steps {
echo "Code Coverage"
sh ''' source activate ${BUILD_TAG}
coverage run irisvmpy/iris.py 1 1 2 3
python -m coverage xml -o ./reports/coverage.xml
'''
}
post{
always{
step([$class: 'CoberturaPublisher',
autoUpdateHealth: false,
autoUpdateStability: false,
coberturaReportFile: 'reports/coverage.xml',
failNoReports: false,
failUnhealthy: false,
failUnstable: false,
maxNumberOfBuilds: 10,
onlyStable: false,
sourceEncoding: 'ASCII',
zoomCoverageChart: false])
}
}
}
...Code coverage report is accessible only from classical Jenkins view. It appears as a link on the left side menu and as a miniature in main project view.
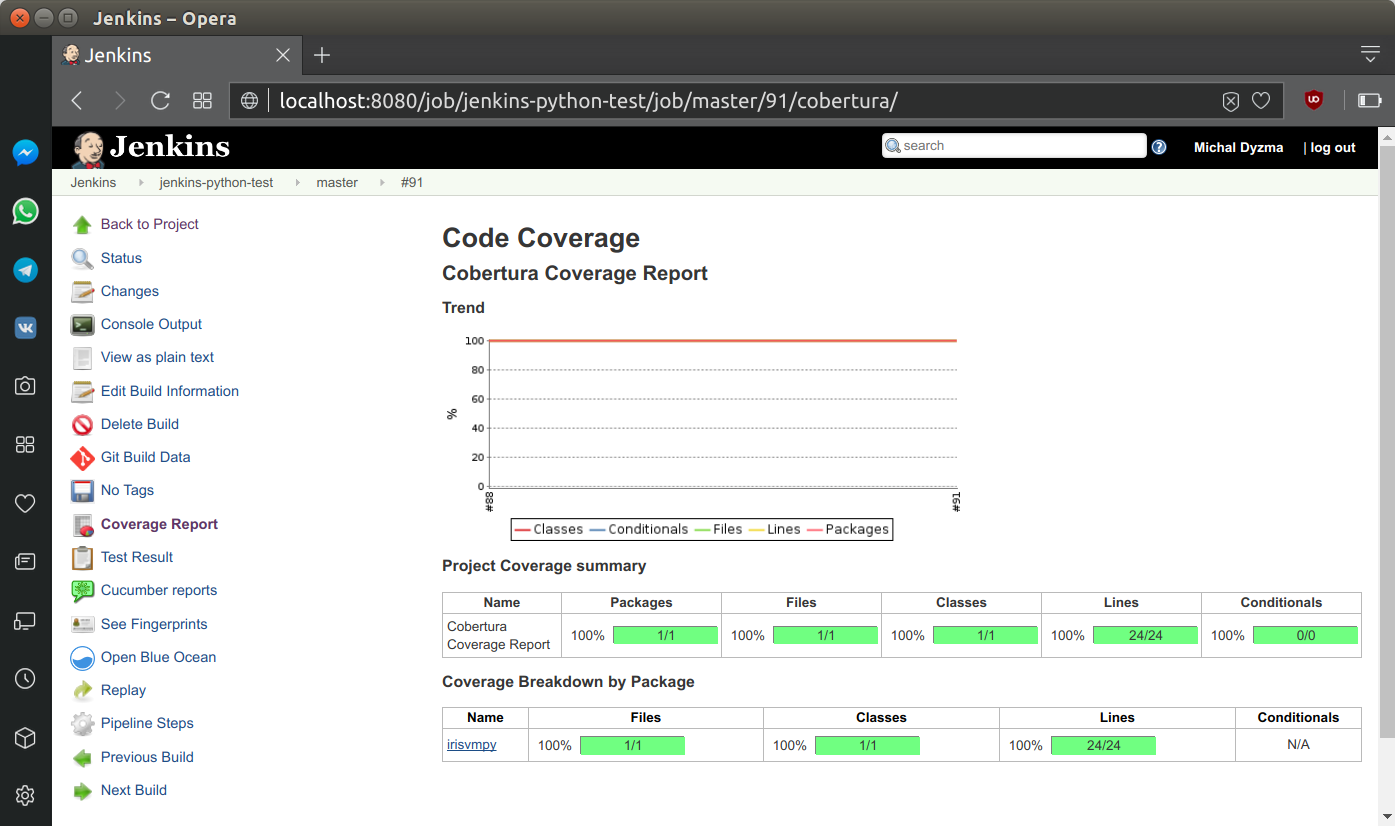
PEP8 & code metrics reports
We can also check code errors and style violations. Unfortunately pylint has tendency to return a non-zero exit code even only if a small warning issue was found. Only when everything was fine, 0 is returned. All non-zero steps are signal for Jenkins to fail the pipeline. This is unacceptable in case of small style differences. In this situation I use pylint report as a “tip” and allow it to fail. My shell command will always return true.
...
stage('Static code metrics') {
steps {
echo "PEP8 style check"
sh ''' source activate ${BUILD_TAG}
pylint --disable=C irisvmpy || true
'''
}
}
...Testing
Two types of testing are essential:
- Unit tests (
pytestorunittest) - Integration tests (
behave)
In case of more complex software integration tests may be added to the list. According to agile “outside-in” approach first we should write integration tests (more general test), then precise unit tests (classic TDD). Test results will be stored for comparison. JUnit plugin gives quick and easy access to the tests.
Unit tests
Stage with unit tests and their archiving:
...
stage('Unit tests') {
steps {
sh ''' source activate ${BUILD_TAG}
python -m pytest --verbose --junit-xml test-reports/results.xml
'''
}
post {
always {
// Archive unit tests for the future
junit allowEmptyResults: true, testResults: 'test-reports/results.xml', fingerprint: true
}
}
}
...Tests report is accessible on special Tests tab:
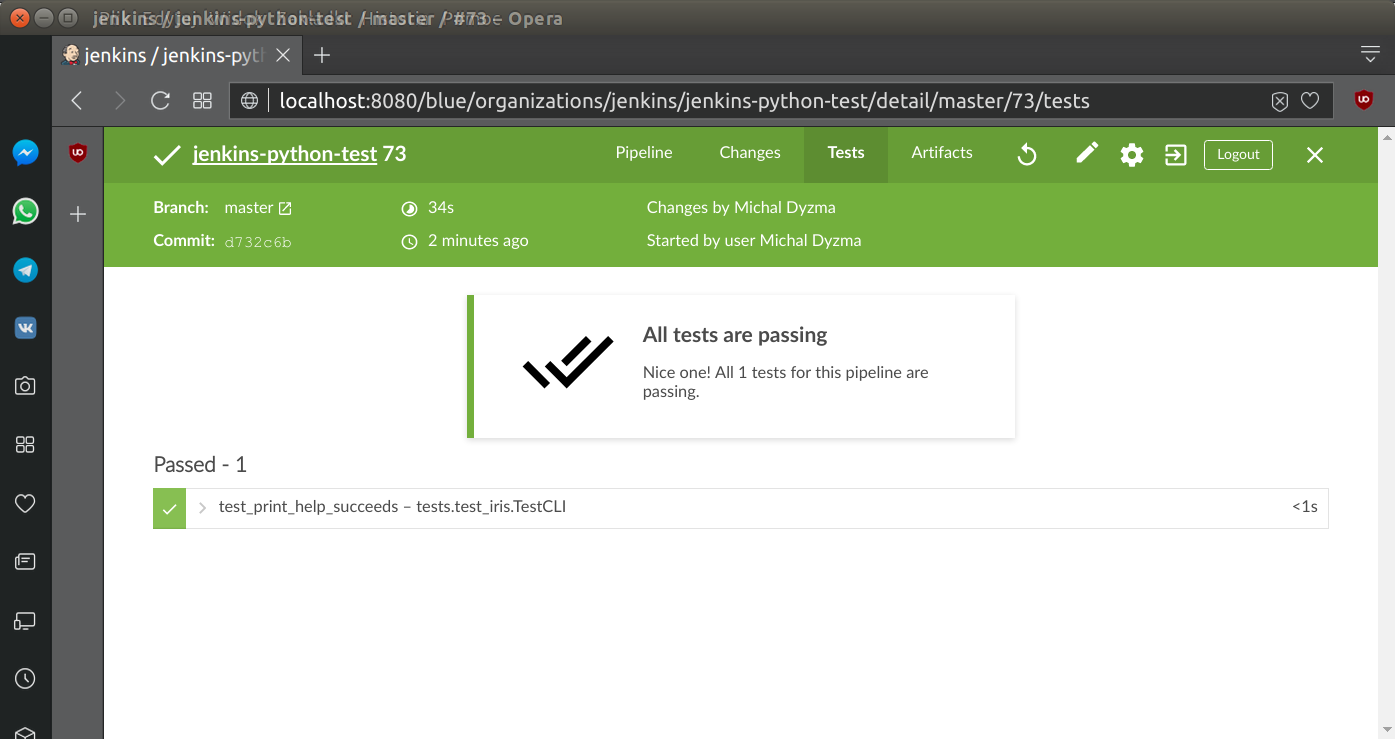
Integration tests
Behave package is able to return results of integration tests in JSON format, however this format is not compatible with any Jenkins cucumber repoprt plugins. There is a workaround to this problem. Actually two.
- Use custom json formatter (there is gist published on GitHub with formatter compatible with cuccumber plugin style)). How to use user-specific formatters with behave, please checks behave documentation.
- Use
behave2cucumberpackage, which adds another dependency to te project. Also, last post post in this discussions suggests, thatbehave2cucumberfails in some cases.
first option
...
stage('integration tests') {
steps {
sh ''' source activate ${BUILD_TAG}
behave -f=formatters.cucumber_json:PrettyCucumberJSONFormatter -o ./reports/integration.json
'''
}
post {
always {
cucumber (fileIncludePattern: '**/integration*.json',
jsonReportDirectory: './reports/',
parallelTesting: true,
sortingMethod: 'ALPHABETICAL')
}
}
}
...second option
...
stage('integration tests') {
steps {
sh ''' source activate ${BUILD_TAG}
behave -f=json.pretty -o ./reports/integration.json
python -m behave2cucumber ./reports/integration.json
'''
}
post {
always {
cucumber (fileIncludePattern: '**/integration*.json',
jsonReportDirectory: './reports/',
parallelTesting: true,
sortingMethod: 'ALPHABETICAL')
}
}
}
...Building python package
We will also build wheel package when all tests and code metrics was completed. Jenkins will check internal variable currentBuild.result. If nothing changed or there was no failure, Jenkins will initialize setup.py script. When build process is finished Jenkins will archive .whl file and store it for download. Blue Ocean and classical Jenkins create “Artifacts” page with all files marked to archivisation during pipeline run.
...
stage('Build package') {
when {
expression {
currentBuild.result == null || currentBuild.result == 'SUCCESS'
}
}
steps {
sh ''' source activate ${BUILD_TAG}
python setup.py bdist_wheel
'''
}
post {
always {
// Archive unit tests for the future
archiveArtifacts allowEmptyArchive: true, artifacts: 'dist/*whl', fingerprint: true)
}
}
}
...As we can see python package was archived as expected:
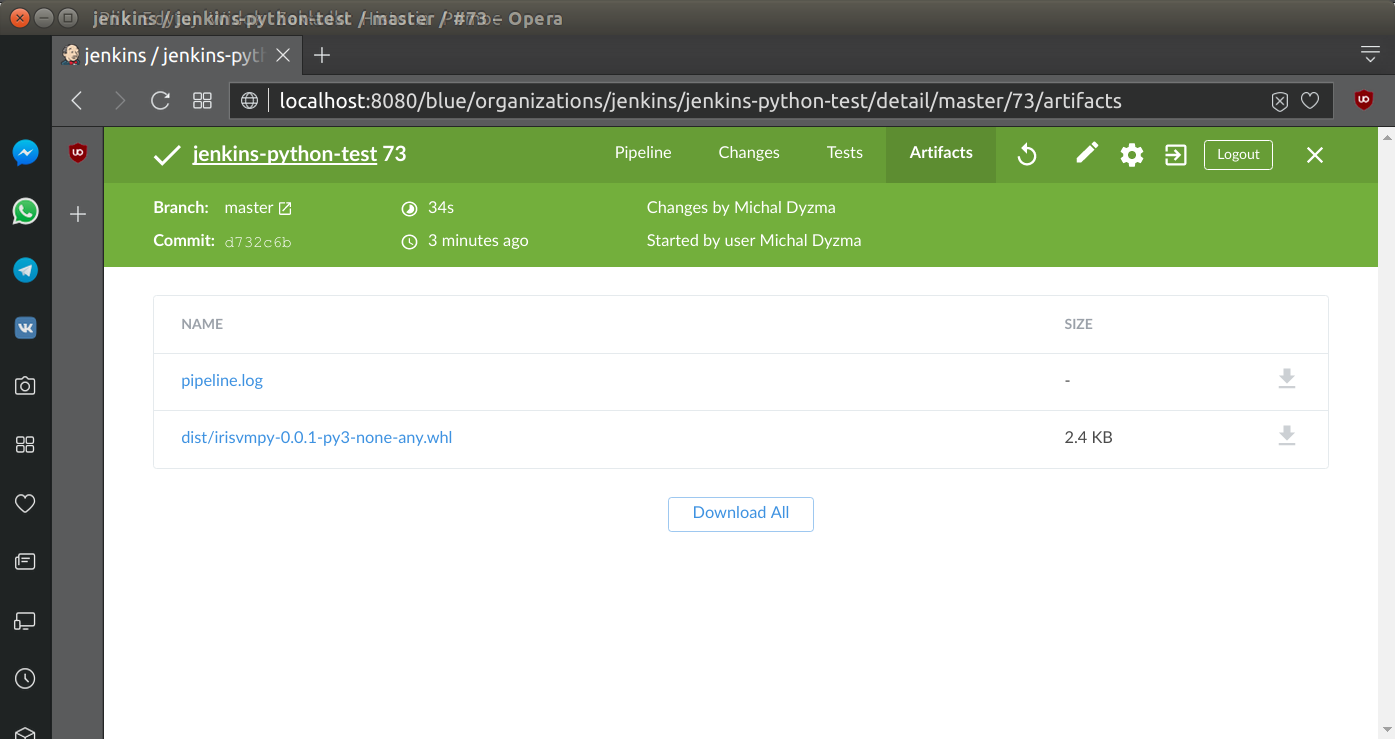
Deployment
Package, which passed tests and was successfully built will be uploaded to PyPI server.
...
stage("Deploy to PyPI") {
}
steps {
sh "twine upload dist/*"
}
}
...Summary
To summ up. Here is listing of the complete Jenkinsfile:
pipeline {
agent any
triggers {
pollSCM('*/5 * * * 1-5')
}
options {
skipDefaultCheckout(true)
// Keep the 10 most recent builds
buildDiscarder(logRotator(numToKeepStr: '10'))
timestamps()
}
environment {
PATH="/var/lib/jenkins/miniconda3/bin:$PATH"
}
stages {
stage ("Code pull"){
steps{
checkout scm
}
}
stage('Build environment') {
steps {
echo "Building virtualenv"
sh ''' conda create --yes -n ${BUILD_TAG} python
source activate ${BUILD_TAG}
pip install -r requirements/dev.txt
'''
}
}
stage('Static code metrics') {
steps {
echo "Raw metrics"
sh ''' source activate ${BUILD_TAG}
radon raw --json irisvmpy > raw_report.json
radon cc --json irisvmpy > cc_report.json
radon mi --json irisvmpy > mi_report.json
sloccount --duplicates --wide irisvmpy > sloccount.sc
'''
echo "Test coverage"
sh ''' source activate ${BUILD_TAG}
coverage run irisvmpy/iris.py 1 1 2 3
python -m coverage xml -o reports/coverage.xml
'''
echo "Style check"
sh ''' source activate ${BUILD_TAG}
pylint irisvmpy || true
'''
}
post{
always{
step([$class: 'CoberturaPublisher',
autoUpdateHealth: false,
autoUpdateStability: false,
coberturaReportFile: 'reports/coverage.xml',
failNoReports: false,
failUnhealthy: false,
failUnstable: false,
maxNumberOfBuilds: 10,
onlyStable: false,
sourceEncoding: 'ASCII',
zoomCoverageChart: false])
}
}
}
stage('Unit tests') {
steps {
sh ''' source activate ${BUILD_TAG}
python -m pytest --verbose --junit-xml reports/unit_tests.xml
'''
}
post {
always {
// Archive unit tests for the future
junit (allowEmptyResults: true,
testResults: './reports/unit_tests.xml',
fingerprint: true)
}
}
}
stage('Integration tests') {
steps {
sh ''' source activate ${BUILD_TAG}
behave -f=formatters.cucumber_json:PrettyCucumberJSONFormatter -o ./reports/integration.json
'''
}
post {
always {
cucumber (fileIncludePattern: '**/*.json',
jsonReportDirectory: './reports/',
parallelTesting: true,
sortingMethod: 'ALPHABETICAL')
}
}
}
stage('Build package') {
when {
expression {
currentBuild.result == null || currentBuild.result == 'SUCCESS'
}
}
steps {
sh ''' source activate ${BUILD_TAG}
python setup.py bdist_wheel
'''
}
post {
always {
// Archive unit tests for the future
archiveArtifacts (allowEmptyArchive: true,
artifacts: 'dist/*whl',
fingerprint: true)
}
}
}
stage("Deploy to PyPI") {
}
steps {
sh "twine upload dist/*"
}
}
}
post {
always {
sh 'conda remove --yes -n ${BUILD_TAG} --all'
}
failure {
emailext (
subject: "FAILED: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]'",
body: """<p>FAILED: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]':</p>
<p>Check console output at "<a href='${env.BUILD_URL}'>${env.JOB_NAME} [${env.BUILD_NUMBER}]</a>"</p>""",
recipientProviders: [[$class: 'DevelopersRecipientProvider']]
)
}
}
}Running entire pipeline results all green, successful run:
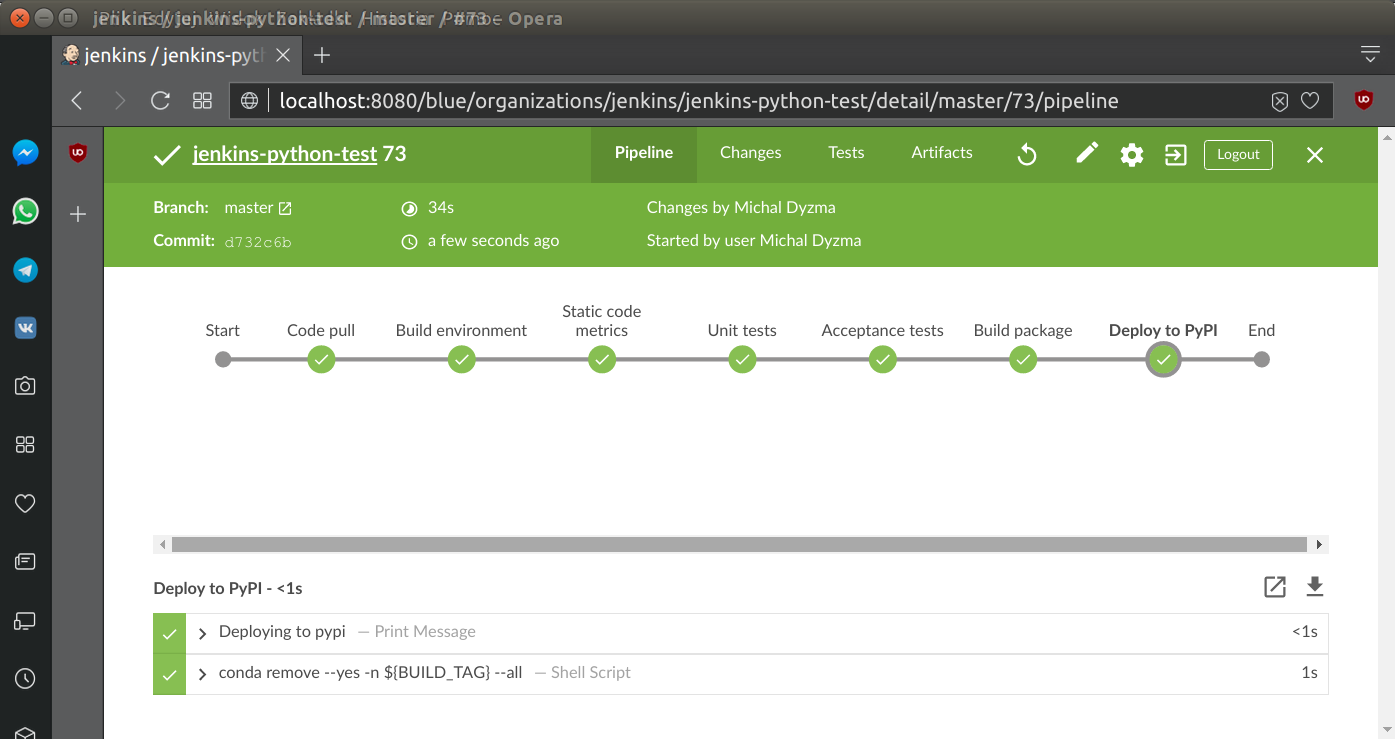
| layout | title | section |
|---|---|---|
|
documentation |
Build a Python app with PyInstaller |
doc |
Table of Contents
- Fork and clone the sample repository
- Create your Pipeline project in Jenkins
- Create your initial Pipeline as a Jenkinsfile
- Add a test stage to your Pipeline
- Add a final deliver stage to your Pipeline
- Follow up (optional)
- Wrapping up
This tutorial shows you how to use Jenkins to orchestrate building a simple
Python application with PyInstaller.
If you are a Python developer who is new to CI/CD concepts, or you might be
familiar with these concepts but don’t know how to implement building your
application using Jenkins, then this tutorial is for you.
The simple Python application (which you’ll obtain from a sample repository on
GitHub) is a command line tool «add2vals» that outputs the addition of two
values. If at least one of the values is a string, «add2vals» treats both values
as a string and instead concatenates the values. The «add2» function in the
«calc» library (which «add2vals» imports) is accompanied by a set of unit tests.
These are tested with pytest to check that this function works as expected and
the results are saved to a JUnit XML report.
The delivery of the «add2vals» tool through PyInstaller converts this tool into
a standalone executable file for Linux, which you can download through Jenkins
and execute at the command line on Linux machines without Python.
Note: Unlike the other tutorials in this documentation, this tutorial
requires approximately 500 MB more Docker image data to be downloaded.
Duration: This tutorial takes 20-40 minutes to complete (assuming you’ve
already met the prerequisites below). The exact duration will
depend on the speed of your machine and whether or not you’ve already
run Jenkins in Docker from another tutorial.
You can stop this tutorial at any point in time and continue from where you left
off.
If you’ve already run though another tutorial, you can skip the
Prerequisites and Run Jenkins in
Docker sections below and proceed on to forking the
sample repository. (Just ensure you have
Git installed locally.) If you need to
restart Jenkins, simply follow the restart instructions in
Stopping and restarting Jenkins and then
proceed on.
Fork and clone the sample repository
Obtain the simple «add» Python application from GitHub, by forking the sample
repository of the application’s source code into your own GitHub account and
then cloning this fork locally.
-
Ensure you are signed in to your GitHub account. If you don’t yet have a
GitHub account, sign up for a free one on the GitHub
website. -
Fork the
simple-python-pyinstaller-app
on GitHub into your local GitHub account. If you need help with this process,
refer to the Fork A Repo
documentation on the GitHub website for more information. -
Clone your forked
simple-python-pyinstaller-apprepository (on GitHub)
locally to your machine. To begin this process, do either of the following
(where<your-username>is the name of your user account on your operating
system):-
If you have the GitHub Desktop app installed on your machine:
-
In GitHub, click the green Clone or download button on your forked
repository, then Open in Desktop. -
In GitHub Desktop, before clicking Clone on the Clone a Repository dialog
box, ensure Local Path for:-
macOS is
/Users/<your-username>/Documents/GitHub/simple-python-pyinstaller-app -
Linux is
/home/<your-username>/GitHub/simple-python-pyinstaller-app -
Windows is
C:Users<your-username>DocumentsGitHubsimple-python-pyinstaller-app
-
-
-
Otherwise:
-
Open up a terminal/command line prompt and
cdto the appropriate directory
on:-
macOS —
/Users/<your-username>/Documents/GitHub/ -
Linux —
/home/<your-username>/GitHub/ -
Windows —
C:Users<your-username>DocumentsGitHub(although use a Git
bash command line window as opposed to the usual Microsoft command prompt)
-
-
Run the following command to continue/complete cloning your forked repo:
git clone https://github.com/YOUR-GITHUB-ACCOUNT-NAME/simple-python-pyinstaller-app
whereYOUR-GITHUB-ACCOUNT-NAMEis the name of your GitHub account.
-
-
Create your Pipeline project in Jenkins
-
Go back to Jenkins, log in again if necessary and click create new jobs
under Welcome to Jenkins!
Note: If you don’t see this, click New Item at the top left. -
In the Enter an item name field, specify the name for your new Pipeline
project (e.g.simple-python-pyinstaller-app). -
Scroll down and click Pipeline, then click OK at the end of the page.
-
( Optional ) On the next page, specify a brief description for your Pipeline
in the Description field (e.g.An entry-level Pipeline demonstrating how to)
use Jenkins to build a simple Python application with PyInstaller. -
Click the Pipeline tab at the top of the page to scroll down to the
Pipeline section. -
From the Definition field, choose the Pipeline script from SCM option.
This option instructs Jenkins to obtain your Pipeline from Source Control
Management (SCM), which will be your locally cloned Git repository. -
From the SCM field, choose Git.
-
In the Repository URL field, specify the directory path of your locally
cloned repository above,
which is from your user account/home directory on your host machine, mapped to
the/homedirectory of the Jenkins container — i.e.-
For macOS —
/home/Documents/GitHub/simple-python-pyinstaller-app -
For Linux —
/home/GitHub/simple-python-pyinstaller-app -
For Windows —
/home/Documents/GitHub/simple-python-pyinstaller-app
-
-
Click Save to save your new Pipeline project. You’re now ready to begin
creating yourJenkinsfile, which you’ll be checking into your locally cloned
Git repository.
Create your initial Pipeline as a Jenkinsfile
You’re now ready to create your Pipeline that will automate building your Python
application with PyInstaller in Jenkins. Your Pipeline will be created as a
Jenkinsfile, which will be committed to your locally cloned Git repository
(simple-python-pyinstaller-app).
This is the foundation of «Pipeline-as-Code», which treats the continuous
delivery pipeline a part of the application to be versioned and reviewed like
any other code. Read more about Pipeline and what a Jenkinsfile is in the
Pipeline and Using
a Jenkinsfile sections of the User Handbook.
First, create an initial Pipeline with a «Build» stage that executes the first
part of the entire production process for your application. This «Build» stage
downloads a Python Docker image and runs it as a Docker container, which in turn
compiles your simple Python application into byte code.
-
Using your favorite text editor or IDE, create and save new text file with the
nameJenkinsfileat the root of your localsimple-python-pyinstaller-app
Git repository. -
Copy the following Declarative Pipeline code and paste it into your empty
Jenkinsfile:pipeline { agent none // (1) stages { stage('Build') { // (2) agent { docker { image 'python:2-alpine' // (3) } } steps { sh 'python -m py_compile sources/add2vals.py sources/calc.py' // (4) stash(name: 'compiled-results', includes: 'sources/*.py*') // (5) } } } }-
The
agentsection with thenone
parameter specified at the top of this Pipeline code block means that no global
agent will be allocated for the entire Pipeline’s execution and that each
stagedirective must specify its own
agentsection. -
Defines a
stage(directive) called
Buildthat appears on the Jenkins UI. -
This
imageparameter (of theagent
section’sdockerparameter) downloads the
python:2-alpineDocker image (if it’s not
already available on your machine) and runs this image as a separate container.
This means that:-
You’ll have separate Jenkins and Python containers running locally in Docker.
-
The Python container becomes the agent that
Jenkins uses to run theBuildstage of your Pipeline project. However,
this container is short-lived — its lifespan is only that of the duration of
yourBuildstage’s execution.
-
-
This
sh
step (of thestepssection) runs the
Python command to compile your application and itscalclibrary into byte code
files (each with.pycextension), which are placed into thesources
workspace directory (within the
/var/jenkins_home/workspace/simple-python-pyinstaller-appdirectory in the
Jenkins container). -
This
stash
step (of thebasic stepssection) saves
the Python source code and compiled byte code files (with.pycextension) from thesources
workspace directory for use in later stages.
-
-
Save your edited
Jenkinsfileand commit it to your local
simple-python-pyinstaller-appGit repository. E.g. Within the
simple-python-pyinstaller-appdirectory, run the commands:
git add .
then
git commit -m "Add initial Jenkinsfile" -
Go back to Jenkins again, log in again if necessary and click Open Blue
Ocean on the left to access Jenkins’s Blue Ocean interface. -
In the This job has not been run message box, click Run, then quickly
click the OPEN link which appears briefly at the lower-right to see Jenkins
running your Pipeline project. If you weren’t able to click the OPEN link,
click the row on the main Blue Ocean interface to access this feature.
Note: You may need to wait a few minutes for this first run to complete.
After making a clone of your localsimple-python-pyinstaller-appGit
repository itself, Jenkins:-
Initially queues the project to be run on the agent.
-
Runs the
Buildstage (defined in theJenkinsfile) on the Python
container. During this time, Python uses thepy_compilemodule to compile
the code of your Python application and itscalclibrary into byte code,
which are stored in thesourcesworkspace directory (within the Jenkins
home directory).
The Blue Ocean interface turns green if Jenkins compiled your Python application
successfully.
-
-
Click the X at the top-right to return to the main Blue Ocean interface.


Add a test stage to your Pipeline
-
Go back to your text editor/IDE and ensure your
Jenkinsfileis open. -
Copy and paste the following Declarative Pipeline syntax immediately under the
Buildstage of yourJenkinsfile:stage('Test') { agent { docker { image 'qnib/pytest' } } steps { sh 'py.test --junit-xml test-reports/results.xml sources/test_calc.py' } post { always { junit 'test-reports/results.xml' } } }
so that you end up with:
pipeline { agent none stages { stage('Build') { agent { docker { image 'python:2-alpine' } } steps { sh 'python -m py_compile sources/add2vals.py sources/calc.py' stash(name: 'compiled-results', includes: 'sources/*.py*') } } stage('Test') { // (1) agent { docker { image 'qnib/pytest' // (2) } } steps { sh 'py.test --junit-xml test-reports/results.xml sources/test_calc.py' // (3) } post { always { junit 'test-reports/results.xml' // (4) } } } } }-
Defines a
stage(directive) called
Testthat appears on the Jenkins UI. -
This
imageparameter (of theagent
section’sdockerparameter) downloads the
qnib:pytestDocker image (if it’s not
already available on your machine) and runs this image as a separate container.
This means that:-
You’ll have separate Jenkins and pytest containers running locally in Docker.
-
The pytest container becomes the agent that
Jenkins uses to run theTeststage of your Pipeline project. This
container’s lifespan lasts the duration of yourTeststage’s execution.
-
-
This
sh
step (of thestepssection) executes
pytest’spy.testcommand onsources/test_calc.py, which runs a set of unit
tests (defined intest_calc.py) on the «calc» library’sadd2function (used
by your simple Python applicationadd2vals). The:-
--junit-xml test-reports/results.xmloption makespy.testgenerate a JUnit
XML report, which is saved totest-reports/results.xml(within the
/var/jenkins_home/workspace/simple-python-pyinstaller-appdirectory in the
Jenkins container).
-
-
This
junit
step (provided by the JUnit Plugin) archives the
JUnit XML report (generated by thepy.testcommand above) and exposes the
results through the Jenkins interface. In Blue Ocean, the results are accessible
through the Tests page of a Pipeline run. The
postsection’salwayscondition that
contains thisjunitstep ensures that the step is always executed at the
completion of theTeststage, regardless of the stage’s outcome.
-
-
Save your edited
Jenkinsfileand commit it to your local
simple-python-pyinstaller-appGit repository. E.g. Within the
simple-python-pyinstaller-appdirectory, run the commands:
git stage .
then
git commit -m "Add 'Test' stage" -
Go back to Jenkins again, log in again if necessary and ensure you’ve accessed
Jenkins’s Blue Ocean interface. -
Click Run at the top left, then quickly click the OPEN link which appears
briefly at the lower-right to see Jenkins running your amended Pipeline
project. If you weren’t able to click the OPEN link, click the top row
on the Blue Ocean interface to access this feature.
Note: It may take a few minutes for theqnib:pytestDocker image to
download (if this hasn’t already been done).
If your amended Pipeline ran successfully, here’s what the Blue Ocean
interface should look like. Notice the additional «Test» stage. You can click
on the previous «Build» stage circle to access the output from that stage. -
Click the X at the top-right to return to the main Blue Ocean interface.

Add a final deliver stage to your Pipeline
-
Go back to your text editor/IDE and ensure your
Jenkinsfileis open. -
Copy and paste the following Declarative Pipeline syntax immediately under the
Teststage of yourJenkinsfile:stage('Deliver') { agent any environment { VOLUME = '$(pwd)/sources:/src' IMAGE = 'cdrx/pyinstaller-linux:python2' } steps { dir(path: env.BUILD_ID) { unstash(name: 'compiled-results') sh "docker run --rm -v ${VOLUME} ${IMAGE} 'pyinstaller -F add2vals.py'" } } post { success { archiveArtifacts "${env.BUILD_ID}/sources/dist/add2vals" sh "docker run --rm -v ${VOLUME} ${IMAGE} 'rm -rf build dist'" } } }
and add a
skipStagesAfterUnstableoption so that you end up with:pipeline { agent none options { skipStagesAfterUnstable() } stages { stage('Build') { agent { docker { image 'python:2-alpine' } } steps { sh 'python -m py_compile sources/add2vals.py sources/calc.py' stash(name: 'compiled-results', includes: 'sources/*.py*') } } stage('Test') { agent { docker { image 'qnib/pytest' } } steps { sh 'py.test --junit-xml test-reports/results.xml sources/test_calc.py' } post { always { junit 'test-reports/results.xml' } } } stage('Deliver') { // (1) agent any environment { // (2) VOLUME = '$(pwd)/sources:/src' IMAGE = 'cdrx/pyinstaller-linux:python2' } steps { dir(path: env.BUILD_ID) { // (3) unstash(name: 'compiled-results') // (4) sh "docker run --rm -v ${VOLUME} ${IMAGE} 'pyinstaller -F add2vals.py'" // (5) } } post { success { archiveArtifacts "${env.BUILD_ID}/sources/dist/add2vals" // (6) sh "docker run --rm -v ${VOLUME} ${IMAGE} 'rm -rf build dist'" } } } } }-
Defines a
stage(directive) called
Deliverthat appears on the Jenkins UI. -
This
environment
block defines two variables which will be used later in the ‘Deliver’ stage. -
This
dir
step (of thebasic stepssection) creates a new subdirectory
named by the build number. The final program will be created in that directory by pyinstaller.
BUILD_IDis one of the pre-defined Jenkins environment variables and is available in all jobs. -
This
unstash
step (of thebasic stepssection) restores
the Python source code and compiled byte code files (with.pycextension) from the previously saved stash
image (if it’s not already available on your machine) and runs this image as a
separate container. This means that:-
You’ll have separate Jenkins and PyInstaller (for Linux) containers running
locally in Docker. -
The PyInstaller container becomes the agent
that Jenkins uses to run theDeliverstage of your Pipeline project. This
container’s lifespan lasts the duration of yourDeliverstage’s execution.
-
-
This
sh
step (of thestepssection) executes
thepyinstallercommand (in the PyInstaller container) on your simple Python
application. This bundles youradd2vals.pyPython application into a single
standalone executable file (via the--onefileoption) and outputs the this
file to thedistworkspace directory (within the Jenkins home directory).
Although this step consists of a single command, as a general principle, it’s a
good idea to keep your Pipeline code (i.e. theJenkinsfile) as tidy as
possible and place more complex build steps (particularly for stages consisting
of 2 or more steps) into separate shell script files like thedeliver.shfile.
This ultimately makes maintaining your Pipeline code easier, especially if your
Pipeline gains more complexity. -
This
archiveArtifacts
step (provided as part of Jenkins core) archives the standalone executable file
(generated by thepyinstallercommand above atdist/add2valswithin the
Jenkins home’s workspace directory) and exposes this file through the Jenkins
interface. In Blue Ocean, archived artifacts like these are accessible through
the Artifacts page of a Pipeline run. The
postsection’ssuccesscondition that
contains thisarchiveArtifactsstep ensures that the step is executed at the
completion of theDeliverstage only if this stage completed successfully.
-
-
Save your edited
Jenkinsfileand commit it to your local
simple-python-pyinstaller-appGit repository. E.g. Within the
simple-python-pyinstaller-appdirectory, run the commands:
git stage .
then
git commit -m "Add 'Deliver' stage" -
Go back to Jenkins again, log in again if necessary and ensure you’ve accessed
Jenkins’s Blue Ocean interface. -
Click Run at the top left, then quickly click the OPEN link which appears
briefly at the lower-right to see Jenkins running your amended Pipeline
project. If you weren’t able to click the OPEN link, click the top row
on the Blue Ocean interface to access this feature.
Note: It may take a few minutes for thecdrx/pyinstaller-linuxDocker
image to download (if this hasn’t already been done).
If your amended Pipeline ran successfully, here’s what the Blue Ocean
interface should look like. Notice the additional «Deliver» stage. Click on
the previous «Test» and «Build» stage circles to access the outputs from those
stages.Here’s what the output of the «Deliver» stage should look like, showing you the
results of PyInstaller bundling your Python application into a single standalone
executable file. -
Click the X at the top-right to return to the main Blue Ocean interface,
which lists your previous Pipeline runs in reverse chronological order.



Follow up (optional)
If you use Linux, you can try running the standalone add2vals application you
generated with PyInstaller locally on your machine. To do this:
-
From the main Blue Ocean interface, access your last Pipeline run you
performed above. To do this,
click the top row (representing the most recent Pipeline run) on the main Blue
Ocean’s Activity page. -
On the results page of the Pipeline run, click Artifacts at the top right
to access the Artifacts page. -
In the list of artifacts, click the down-arrow icon at the far right of the
dist/add2vals artifact item to download the standalone executable file to
your browser’s «Downloads» directory. -
Back in your operating system’s terminal prompt,
cdto your browser’s
«Downloads» directory. -
Make the
add2valsfile executable — i.e.chmod a+x add2vals -
Run the command
./add2valsand follow the instructions provided by your app.

Wrapping up
Well done! You’ve just used Jenkins to build a simple Python application!
The «Build», «Test» and «Deliver» stages you created above are the basis for
building more complex Python applications in Jenkins, as well as Python
applications that integrate with other technology stacks.
Because Jenkins is extremely extensible, it can be modified and configured to
handle practically any aspect of build orchestration and automation.
To learn more about what Jenkins can do, check out:
-
The Tutorials overview page for other introductory
tutorials. -
The User Handbook for more detailed information about using
Jenkins, such as Pipelines (in particular
Pipeline syntax) and the
Blue Ocean interface. -
The Jenkins blog for the latest events, other tutorials and
updates.
link:_partials/_feedback-footer.html[]
I want to share my experience in implementing the Jenkins pipeline. In this tutorial, we will implement the Jenkins CI/CD Pipeline for Python applications. We will be building a pipeline as code, aka Declarative pipeline.
What is the declarative pipeline? The pipeline is the new feature of Jenkins, where we can write the Jenkins job as a sequence of steps. It is written in groovy. Since, it is a script we can keep it along with our code and can be easily replicated to other projects. We can also invoke Jenkins plugins in pipeline scripts.
Directives: Jenkins pipeline provides a list of directives that will be used in defining various operations.
- Agent: specifies in which environment the job will be run.
- Stages: a collection of stage or a working bundle.
- Stage: a set of steps to perform a certain operation.
- Steps: one or more steps that will be executed under each stage. Typically, it is a command.
- Post: it will run on job completion. we can trigger different options based on build status, if successful, unstable, or failure.
Step 1: choosing a server and setting working directories. By default, Jenkins chooses the home directory of the user to run jobs. We can change this if required.
agent {
node {
label "my-local-suer'
customWorkspace "/projects/debitcardcollection"
}
}Agent: specifies which environment we need to run the job. It can be server/host, docker, or Kubernetes.
- To run in any available server or host, we can specify agent as «any.»
- To run a specific server, we need to specify it in «label.»
- To add extra parameters like a custom working directory, we need to use node. «customWorkspace» is where our code will be checked out, and steps will be performed.
Checking out code: To checkout the code, we used the GIT plugin. We need to specify the following things.
— branch: what branches we need to checkout
— credentialsId: if we use the HTTP method to checkout, we need to specify the credentials to checkout. If it SSH, it’s not required.
— url: the repo URL.
stage("Checkout Code") {
steps {
script {
git branch: "master",
credentialsId: 'my-credentials',
url: 'https://user@github.org/myproject/sample-repo.git'
}
}
}The code will be checked out in the current working directory.
Installing the python packages: to install the python packages, we can use the shell command.
stage('Installing packages') {
steps {
script {
sh 'pip -r requirements.txt'
}
}
}Running Static Code Analysis: We choose Pylint to check the static code analysis and Warnings Next Generation Plugin to analyze the Pylint report. The plugin has features to mark build as unstable or fail based on the scores.
stage('Static Code Checking') {
steps {
script {
sh 'find . -name \*.py | xargs pylint --load-plugins=pylint_django -f parseable | tee pylint.log'
recordIssues(
tool: pyLint(pattern: 'pylint.log'),
failTotalHigh: 10,
)
}
}
}- We used to shell command to run the Pylint for all python files in the project folder.
- recordIssues method of warnings next-generation plugin, and we have specified what kind of log and parameters. The build fails if the High category issues count is more than or equal to 10. there are multiple options available. Please visit https://www.jenkins.io/doc/pipeline/steps/warnings-ng/ for more information on configurations.
Running unit test cases: We can use any test tools like a pytest or nose to run the unit test. To publish the report on Jenkins we choose «CoberturaPublisher» plugin. There is no straight way to use the plugin in the pipeline. We need to invoke its class.
stage('Running Unit tests') {
steps {
script {
sh 'python3.7 manage.py test --keepdb --with-xunit --xunit-file=pyunit.xml --cover-xml --cover-xml-file=cov.xml tests/*.py || true'
step([$class: 'CoberturaPublisher',
coberturaReportFile: "cov.xml",
])
junit "pyunit.xml"
}
}- We need to specify the report file, and it must be «XML» file.
- We also have options to fail the build if tests fail or when the coverage is less. for detailed information available options, please visit. https://www.jenkins.io/doc/pipeline/steps/cobertura/
- To publish the test results we use Junit plugin
The completed pipeline script
pipeline {
agent {
node {
label 'my_local_server'
customWorkspace '/projects/'
}
}
stages {
stage('Checkout project') {
steps {
script {
git branch: "master",
credentialsId: 'my-credentials',
url: 'https://user@github.org/myproject/sample-repo.git'
}
}
}
stage('Installing packages') {
steps {
script {
sh 'pip install -r requirements.txt'
}
}
}
stage('Static Code Checking') {
steps {
script {
sh 'find . -name \*.py | xargs pylint -f parseable | tee pylint.log'
recordIssues(
tool: pyLint(pattern: 'pylint.log'),
unstableTotalHigh: 100,
)
}
}
}
stage('Running Unit tests') {
steps {
script {
sh 'pytest --with-xunit --xunit-file=pyunit.xml --cover-xml --cover-xml-file=cov.xml tests/*.py || true'
step([$class: 'CoberturaPublisher',
coberturaReportFile: "cov.xml",
onlyStable: false,
failNoReports: true,
failUnhealthy: false,
failUnstable: false,
autoUpdateHealth: true,
autoUpdateStability: true,
zoomCoverageChart: true,
maxNumberOfBuilds: 10,
lineCoverageTargets: '80, 80, 80',
conditionalCoverageTargets: '80, 80, 80',
classCoverageTargets: '80, 80, 80',
fileCoverageTargets: '80, 80, 80',
])
junit "pyunit.xml"
}
}
}
}
}gist link: https://gist.github.com/srkama/0600ec839ca675f1a461d7739cb4e404
Another way is creating pipeline and execute sh command, which points to your python script. You also can pass parameters via Jenkins UI as dsaydon mentioned in his answer.
sh command can be as follow (is like you run in command line):
sh 'python.exe myscript.py'
Example pipeline step with creating new virtual environment and run script after installing of all requirements
stage('Running python script'){
sh '''
echo "executing python script"
"'''+python_exec_path+'''" -m venv "'''+venv+'''" && "'''+venv+'''\Scripts\python.exe" -m pip install --upgrade pip && "'''+venv+'''\Scripts\pip" install -r "'''+pathToScript+'''\requirements.txt" && "'''+venv+'''\Scripts\python.exe" "'''+pathToScript+'''\my_script.py" --path "'''+PathFromJenkinsUI+'''"
'''
}
where
sh '''
your command here
'''
means multiline shell command (if you really need it)
You also can pass variables from your pipeline (groovy-script) into sh command and, consequently, to your python script as arguments. Use this way '''+argument_value+''' (with three quotes and plus around variable name)
Example: your python script accepts optional argument path and you want to execute it with specific value which you would like to input in your Jenkins UI. Then your shell-command in groovy script should be as follow:
// getting parameter from UI into `pathValue` variable of pipeline script
// and executing shell command with passed `pathValue` variable into it.
pathValue = getProperty('pathValue')
sh '"\pathTo\python.exe" "my\script.py" --path "'''+pathValue+'''"'

Our Jenkins Pipeline training course is just updated on 2020! – PRESS HERE
Introduction
In the world of Test Automation there are many frameworks available to help testers build their automation infrastructures based on Behavior-driven development (or BDD). We can use Selenium and Cucumber in Java, commit the code in a remote repository and let Jenkins build and run our test project. “Behave” is the framework used in Python language that helps us write test cases in Given-When-Then format and implement the test steps.
When the Python project is run locally, we will end up with a report on which test cases have passed and which test cases have failed. But Python does not use a packaging manager like Maven or a Project Object Model to automatically search for dependencies and download them before the building process starts. Instead, all the packages needed for our Python program to run, have to be installed on the host machine. So, how can we use a Behave project in Jenkins and how can we incorporate it in a Build pipeline?
Server prerequisites
We assume that we already have a simple Python project implemented with the Behave framework, and a Jenkins instance on a server with Ubuntu 18.04. First, we need to make sure that the server can successfully run the project and show us the results of the tests. By updating and upgrading the system on the server, Python v3.6 will be automatically installed. Some development tools that will ensure a robust set-up for our programming environment are build-essential, libssl-dev, libffi-dev and python3-dev. To manage software packages in Python, we will also install pip. The extra packages needed for our project are:
- setuptools, for packaging our project
- selenium, to simulate and automate web browser actions
- behave, the actual BDD framework
The Jenkins instance should also be able to run Python code, so the plugin ShiningPanda is necessary. After installing the plugin we can add Python through the global configuration tool by filling in the path to Python 3 executable, which in the most cases is “/usr/bin/python3”. More information about how to configure the ShiningPanda plugin can be found here https://bit.ly/2F2eqdF
Prepare the Python project
Our Python project will be run on a Linux server with the help of ChromeDriver. Since the server does not have a GUI preinstalled, the project needs to be run in headless mode. Furthermore, there are some other options that we have to add to our driver.py file in the project that instantiates the WebDriver object, to ensure compatibility with the server:
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--start-maximized')
options.add_argument('--disable-extensions')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome("/usr/local/bin/chromedriver", chrome_options=options)
In order to test if the server can run our project with the current configuration, we can upload all project files to a temporary directory and run the following command:
behave -i test.feature --junit
If we see the the logs of the test steps and the results of the test cases on the screen, we are ready to continue.
Configure the Jenkins Freestyle job
There are two kinds of jobs that we can configure in Jenkins. Let’s start with creating a Freestyle job. We need to follow these basic steps in Jenkins:
- Add the repository URL that contains the Python project, to the Source code management section
- Add a Build step, select Virtualenv builder and enter the following commands: pip install behave, pip install selenium
- Add a build step, select Python builder and enter the command: behave -i test.feature –junit
This will enable the ShiningPanda plugin to create a virtual environment with the appropriate Python packages and then run the project with the same command we used earlier. Finally, we can:
- Add a post build action: Publish JUnit test result report and fill in the tests report XML directory as it is configured in the Python project
When we Build the Freestyle job, we will see that a Test Result option is available on the Build details page and from there we can see the report on how many test cases have passed and how many test cases have failed.
Working with a Pipeline
If we do not want a Freestyle job and instead we are only working with Pipelines, we can create a simple Pipeline job in Jenkins, select Pipeline script from Git and enter the Git repository URL of our Python project. In the Script path section we should enter the name of a new file that we will create for configuring the pipeline. We will use the the Jenkinsfile.groovy name, so in our repository we will need to create this file with the following content:
node() {
stage('checkout') {
deleteDir()
checkout scm
}
stage('build') {
sh "behave -i test.feature --junit"
}
stage('publish') {
junit 'reports/*.xml'
}
}
Since the server is already configured with all the required Python packages, the shell command will execute successfully and the Python project will produce the same results as before, visible on the Test Result option on the Build details page.
Conclusion
In this article we examined the case when testers use Python and the Behave framework to build their test automation infrastructure and implement the BDD test cases and test steps. Then, we showed how to configure the Jenkins server with the required packages and implemented a Freestyle job and a Pipeline job in Jenkins, to Build our project and see the test results. This is a good example to show that Jenkins can support different languages and technologies with just a few configuration changes.
![]()
Nyukeit
Posted on Dec 13, 2022
• Updated on Dec 16, 2022
Introduction
In this article, we will look at how we can deploy an app using a CI/CD pipeline involving git, GitHub, Jenkins, Docker and DockerHub. The basic premise is that when a code update is pushed to git, it will get updated on GitHub. Jenkins will then pull this update, build the Docker Image from a Dockerfile and Jenkinsfile configuration, push it to Docker Hub as a registry store, and then pull it and run it as a container to deploy our app.
Prerequisites
- We will use a Python app for this tutorial. The sample app will be included in the GitHub repo.
- GitHub account to sync our local repo and connect with Jenkins.
- Docker Hub account. If you do not already have one, you can create it at hub.docker.com
Installing/Updating Java
First we will check if Java is installed and what version is it.
java -version
Enter fullscreen mode
Exit fullscreen mode

As you can see, it shows Java is not installed.
Since Jenkins will require Java 11, we will go ahead install it using the official documentation of Jenkins.
sudo apt-get install -y openjdk-11-jre
Enter fullscreen mode
Exit fullscreen mode

Once the installation is complete, you can now check and verify the java version again.
java -version
Enter fullscreen mode
Exit fullscreen mode

As we can see, Java is now successfully installed with version 11.0.17.
Now, let’s install Git.
Installing Git
Git will help us in maintaining and versioning our code in an efficient manner.
First let us check if Git is already available in our system or not.
git --version
Enter fullscreen mode
Exit fullscreen mode

As we can see, Git was already installed on the system with the version 2.17.1. If you still do not have it installed, you can install it using this command:
sudo apt-get install -y git
Enter fullscreen mode
Exit fullscreen mode
Configuring Git (Local Repo)
Let’s first create a folder for our project. We will be working inside this folder throughout the tutorial.
mkdir pythonapp
Enter fullscreen mode
Exit fullscreen mode
We will initialize our local Git repository inside this folder.
cd pythonapp
Enter fullscreen mode
Exit fullscreen mode
But before we initialize our local repository, we need to make some changes to the default Git configuration.
git config --global init.defaultBranch main
Enter fullscreen mode
Exit fullscreen mode
By default, Git uses ‘master’ as the default branch. However, GitHub and most developers like to use ‘main’ as the default branch.
Further, we will also configure our name and email ID for Git.
git config --global user.name "your_name"
git config --global user.email "your@email.com"
Enter fullscreen mode
Exit fullscreen mode
To verify your modifications to the Git configuration, you can use this command:
git config --list
Enter fullscreen mode
Exit fullscreen mode

Now it’s time to initialize our local repository.
git init
Enter fullscreen mode
Exit fullscreen mode

This will create an empty repository in the folder. You can also alternatively create a repository on GitHub first and then clone it to your local system.
Setting up GitHub (Remote Repo)
Our local Git repository is not setup and initialized. We will now create a remote repo on GitHub to sync with local.
Login to your GitHub account and click on your Profile picture. Click on ‘Your Repositories’.
On the page that opens, click on the green ‘New’ button.
Let’s name our repo ‘pythonapp’ to keep it same as our folder name. This is not necessary but it will keep things simpler.

Keep the repository as ‘Public’ and click on ‘Create Repository’
Connecting to GitHub
For this tutorial, we will use SSH to connect the local repo to our remote repo. Please note that GitHub has stopped allowing username/password combinations for connections. If you wish to use https instead, you can check out this tutorial to connect using Personal Access Tokens.
First we will create an SSH key in our Ubuntu system.
ssh-keygen
Enter fullscreen mode
Exit fullscreen mode
Press ‘enter’ three times without typing anything.

This will create an SSH key in your system. We will use this key in our GitHub account. To access the key, use this command
cat ~/.ssh/id_rsa.pub
Enter fullscreen mode
Exit fullscreen mode
Copy the entire key.
On GitHub, go to your repository and click on ‘Settings’.
On the left, in the ‘Security’ section, click on ‘Deploy Keys’.

Name the key to whatever you wish. Paste the key that you copied from the terminal inside the ‘Key’ box. Be sure to tick the ‘Allow Write Access’ box.
Now click on ‘Add Key’. We now have access to push to our remote repo using SSH.
Now we will add the remote that will allow us to perform operations to the remote repo.
git remote add origin git@github.com:nyukeit/pythonapp.git
Enter fullscreen mode
Exit fullscreen mode
To verify your remote
git remote
Enter fullscreen mode
Exit fullscreen mode

To verify and connect our configuration, we will do
ssh -T git@github.com
Enter fullscreen mode
Exit fullscreen mode
When prompted, type ‘yes’. You should see a message that says ‘You have successfullly authenticated, but GitHub does not provide shell access.’

Python App
Let’s create Python app that will display Hello World! in the browser when executed.
Inside your terminal, make sure you are in the project folder. Create a folder named ‘src’ and create a file name ‘helloworld.py’ inside this folder like this:
mkdir src
cd src
Enter fullscreen mode
Exit fullscreen mode
sudo nano helloworld.py
Enter fullscreen mode
Exit fullscreen mode
Now let’s write a Python script! Inside the nano editor, type this:
from flask import Flask, request
from flask_restful import Resource, Api
app = Flask(__name__)
api = Api(app)
class Greeting (Resource):
def get(self):
return 'Hello World!'
api.add_resource(Greeting, '/') # Route_1
if __name__ == '__main__':
app.run('0.0.0.0','3333')
Enter fullscreen mode
Exit fullscreen mode
Press ctrl + x + y to save the file.
Head over to Part 2 where we will go through the installation & configuration of Jenkins, Docker and creating the scripts to finish our pipeline.